 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFREDA: Flexible Relation Extraction Data Annotation
Apr 14, 2022
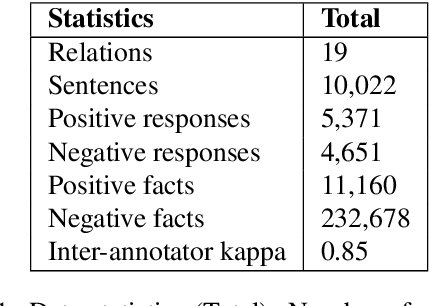
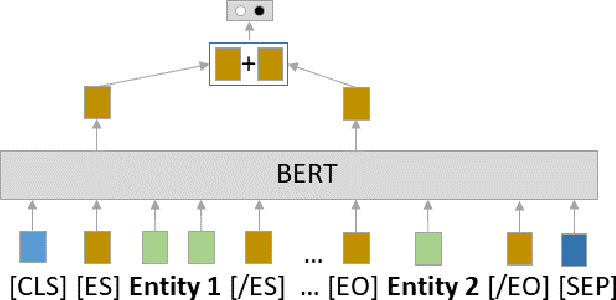
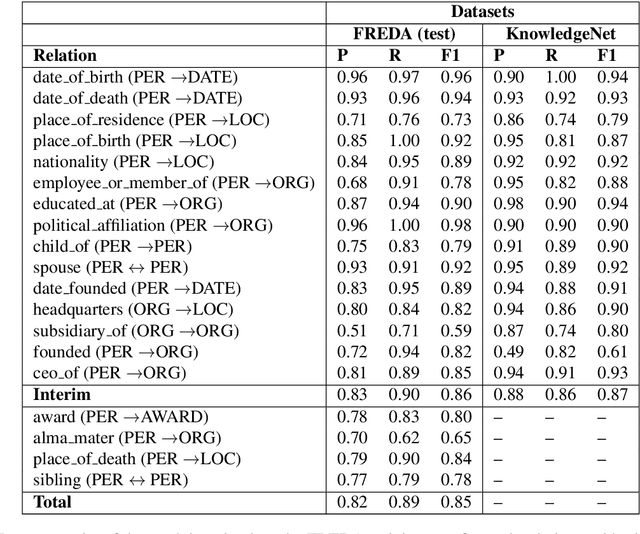
To effectively train accurate Relation Extraction models, sufficient and properly labeled data is required. Adequately labeled data is difficult to obtain and annotating such data is a tricky undertaking. Previous works have shown that either accuracy has to be sacrificed or the task is extremely time-consuming, if done accurately. We are proposing an approach in order to produce high-quality datasets for the task of Relation Extraction quickly. Neural models, trained to do Relation Extraction on the created datasets, achieve very good results and generalize well to other datasets. In our study, we were able to annotate 10,022 sentences for 19 relations in a reasonable amount of time, and trained a commonly used baseline model for each relation.
