 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient With Serial Markov Chain Reasoning
Oct 13, 2022
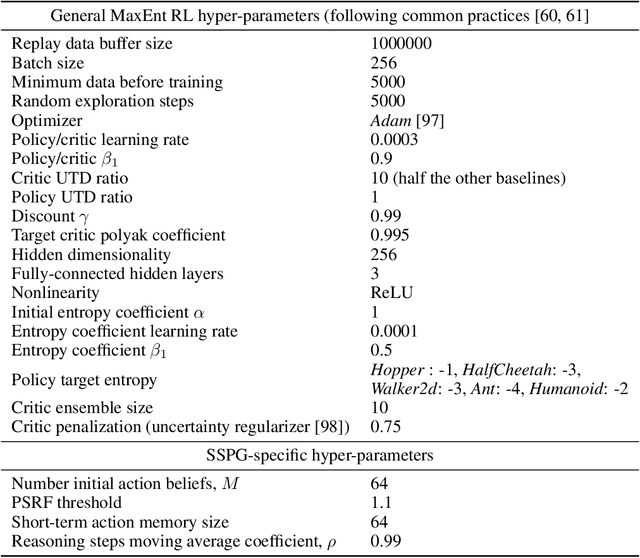
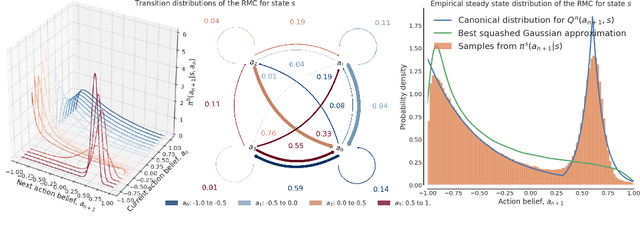
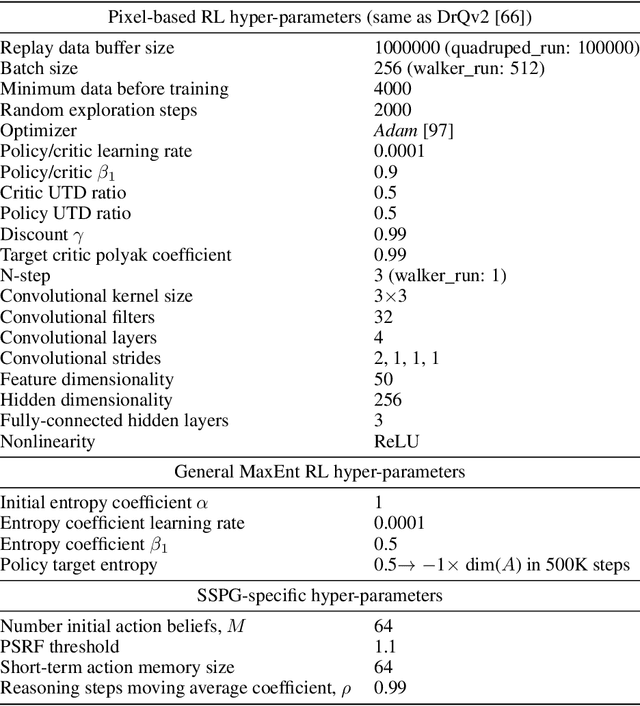
We introduce a new framework that performs decision-making in reinforcement learning (RL) as an iterative reasoning process. We model agent behavior as the steady-state distribution of a parameterized reasoning Markov chain (RMC), optimized with a new tractable estimate of the policy gradient. We perform action selection by simulating the RMC for enough reasoning steps to approach its steady-state distribution. We show our framework has several useful properties that are inherently missing from traditional RL. For instance, it allows agent behavior to approximate any continuous distribution over actions by parameterizing the RMC with a simple Gaussian transition function. Moreover, the number of reasoning steps to reach convergence can scale adaptively with the difficulty of each action selection decision and can be accelerated by re-using past solutions. Our resulting algorithm achieves state-of-the-art performance in popular Mujoco and DeepMind Control benchmarks, both for proprioceptive and pixel-based tasks.
