 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning novel representations of variable sources from multi-modal $\textit{Gaia}$ data via autoencoders
May 22, 2025



Gaia Data Release 3 (DR3) published for the first time epoch photometry, BP/RP (XP) low-resolution mean spectra, and supervised classification results for millions of variable sources. This extensive dataset offers a unique opportunity to study their variability by combining multiple Gaia data products. In preparation for DR4, we propose and evaluate a machine learning methodology capable of ingesting multiple Gaia data products to achieve an unsupervised classification of stellar and quasar variability. A dataset of 4 million Gaia DR3 sources is used to train three variational autoencoders (VAE), which are artificial neural networks (ANNs) designed for data compression and generation. One VAE is trained on Gaia XP low-resolution spectra, another on a novel approach based on the distribution of magnitude differences in the Gaia G band, and the third on folded Gaia G band light curves. Each Gaia source is compressed into 15 numbers, representing the coordinates in a 15-dimensional latent space generated by combining the outputs of these three models. The learned latent representation produced by the ANN effectively distinguishes between the main variability classes present in Gaia DR3, as demonstrated through both supervised and unsupervised classification analysis of the latent space. The results highlight a strong synergy between light curves and low-resolution spectral data, emphasising the benefits of combining the different Gaia data products. A two-dimensional projection of the latent variables reveals numerous overdensities, most of which strongly correlate with astrophysical properties, showing the potential of this latent space for astrophysical discovery. We show that the properties of our novel latent representation make it highly valuable for variability analysis tasks, including classification, clustering and outlier detection.
Informative Bayesian model selection for RR Lyrae star classifiers
May 24, 2021
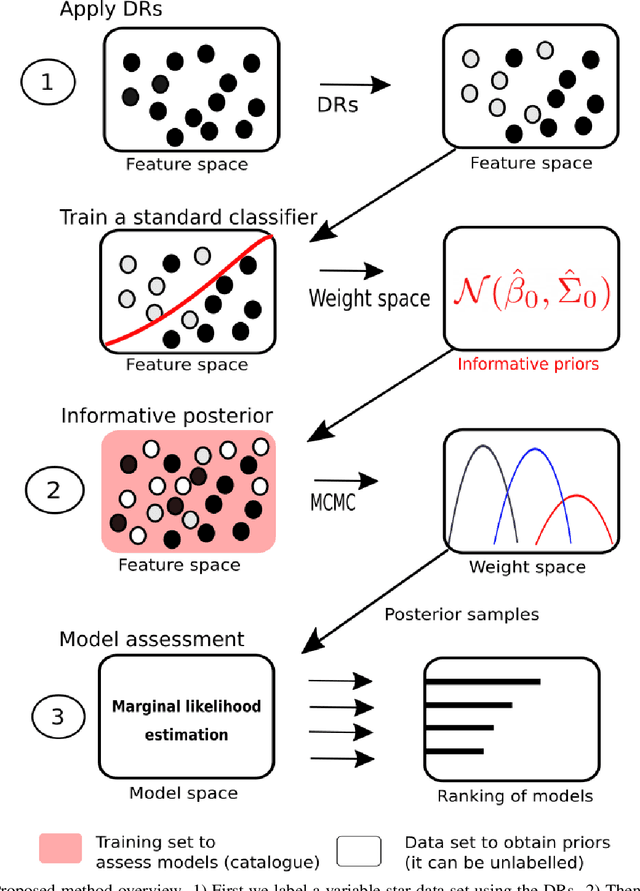


Machine learning has achieved an important role in the automatic classification of variable stars, and several classifiers have been proposed over the last decade. These classifiers have achieved impressive performance in several astronomical catalogues. However, some scientific articles have also shown that the training data therein contain multiple sources of bias. Hence, the performance of those classifiers on objects not belonging to the training data is uncertain, potentially resulting in the selection of incorrect models. Besides, it gives rise to the deployment of misleading classifiers. An example of the latter is the creation of open-source labelled catalogues with biased predictions. In this paper, we develop a method based on an informative marginal likelihood to evaluate variable star classifiers. We collect deterministic rules that are based on physical descriptors of RR Lyrae stars, and then, to mitigate the biases, we introduce those rules into the marginal likelihood estimation. We perform experiments with a set of Bayesian Logistic Regressions, which are trained to classify RR Lyraes, and we found that our method outperforms traditional non-informative cross-validation strategies, even when penalized models are assessed. Our methodology provides a more rigorous alternative to assess machine learning models using astronomical knowledge. From this approach, applications to other classes of variable stars and algorithmic improvements can be developed.