 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Many Topics? Stability Analysis for Topic Models
Jun 19, 2014


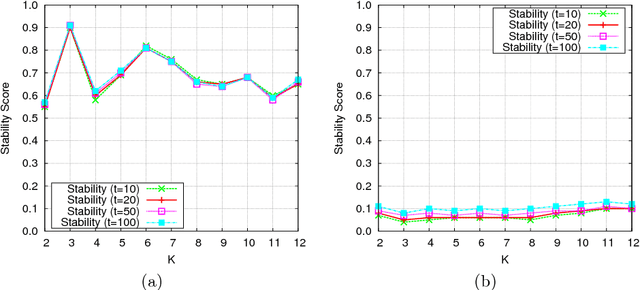
Topic modeling refers to the task of discovering the underlying thematic structure in a text corpus, where the output is commonly presented as a report of the top terms appearing in each topic. Despite the diversity of topic modeling algorithms that have been proposed, a common challenge in successfully applying these techniques is the selection of an appropriate number of topics for a given corpus. Choosing too few topics will produce results that are overly broad, while choosing too many will result in the "over-clustering" of a corpus into many small, highly-similar topics. In this paper, we propose a term-centric stability analysis strategy to address this issue, the idea being that a model with an appropriate number of topics will be more robust to perturbations in the data. Using a topic modeling approach based on matrix factorization, evaluations performed on a range of corpora show that this strategy can successfully guide the model selection process.
Link Prediction with Social Vector Clocks
Apr 15, 2013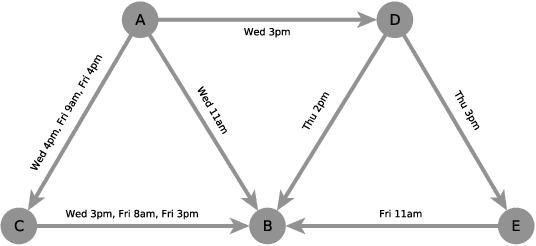
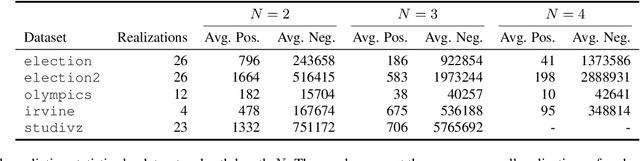
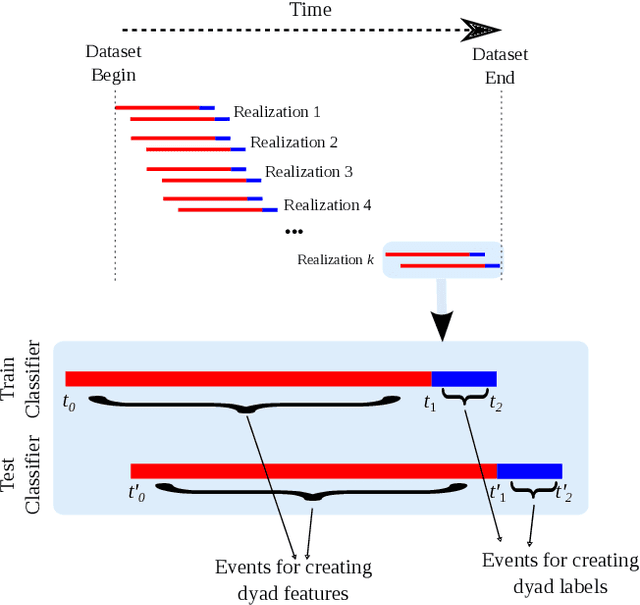
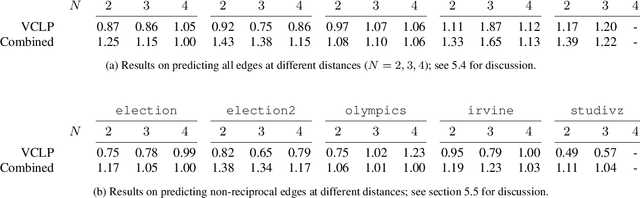
State-of-the-art link prediction utilizes combinations of complex features derived from network panel data. We here show that computationally less expensive features can achieve the same performance in the common scenario in which the data is available as a sequence of interactions. Our features are based on social vector clocks, an adaptation of the vector-clock concept introduced in distributed computing to social interaction networks. In fact, our experiments suggest that by taking into account the order and spacing of interactions, social vector clocks exploit different aspects of link formation so that their combination with previous approaches yields the most accurate predictor to date.