Automatic Context-Driven Inference of Engagement in HMI: A Survey
Sep 30, 2022
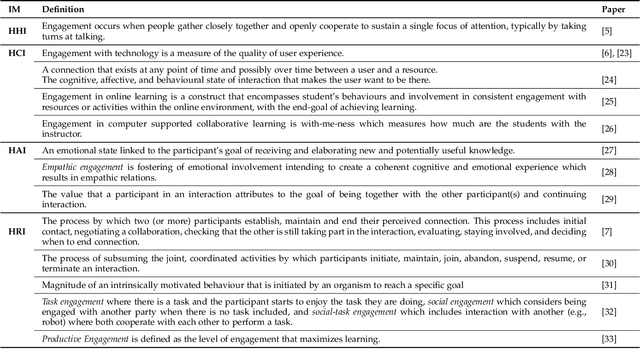
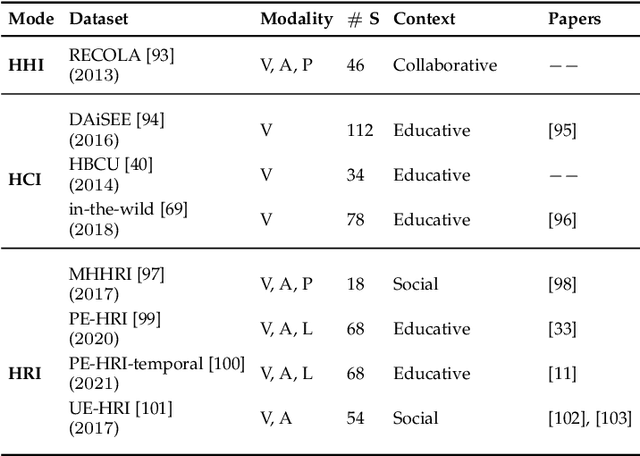
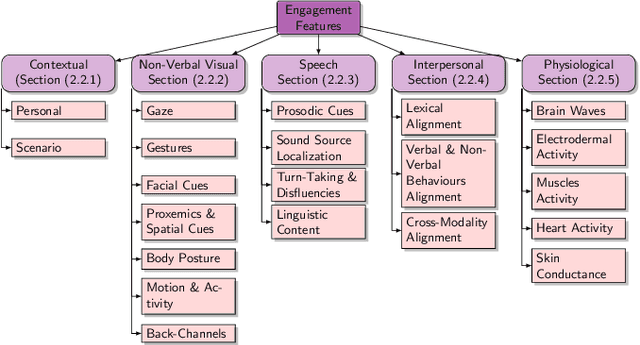
An integral part of seamless human-human communication is engagement, the process by which two or more participants establish, maintain, and end their perceived connection. Therefore, to develop successful human-centered human-machine interaction applications, automatic engagement inference is one of the tasks required to achieve engaging interactions between humans and machines, and to make machines attuned to their users, hence enhancing user satisfaction and technology acceptance. Several factors contribute to engagement state inference, which include the interaction context and interactants' behaviours and identity. Indeed, engagement is a multi-faceted and multi-modal construct that requires high accuracy in the analysis and interpretation of contextual, verbal and non-verbal cues. Thus, the development of an automated and intelligent system that accomplishes this task has been proven to be challenging so far. This paper presents a comprehensive survey on previous work in engagement inference for human-machine interaction, entailing interdisciplinary definition, engagement components and factors, publicly available datasets, ground truth assessment, and most commonly used features and methods, serving as a guide for the development of future human-machine interaction interfaces with reliable context-aware engagement inference capability. An in-depth review across embodied and disembodied interaction modes, and an emphasis on the interaction context of which engagement perception modules are integrated sets apart the presented survey from existing surveys.
