 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdFix: An Eyetracking Dataset of Real Life Crowd Videos
Oct 09, 2019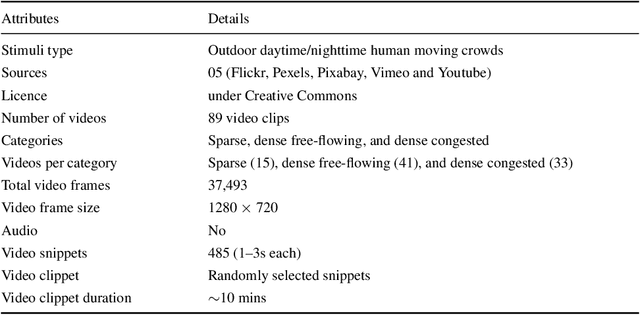
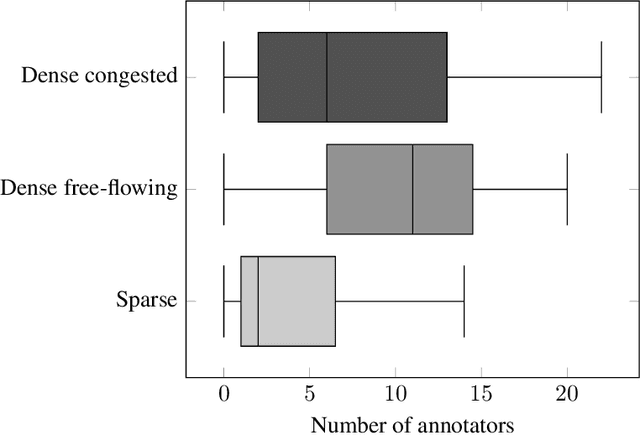

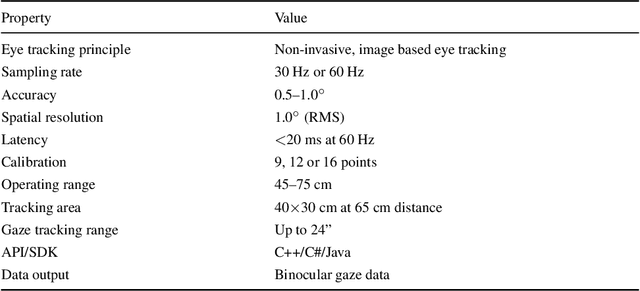
Understanding human visual attention and saliency is an integral part of vision research. In this context, there is an ever-present need for fresh and diverse benchmark datasets, particularly for insight into special use cases like crowded scenes. We contribute to this end by: (1) reviewing the dynamics behind saliency and crowds. (2) using eye tracking to create a dynamic human eye fixation dataset over a new set of crowd videos gathered from the Internet. The videos are annotated into three distinct density levels. (3) Finally, we evaluate state-of-the-art saliency models on our dataset to identify possible improvements for the design and creation of a more robust saliency model.
Tracking via Motion Estimation with Physically Motivated Inter-Region Constraints
Feb 06, 2014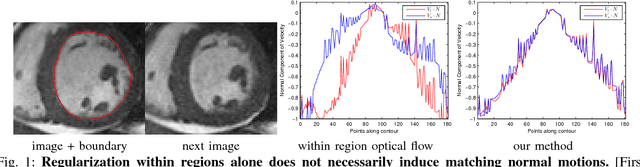
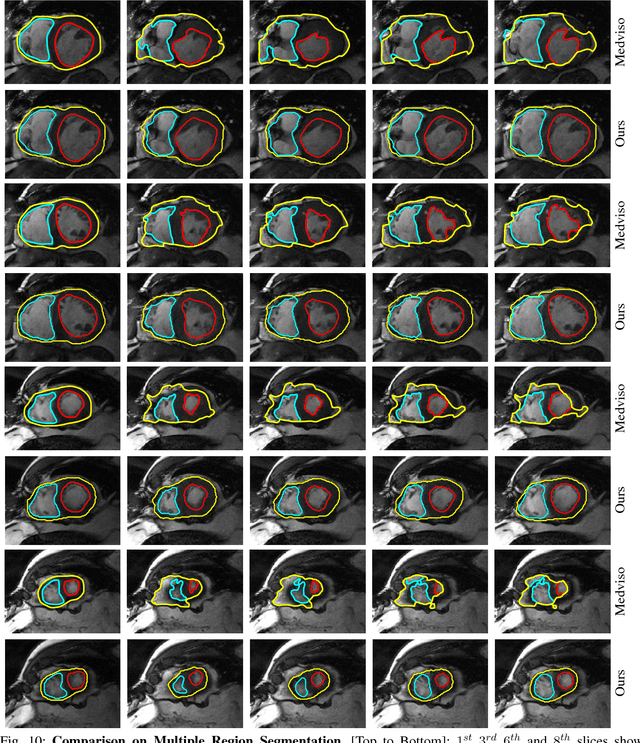
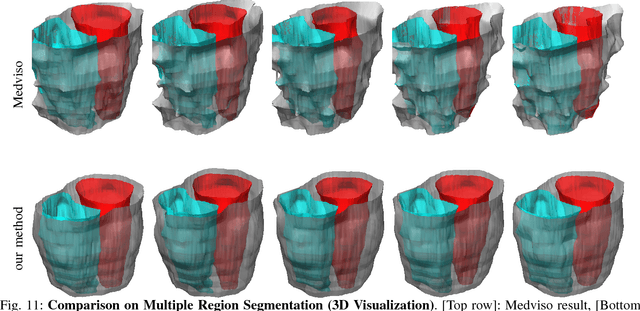

In this paper, we propose a method for tracking structures (e.g., ventricles and myocardium) in cardiac images (e.g., magnetic resonance) by propagating forward in time a previous estimate of the structures via a new deformation estimation scheme that is motivated by physical constraints of fluid motion. The method employs within structure motion estimation (so that differing motions among different structures are not mixed) while simultaneously satisfying the physical constraint in fluid motion that at the interface between a fluid and a medium, the normal component of the fluid's motion must match the normal component of the motion of the medium. We show how to estimate the motion according to the previous considerations in a variational framework, and in particular, show that these conditions lead to PDEs with boundary conditions at the interface that resemble Robin boundary conditions and induce coupling between structures. We illustrate the use of this motion estimation scheme in propagating a segmentation across frames and show that it leads to more accurate segmentation than traditional motion estimation that does not make use of physical constraints. Further, the method is naturally suited to interactive segmentation methods, which are prominently used in practice in commercial applications for cardiac analysis, where typically a segmentation from the previous frame is used to predict a segmentation in the next frame. We show that our propagation scheme reduces the amount of user interaction by predicting more accurate segmentations than commonly used and recent interactive commercial techniques.