A comprehensive empirical analysis on cross-domain semantic enrichment for detection of depressive language
Jun 24, 2021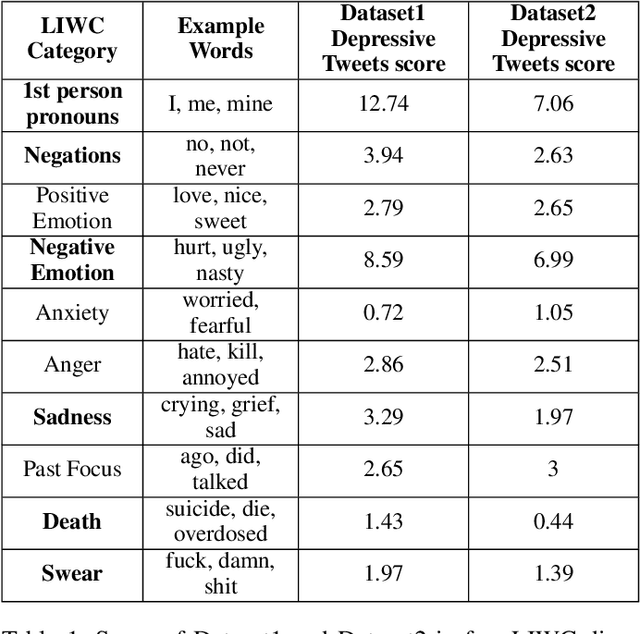
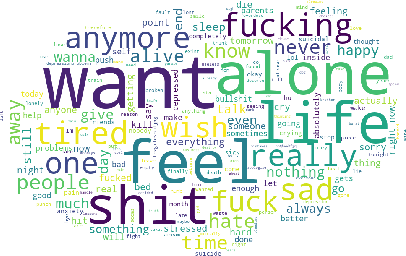
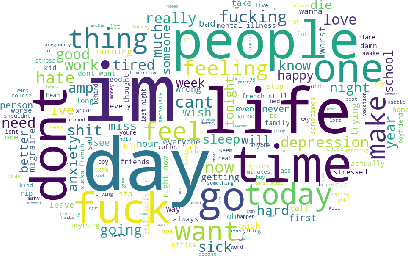

We analyze the process of creating word embedding feature representations designed for a learning task when annotated data is scarce, for example, in depressive language detection from Tweets. We start with a rich word embedding pre-trained from a large general dataset, which is then augmented with embeddings learned from a much smaller and more specific domain dataset through a simple non-linear mapping mechanism. We also experimented with several other more sophisticated methods of such mapping including, several auto-encoder based and custom loss-function based methods that learn embedding representations through gradually learning to be close to the words of similar semantics and distant to dissimilar semantics. Our strengthened representations better capture the semantics of the depression domain, as it combines the semantics learned from the specific domain coupled with word coverage from the general language. We also present a comparative performance analyses of our word embedding representations with a simple bag-of-words model, well known sentiment and psycholinguistic lexicons, and a general pre-trained word embedding. When used as feature representations for several different machine learning methods, including deep learning models in a depressive Tweets identification task, we show that our augmented word embedding representations achieve a significantly better F1 score than the others, specially when applied to a high quality dataset. Also, we present several data ablation tests which confirm the efficacy of our augmentation techniques.
STEP-EZ: Syntax Tree guided semantic ExPlanation for Explainable Zero-shot modeling of clinical depression symptoms from text
Jun 23, 2021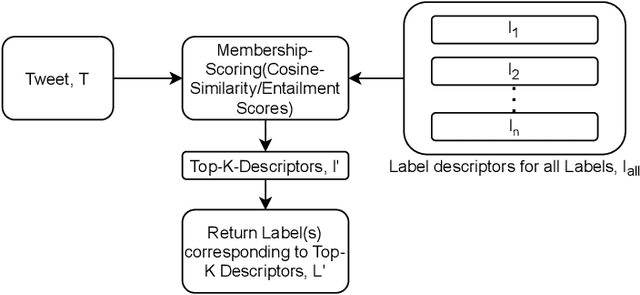
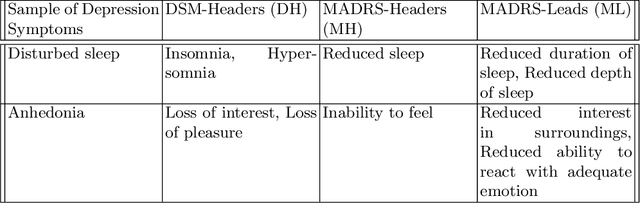
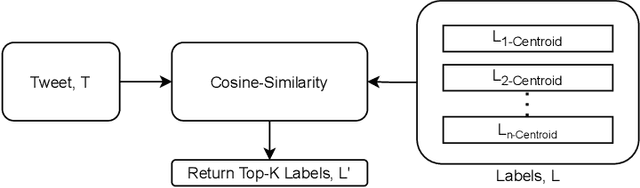

We focus on exploring various approaches of Zero-Shot Learning (ZSL) and their explainability for a challenging yet important supervised learning task notorious for training data scarcity, i.e. Depression Symptoms Detection (DSD) from text. We start with a comprehensive synthesis of different components of our ZSL modeling and analysis of our ground truth samples and Depression symptom clues curation process with the help of a practicing clinician. We next analyze the accuracy of various state-of-the-art ZSL models and their potential enhancements for our task. Further, we sketch a framework for the use of ZSL for hierarchical text-based explanation mechanism, which we call, Syntax Tree-Guided Semantic Explanation (STEP). Finally, we summarize experiments from which we conclude that we can use ZSL models and achieve reasonable accuracy and explainability, measured by a proposed Explainability Index (EI). This work is, to our knowledge, the first work to exhaustively explore the efficacy of ZSL models for DSD task, both in terms of accuracy and explainability.