Stabilizing Off-Policy Deep Reinforcement Learning from Pixels
Jul 03, 2022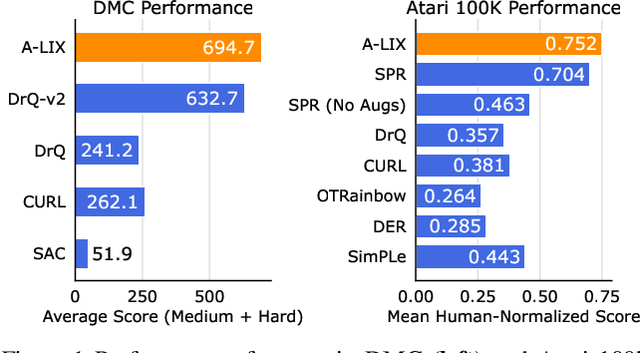

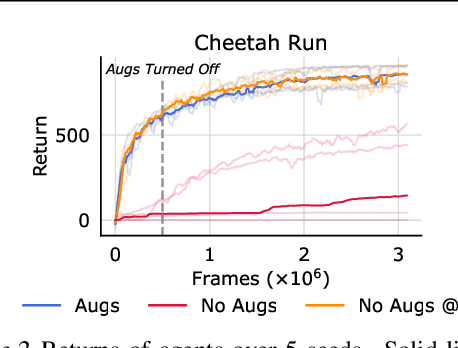
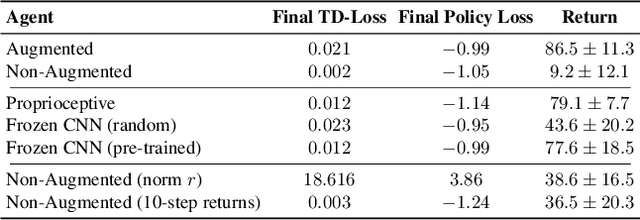
Off-policy reinforcement learning (RL) from pixel observations is notoriously unstable. As a result, many successful algorithms must combine different domain-specific practices and auxiliary losses to learn meaningful behaviors in complex environments. In this work, we provide novel analysis demonstrating that these instabilities arise from performing temporal-difference learning with a convolutional encoder and low-magnitude rewards. We show that this new visual deadly triad causes unstable training and premature convergence to degenerate solutions, a phenomenon we name catastrophic self-overfitting. Based on our analysis, we propose A-LIX, a method providing adaptive regularization to the encoder's gradients that explicitly prevents the occurrence of catastrophic self-overfitting using a dual objective. By applying A-LIX, we significantly outperform the prior state-of-the-art on the DeepMind Control and Atari 100k benchmarks without any data augmentation or auxiliary losses.
GROWL: Group Detection With Link Prediction
Nov 08, 2021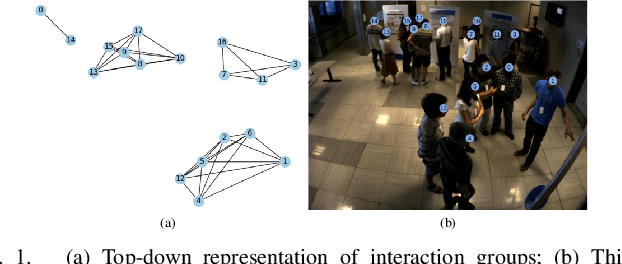
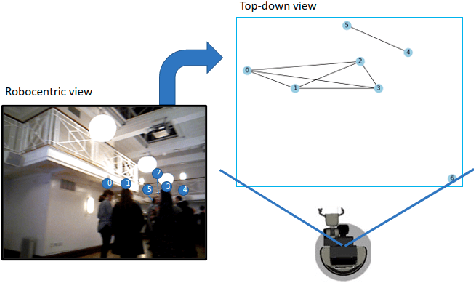
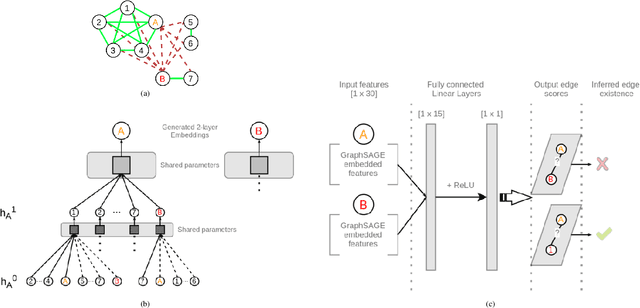
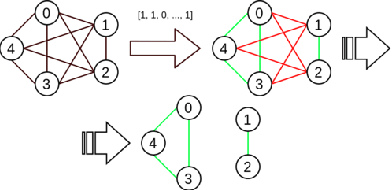
Interaction group detection has been previously addressed with bottom-up approaches which relied on the position and orientation information of individuals. These approaches were primarily based on pairwise affinity matrices and were limited to static, third-person views. This problem can greatly benefit from a holistic approach based on Graph Neural Networks (GNNs) beyond pairwise relationships, due to the inherent spatial configuration that exists between individuals who form interaction groups. Our proposed method, GROup detection With Link prediction (GROWL), demonstrates the effectiveness of a GNN based approach. GROWL predicts the link between two individuals by generating a feature embedding based on their neighbourhood in the graph and determines whether they are connected with a shallow binary classification method such as Multi-layer Perceptrons (MLPs). We test our method against other state-of-the-art group detection approaches on both a third-person view dataset and a robocentric (i.e., egocentric) dataset. In addition, we propose a multimodal approach based on RGB and depth data to calculate a representation GROWL can utilise as input. Our results show that a GNN based approach can significantly improve accuracy across different camera views, i.e., third-person and egocentric views.
