 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgCMV: An Argument Summarization Benchmark for the LLM-era
Aug 27, 2025



Key point extraction is an important task in argument summarization which involves extracting high-level short summaries from arguments. Existing approaches for KP extraction have been mostly evaluated on the popular ArgKP21 dataset. In this paper, we highlight some of the major limitations of the ArgKP21 dataset and demonstrate the need for new benchmarks that are more representative of actual human conversations. Using SoTA large language models (LLMs), we curate a new argument key point extraction dataset called ArgCMV comprising of around 12K arguments from actual online human debates spread across over 3K topics. Our dataset exhibits higher complexity such as longer, co-referencing arguments, higher presence of subjective discourse units, and a larger range of topics over ArgKP21. We show that existing methods do not adapt well to ArgCMV and provide extensive benchmark results by experimenting with existing baselines and latest open source models. This work introduces a novel KP extraction dataset for long-context online discussions, setting the stage for the next generation of LLM-driven summarization research.
Should I visit this place? Inclusion and Exclusion Phrase Mining from Reviews
Dec 18, 2020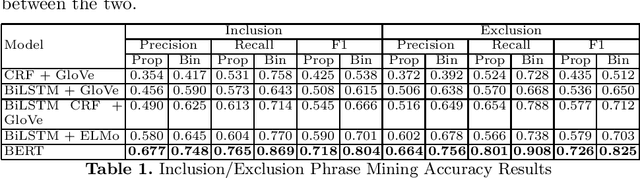
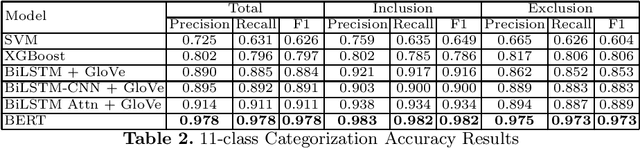
Although several automatic itinerary generation services have made travel planning easy, often times travellers find themselves in unique situations where they cannot make the best out of their trip. Visitors differ in terms of many factors such as suffering from a disability, being of a particular dietary preference, travelling with a toddler, etc. While most tourist spots are universal, others may not be inclusive for all. In this paper, we focus on the problem of mining inclusion and exclusion phrases associated with 11 such factors, from reviews related to a tourist spot. While existing work on tourism data mining mainly focuses on structured extraction of trip related information, personalized sentiment analysis, and automatic itinerary generation, to the best of our knowledge this is the first work on inclusion/exclusion phrase mining from tourism reviews. Using a dataset of 2000 reviews related to 1000 tourist spots, our broad level classifier provides a binary overlap F1 of $\sim$80 and $\sim$82 to classify a phrase as inclusion or exclusion respectively. Further, our inclusion/exclusion classifier provides an F1 of $\sim$98 and $\sim$97 for 11-class inclusion and exclusion classification respectively. We believe that our work can significantly improve the quality of an automatic itinerary generation service.