Basic and Depression Specific Emotion Identification in Tweets: Multi-label Classification Experiments
May 26, 2021
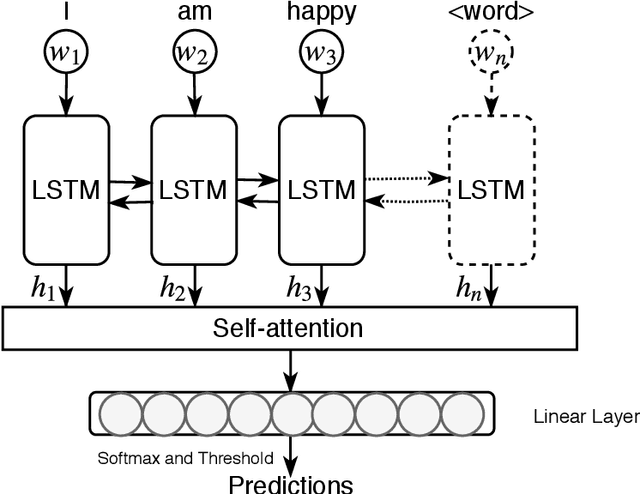

In this paper, we present empirical analysis on basic and depression specific multi-emotion mining in Tweets with the help of state of the art multi-label classifiers. We choose our basic emotions from a hybrid emotion model consisting of the common emotions from four highly regarded psychological models of emotions. Moreover, we augment that emotion model with new emotion categories because of their importance in the analysis of depression. Most of those additional emotions have not been used in previous emotion mining research. Our experimental analyses show that a cost sensitive RankSVM algorithm and a Deep Learning model are both robust, measured by both Macro F-measures and Micro F-measures. This suggests that these algorithms are superior in addressing the widely known data imbalance problem in multi-label learning. Moreover, our application of Deep Learning performs the best, giving it an edge in modeling deep semantic features of our extended emotional categories.
Neural Path Hunter: Reducing Hallucination in Dialogue Systems via Path Grounding
Apr 17, 2021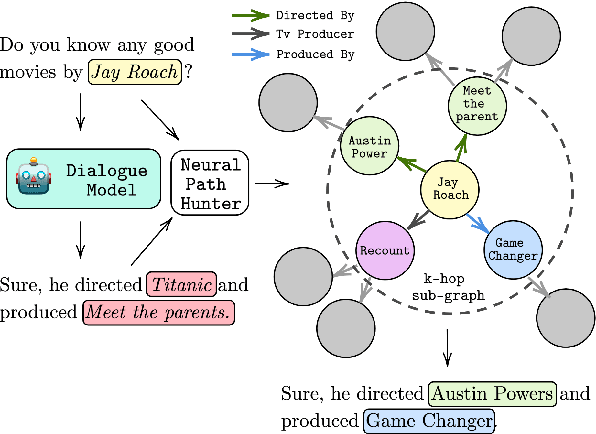
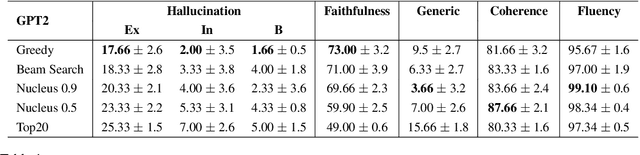