Forecasting Nonverbal Social Signals during Dyadic Interactions with Generative Adversarial Neural Networks
Oct 18, 2021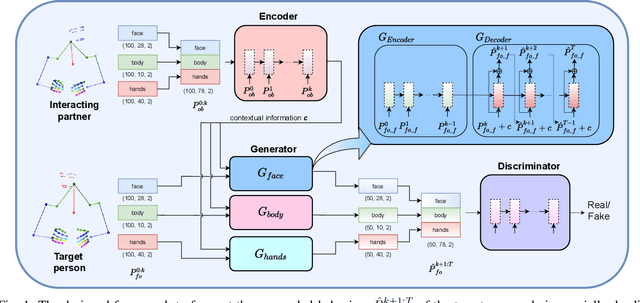

We are approaching a future where social robots will progressively become widespread in many aspects of our daily lives, including education, healthcare, work, and personal use. All of such practical applications require that humans and robots collaborate in human environments, where social interaction is unavoidable. Along with verbal communication, successful social interaction is closely coupled with the interplay between nonverbal perception and action mechanisms, such as observation of gaze behaviour and following their attention, coordinating the form and function of hand gestures. Humans perform nonverbal communication in an instinctive and adaptive manner, with no effort. For robots to be successful in our social landscape, they should therefore engage in social interactions in a humanlike way, with increasing levels of autonomy. In particular, nonverbal gestures are expected to endow social robots with the capability of emphasizing their speech, or showing their intentions. Motivated by this, our research sheds a light on modeling human behaviors in social interactions, specifically, forecasting human nonverbal social signals during dyadic interactions, with an overarching goal of developing robotic interfaces that can learn to imitate human dyadic interactions. Such an approach will ensure the messages encoded in the robot gestures could be perceived by interacting partners in a facile and transparent manner, which could help improve the interacting partner perception and makes the social interaction outcomes enhanced.
Learning Pessimism for Robust and Efficient Off-Policy Reinforcement Learning
Oct 07, 2021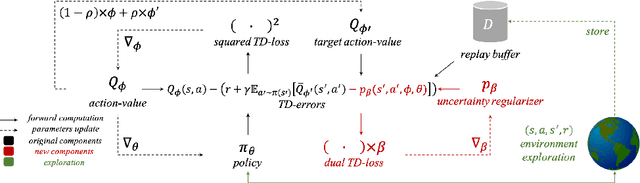
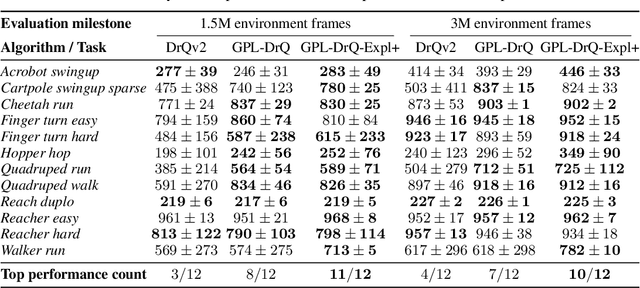
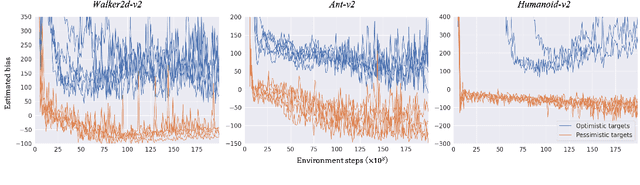
Popular off-policy deep reinforcement learning algorithms compensate for overestimation bias during temporal-difference learning by utilizing pessimistic estimates of the expected target returns. In this work, we propose a novel learnable penalty to enact such pessimism, based on a new way to quantify the critic's epistemic uncertainty. Furthermore, we propose to learn the penalty alongside the critic with dual TD-learning, a strategy to estimate and minimize the bias magnitude in the target returns. Our method enables us to accurately counteract overestimation bias throughout training without incurring the downsides of overly pessimistic targets. Empirically, by integrating our method and other orthogonal improvements with popular off-policy algorithms, we achieve state-of-the-art results in continuous control tasks from both proprioceptive and pixel observations.