Aggregating Content and Network Information to Curate Twitter User Lists
Jul 02, 2012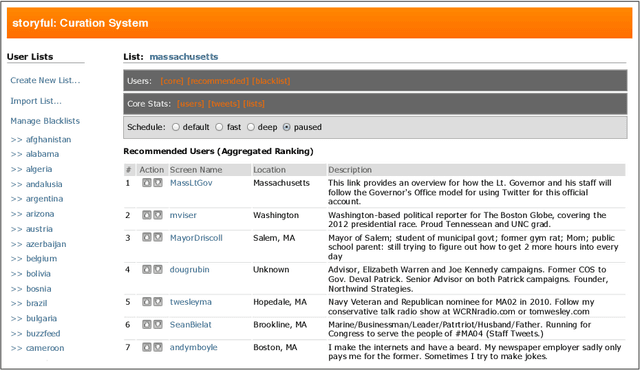
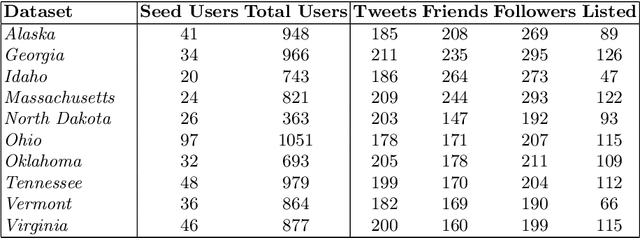
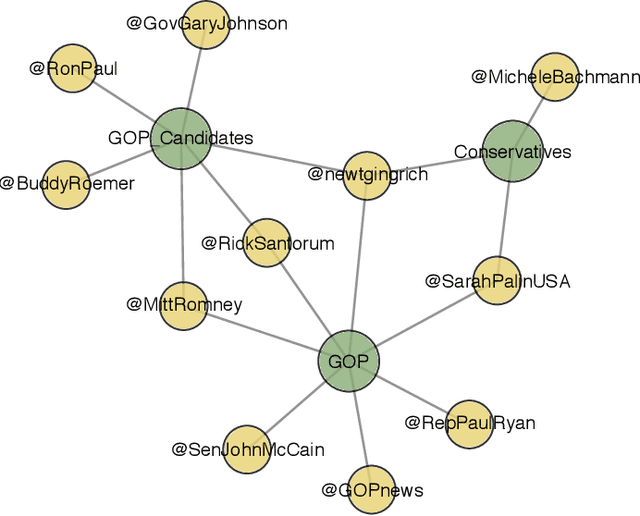
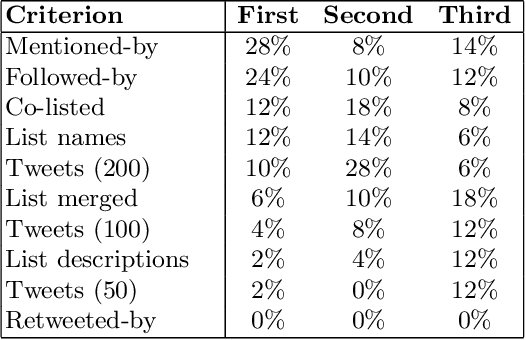
Twitter introduced user lists in late 2009, allowing users to be grouped according to meaningful topics or themes. Lists have since been adopted by media outlets as a means of organising content around news stories. Thus the curation of these lists is important - they should contain the key information gatekeepers and present a balanced perspective on a story. Here we address this list curation process from a recommender systems perspective. We propose a variety of criteria for generating user list recommendations, based on content analysis, network analysis, and the "crowdsourcing" of existing user lists. We demonstrate that these types of criteria are often only successful for datasets with certain characteristics. To resolve this issue, we propose the aggregation of these different "views" of a news story on Twitter to produce more accurate user recommendations to support the curation process.