 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervision & Meta-Learning for One-Shot Unsupervised Cross-Domain Detection
Jun 07, 2021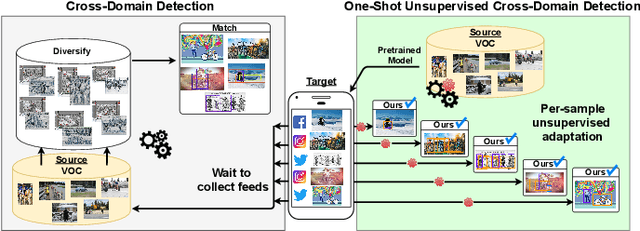
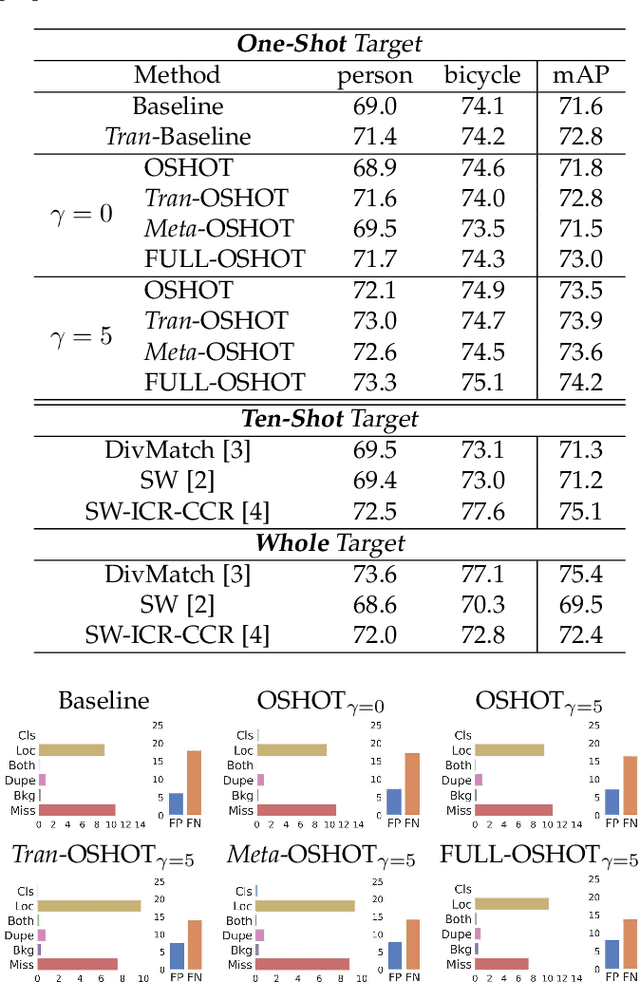
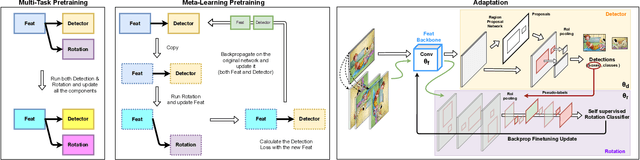
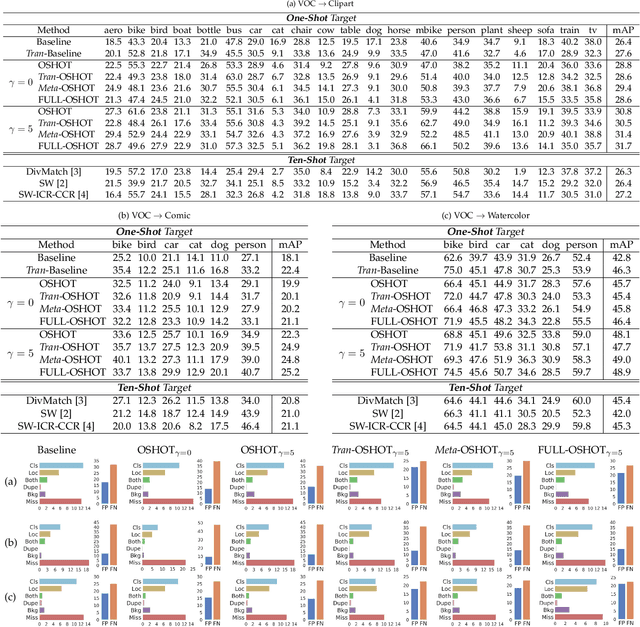
Deep detection models have largely demonstrated to be extremely powerful in controlled settings, but appear brittle and fail when applied off-the-shelf on unseen domains. All the adaptive approaches developed to amend this issue access a sizable amount of target samples at training time, a strategy not suitable when the target is unknown and its data are not available in advance. Consider for instance the task of monitoring image feeds from social media: as every image is uploaded by a different user it belongs to a different target domain that is impossible to foresee during training. Our work addresses this setting, presenting an object detection algorithm able to perform unsupervised adaptation across domains by using only one target sample, seen at test time. We introduce a multi-task architecture that one-shot adapts to any incoming sample by iteratively solving a self-supervised task on it. We further exploit meta-learning to simulate single-sample cross domain learning episodes and better align to the test condition. Moreover, a cross-task pseudo-labeling procedure allows to focus on the image foreground and enhances the adaptation process. A thorough benchmark analysis against the most recent cross-domain detection methods and a detailed ablation study show the advantage of our approach.