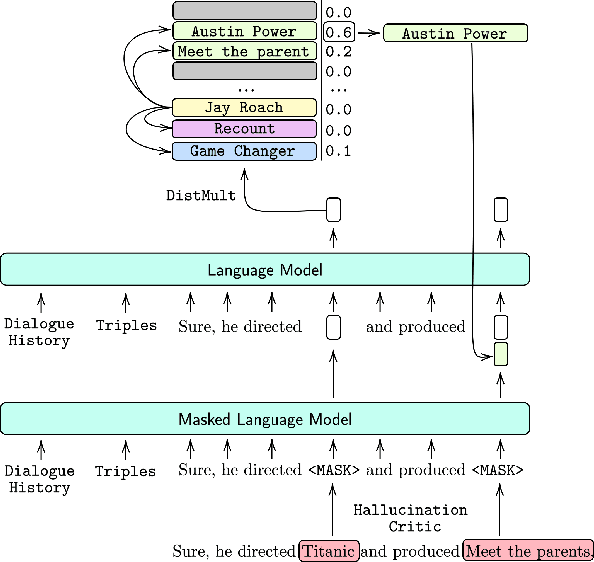
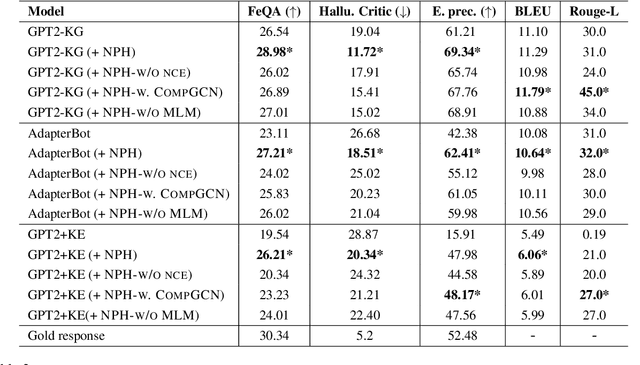
Dialogue systems powered by large pre-trained language models (LM) exhibit an innate ability to deliver fluent and natural-looking responses. Despite their impressive generation performance, these models can often generate factually incorrect statements impeding their widespread adoption. In this paper, we focus on the task of improving the faithfulness -- and thus reduce hallucination -- of Neural Dialogue Systems to known facts supplied by a Knowledge Graph (KG). We propose Neural Path Hunter which follows a generate-then-refine strategy whereby a generated response is amended using the k-hop subgraph of a KG. Neural Path Hunter leverages a separate token-level fact critic to identify plausible sources of hallucination followed by a refinement stage consisting of a chain of two neural LM's that retrieves correct entities by crafting a query signal that is propagated over the k-hop subgraph. Our proposed model can easily be applied to any dialogue generated responses without retraining the model. We empirically validate our proposed approach on the OpenDialKG dataset against a suite of metrics and report a relative improvement of faithfulness over GPT2 dialogue responses by 8.4%.