Learning Routines for Effective Off-Policy Reinforcement Learning
Jun 05, 2021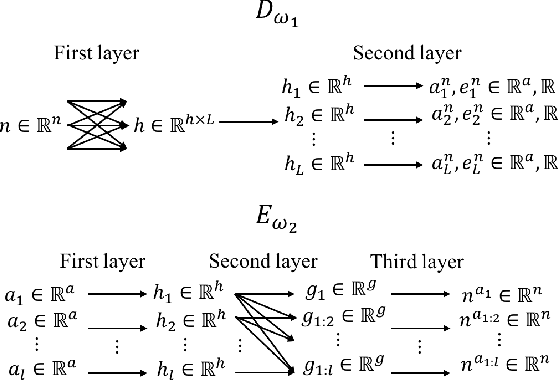
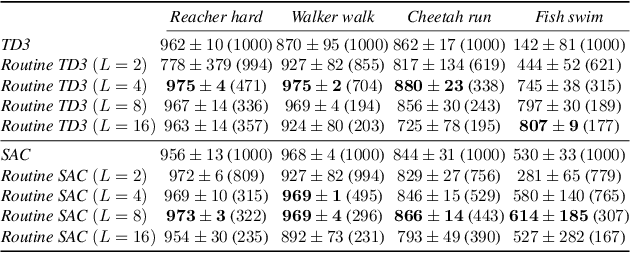
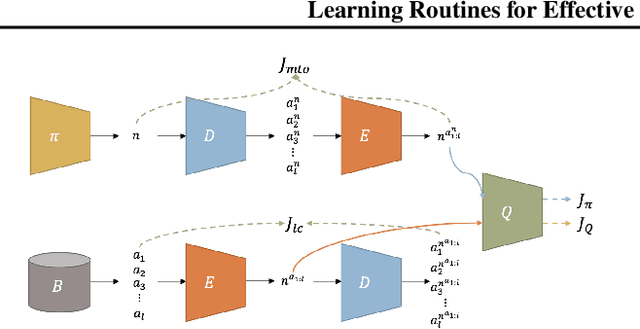
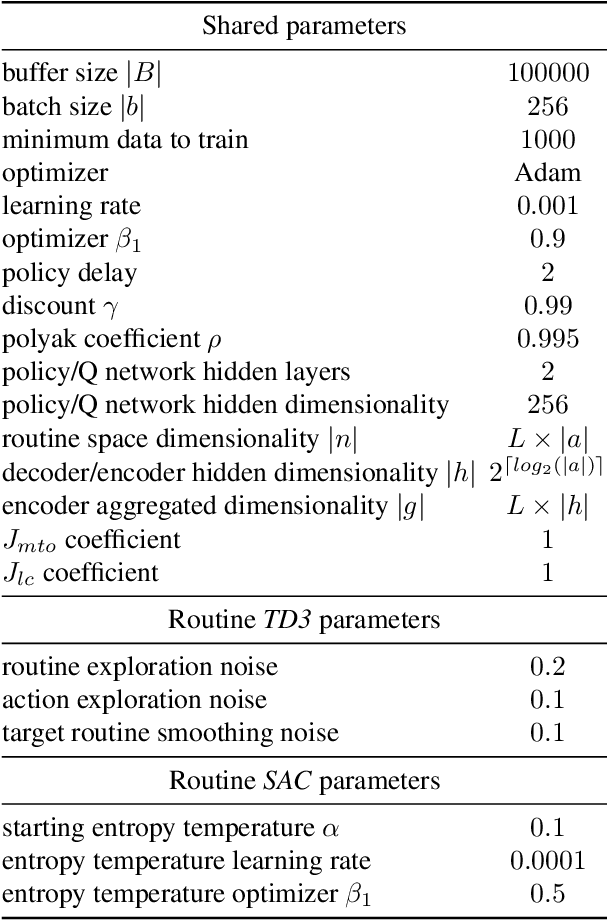
The performance of reinforcement learning depends upon designing an appropriate action space, where the effect of each action is measurable, yet, granular enough to permit flexible behavior. So far, this process involved non-trivial user choices in terms of the available actions and their execution frequency. We propose a novel framework for reinforcement learning that effectively lifts such constraints. Within our framework, agents learn effective behavior over a routine space: a new, higher-level action space, where each routine represents a set of 'equivalent' sequences of granular actions with arbitrary length. Our routine space is learned end-to-end to facilitate the accomplishment of underlying off-policy reinforcement learning objectives. We apply our framework to two state-of-the-art off-policy algorithms and show that the resulting agents obtain relevant performance improvements while requiring fewer interactions with the environment per episode, improving computational efficiency.
IB-DRR: Incremental Learning with Information-Back Discrete Representation Replay
Apr 21, 2021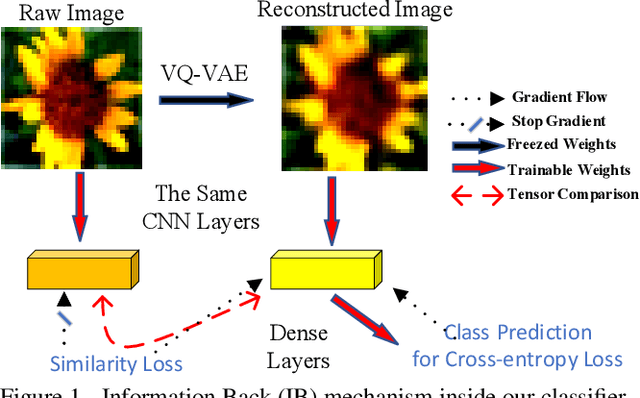
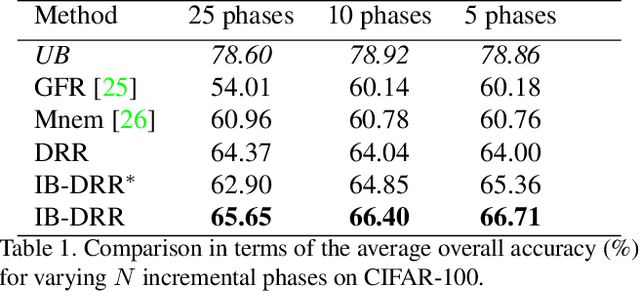
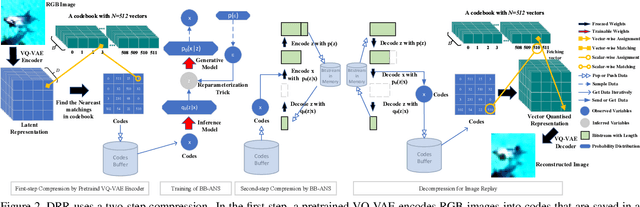
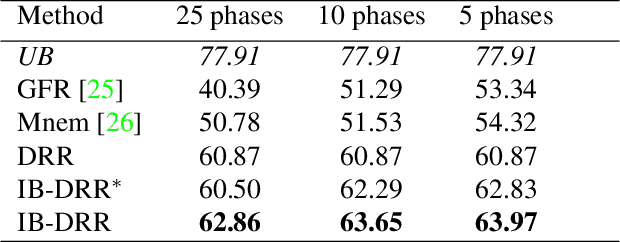