(DE)^2 CO: Deep Depth Colorization
Feb 21, 2018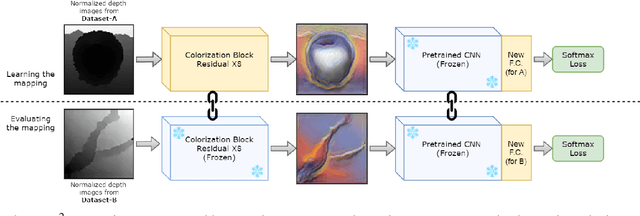
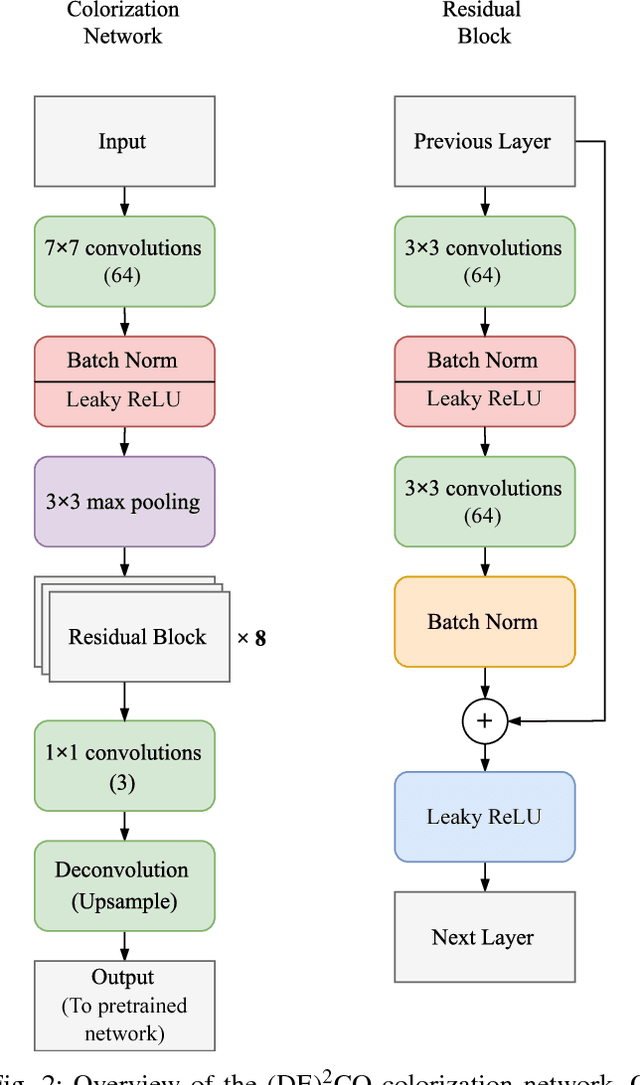
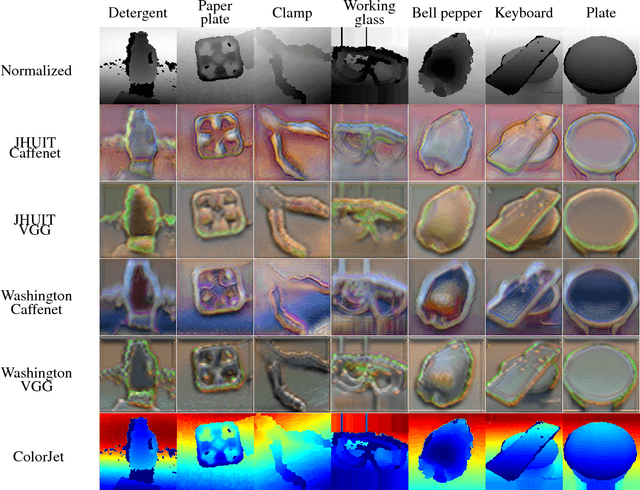
The ability to classify objects is fundamental for robots. Besides knowledge about their visual appearance, captured by the RGB channel, robots heavily need also depth information to make sense of the world. While the use of deep networks on RGB robot images has benefited from the plethora of results obtained on databases like ImageNet, using convnets on depth images requires mapping them into three dimensional channels. This transfer learning procedure makes them processable by pre-trained deep architectures. Current mappings are based on heuristic assumptions over preprocessing steps and on what depth properties should be most preserved, resulting often in cumbersome data visualizations, and in sub-optimal performance in terms of generality and recognition results. Here we take an alternative route and we attempt instead to learn an optimal colorization mapping for any given pre-trained architecture, using as training data a reference RGB-D database. We propose a deep network architecture, exploiting the residual paradigm, that learns how to map depth data to three channel images. A qualitative analysis of the images obtained with this approach clearly indicates that learning the optimal mapping preserves the richness of depth information better than current hand-crafted approaches. Experiments on the Washington, JHUIT-50 and BigBIRD public benchmark databases, using CaffeNet, VGG16, GoogleNet, and ResNet50 clearly showcase the power of our approach, with gains in performance of up to 16% compared to state of the art competitors on the depth channel only, leading to top performances when dealing with RGB-D data