Building a Competitive Associative Classifier
Jul 04, 2020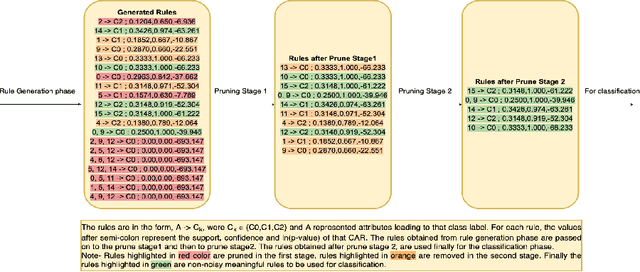
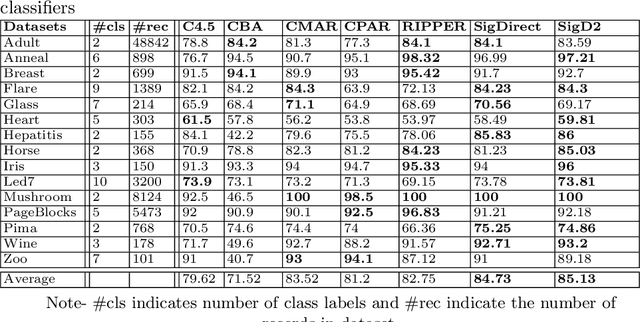
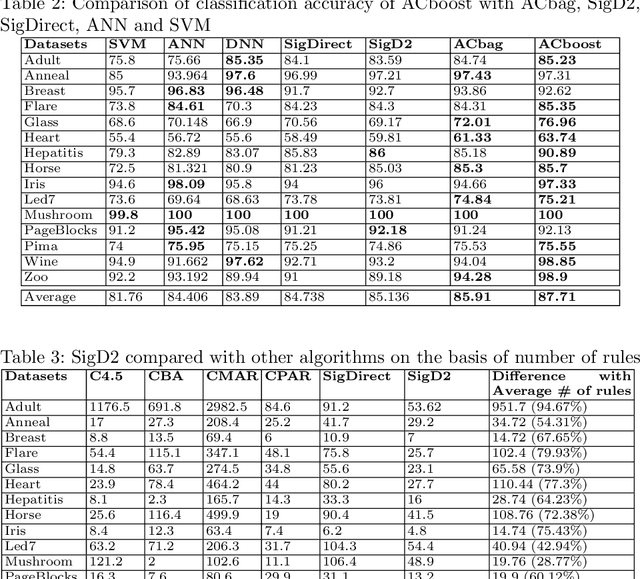
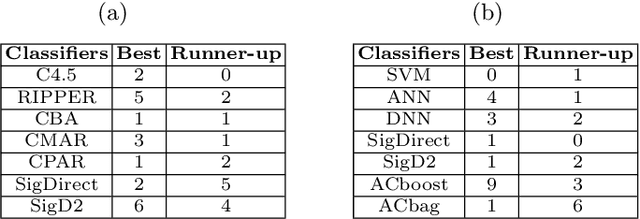
With the huge success of deep learning, other machine learning paradigms have had to take back seat. Yet other models, particularly rule-based, are more readable and explainable and can even be competitive when labelled data is not abundant. However, most of the existing rule-based classifiers suffer from the production of a large number of classification rules, affecting the model readability. This hampers the classification accuracy as noisy rules might not add any useful informationfor classification and also lead to longer classification time. In this study, we propose SigD2 which uses a novel, two-stage pruning strategy which prunes most of the noisy, redundant and uninteresting rules and makes the classification model more accurate and readable. To make SigDirect more competitive with the most prevalent but uninterpretable machine learning-based classifiers like neural networks and support vector machines, we propose bagging and boosting on the ensemble of the SigDirect classifier. The results of the proposed algorithms are quite promising and we are able to obtain a minimal set of statistically significant rules for classification without jeopardizing the classification accuracy. We use 15 UCI datasets and compare our approach with eight existing systems.The SigD2 and boosted SigDirect (ACboost) ensemble model outperform various state-of-the-art classifiers not only in terms of classification accuracy but also in terms of the number of rules.