Incremental learning aims to enable machine learning models to continuously acquire new knowledge given new classes, while maintaining the knowledge already learned for old classes. Saving a subset of training samples of previously seen classes in the memory and replaying them during new training phases is proven to be an efficient and effective way to fulfil this aim. It is evident that the larger number of exemplars the model inherits the better performance it can achieve. However, finding a trade-off between the model performance and the number of samples to save for each class is still an open problem for replay-based incremental learning and is increasingly desirable for real-life applications. In this paper, we approach this open problem by tapping into a two-step compression approach. The first step is a lossy compression, we propose to encode input images and save their discrete latent representations in the form of codes that are learned using a hierarchical Vector Quantised Variational Autoencoder (VQ-VAE). In the second step, we further compress codes losslessly by learning a hierarchical latent variable model with bits-back asymmetric numeral systems (BB-ANS). To compensate for the information lost in the first step compression, we introduce an Information Back (IB) mechanism that utilizes real exemplars for a contrastive learning loss to regularize the training of a classifier. By maintaining all seen exemplars' representations in the format of `codes', Discrete Representation Replay (DRR) outperforms the state-of-art method on CIFAR-100 by a margin of 4% accuracy with a much less memory cost required for saving samples. Incorporated with IB and saving a small set of old raw exemplars as well, the accuracy of DRR can be further improved by 2% accuracy.
Domain-Robust Visual Imitation Learning with Mutual Information Constraints
Mar 08, 2021

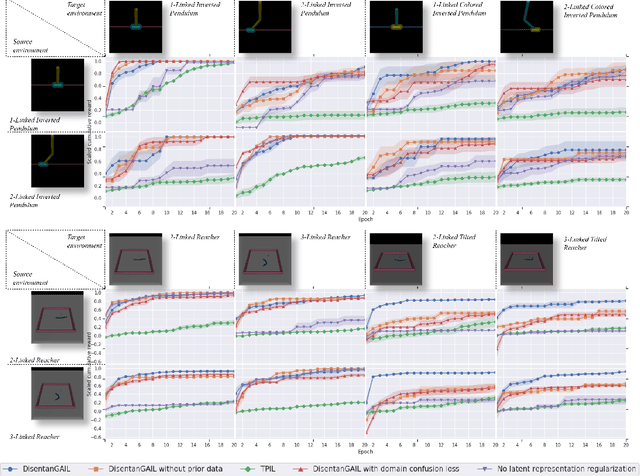
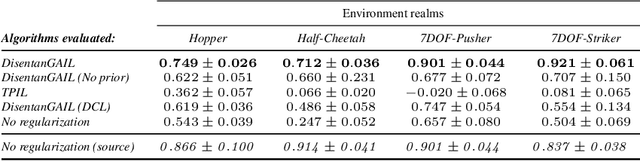
Human beings are able to understand objectives and learn by simply observing others perform a task. Imitation learning methods aim to replicate such capabilities, however, they generally depend on access to a full set of optimal states and actions taken with the agent's actuators and from the agent's point of view. In this paper, we introduce a new algorithm - called Disentangling Generative Adversarial Imitation Learning (DisentanGAIL) - with the purpose of bypassing such constraints. Our algorithm enables autonomous agents to learn directly from high dimensional observations of an expert performing a task, by making use of adversarial learning with a latent representation inside the discriminator network. Such latent representation is regularized through mutual information constraints to incentivize learning only features that encode information about the completion levels of the task being demonstrated. This allows to obtain a shared feature space to successfully perform imitation while disregarding the differences between the expert's and the agent's domains. Empirically, our algorithm is able to efficiently imitate in a diverse range of control problems including balancing, manipulation and locomotive tasks, while being robust to various domain differences in terms of both environment appearance and agent embodiment.