Evaluating Coherence in Dialogue Systems using Entailment
Apr 06, 2019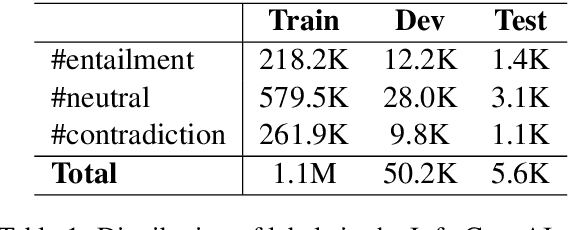
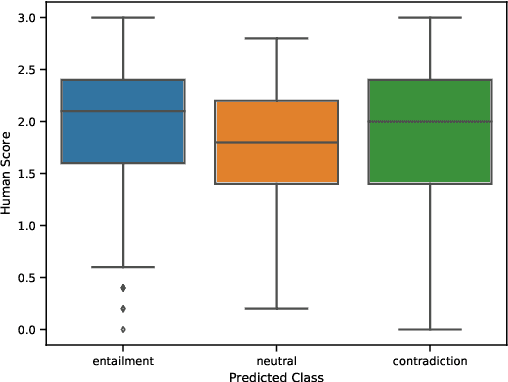

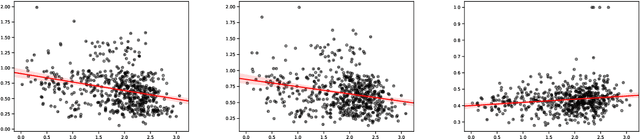
Evaluating open-domain dialogue systems is difficult due to the diversity of possible correct answers. Automatic metrics such as BLEU correlate weakly with human annotations, resulting in a significant bias across different models and datasets. Some researchers resort to human judgment experimentation for assessing response quality, which is expensive, time consuming, and not scalable. Moreover, judges tend to evaluate a small number of dialogues, meaning that minor differences in evaluation configuration may lead to dissimilar results. In this paper, we present interpretable metrics for evaluating topic coherence by making use of distributed sentence representations. Furthermore, we introduce calculable approximations of human judgment based on conversational coherence by adopting state-of-the-art entailment techniques. Results show that our metrics can be used as a surrogate for human judgment, making it easy to evaluate dialogue systems on large-scale datasets and allowing an unbiased estimate for the quality of the responses.
Augmenting Neural Response Generation with Context-Aware Topical Attention
Nov 02, 2018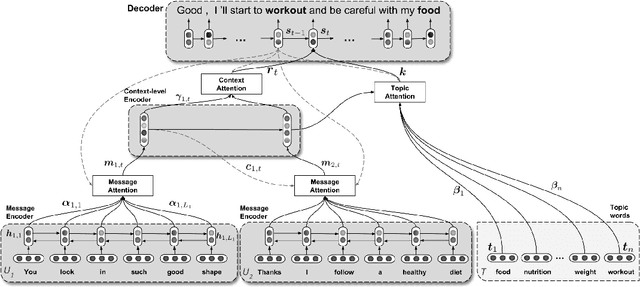

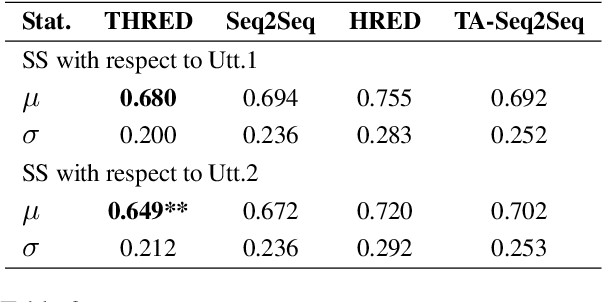
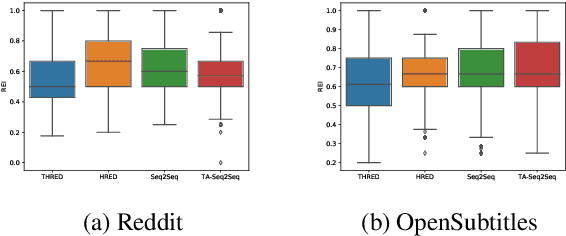
Sequence-to-Sequence (Seq2Seq) models have witnessed a notable success in generating natural conversational exchanges. Notwithstanding the syntactically well-formed responses generated by these neural network models, they are prone to be acontextual, short and generic. In this work, we introduce a Topical Hierarchical Recurrent Encoder Decoder (THRED), a novel, fully data-driven, multi-turn response generation system intended to produce contextual and topic-aware responses. Our model is built upon the basic Seq2Seq model by augmenting it with a hierarchical joint attention mechanism that incorporates topical concepts and previous interactions into the response generation. To train our model, we provide a clean and high-quality conversational dataset mined from Reddit comments. We evaluate THRED on two novel automated metrics, dubbed Semantic Similarity and Response Echo Index, as well as with human evaluation. Our experiments demonstrate that the proposed model is able to generate more diverse and contextually relevant responses compared to the strong baselines.