Activity recognition from videos with parallel hypergraph matching on GPUs
May 04, 2015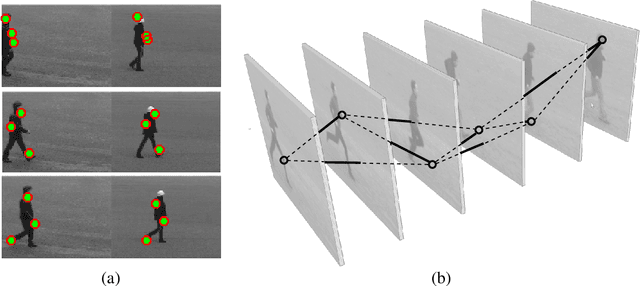
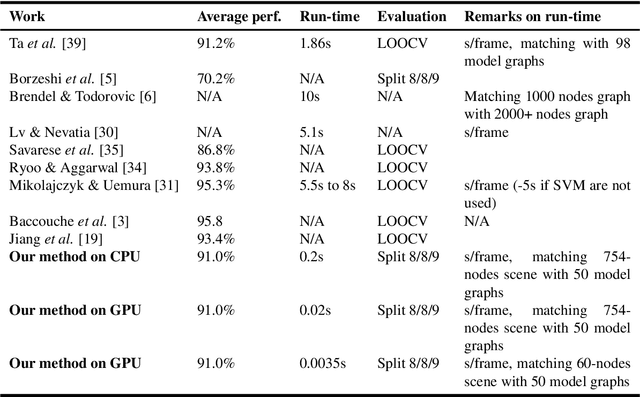
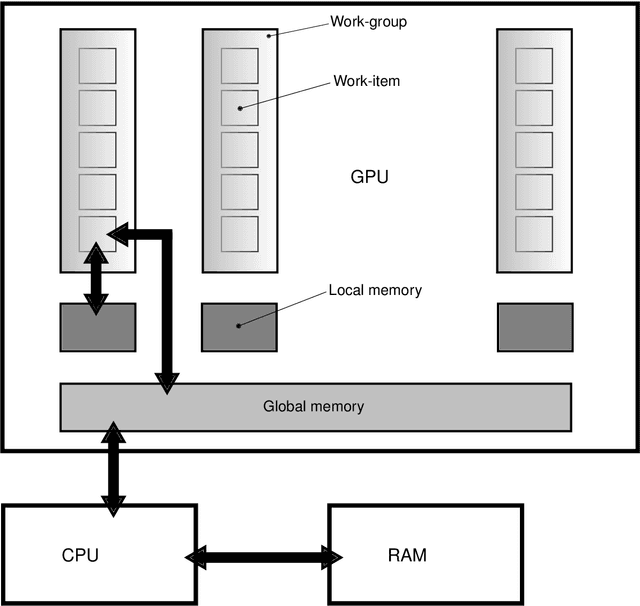
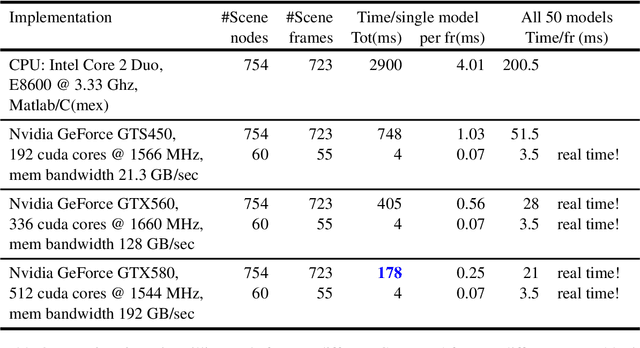
In this paper, we propose a method for activity recognition from videos based on sparse local features and hypergraph matching. We benefit from special properties of the temporal domain in the data to derive a sequential and fast graph matching algorithm for GPUs. Traditionally, graphs and hypergraphs are frequently used to recognize complex and often non-rigid patterns in computer vision, either through graph matching or point-set matching with graphs. Most formulations resort to the minimization of a difficult discrete energy function mixing geometric or structural terms with data attached terms involving appearance features. Traditional methods solve this minimization problem approximately, for instance with spectral techniques. In this work, instead of solving the problem approximatively, the exact solution for the optimal assignment is calculated in parallel on GPUs. The graphical structure is simplified and regularized, which allows to derive an efficient recursive minimization algorithm. The algorithm distributes subproblems over the calculation units of a GPU, which solves them in parallel, allowing the system to run faster than real-time on medium-end GPUs.