 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Human-in-the-Loop Object Retrieval with Pre-Trained Vision Transformers
Apr 01, 2026Building on existing approaches, we revisit Human-in-the-Loop Object Retrieval, a task that consists of iteratively retrieving images containing objects of a class-of-interest, specified by a user-provided query. Starting from a large unlabeled image collection, the aim is to rapidly identify diverse instances of an object category relying solely on the initial query and the user's Relevance Feedback, with no prior labels. The retrieval process is formulated as a binary classification task, where the system continuously learns to distinguish between relevant and non-relevant images to the query, through iterative user interaction. This interaction is guided by an Active Learning loop: at each iteration, the system selects informative samples for user annotation, thereby refining the retrieval performance. This task is particularly challenging in multi-object datasets, where the object of interest may occupy only a small region of the image within a complex, cluttered scene. Unlike object-centered settings where global descriptors often suffice, multi-object images require more adapted, localized descriptors. In this work, we formulate and revisit the Human-in-the-Loop Object Retrieval task by leveraging pre-trained ViT representations, and addressing key design questions, including which object instances to consider in an image, what form the annotations should take, how Active Selection should be applied, and which representation strategies best capture the object's features. We compare several representation strategies across multi-object datasets highlighting trade-offs between capturing the global context and focusing on fine-grained local object details. Our results offer practical insights for the design of effective interactive retrieval pipelines based on Active Learning for object class retrieval.
Positive-First Most Ambiguous: A Simple Active Learning Criterion for Interactive Retrieval of Rare Categories
Mar 25, 2026Real-world fine-grained visual retrieval often requires discovering a rare concept from large unlabeled collections with minimal supervision. This is especially critical in biodiversity monitoring, ecological studies, and long-tailed visual domains, where the target may represent only a tiny fraction of the data, creating highly imbalanced binary problems. Interactive retrieval with relevance feedback offers a practical solution: starting from a small query, the system selects candidates for binary user annotation and iteratively refines a lightweight classifier. While Active Learning (AL) is commonly used to guide selection, conventional AL assumes symmetric class priors and large annotation budgets, limiting effectiveness in imbalanced, low-budget, low-latency settings. We introduce Positive-First Most Ambiguous (PF-MA), a simple yet effective AL criterion that explicitly addresses the class imbalance asymmetry: it prioritizes near-boundary samples while favoring likely positives, enabling rapid discovery of subtle visual categories while maintaining informativeness. Unlike standard methods that oversample negatives, PF-MA consistently returns small batches with a high proportion of relevant samples, improving early retrieval and user satisfaction. To capture retrieval diversity, we also propose a class coverage metric that measures how well selected positives span the visual variability of the target class. Experiments on long-tailed datasets, including fine-grained botanical data, demonstrate that PF-MA consistently outperforms strong baselines in both coverage and classifier performance, across varying class sizes and descriptors. Our results highlight that aligning AL with the asymmetric and user-centric objectives of interactive fine-grained retrieval enables simple yet powerful solutions for retrieving rare and visually subtle categories in realistic human-in-the-loop settings.
Self-Supervised Learning as Discrete Communication
Feb 10, 2026Most self-supervised learning (SSL) methods learn continuous visual representations by aligning different views of the same input, offering limited control over how information is structured across representation dimensions. In this work, we frame visual self-supervised learning as a discrete communication process between a teacher and a student network, where semantic information is transmitted through a fixed-capacity binary channel. Rather than aligning continuous features, the student predicts multi-label binary messages produced by the teacher. Discrete agreement is enforced through an element-wise binary cross-entropy objective, while a coding-rate regularization term encourages effective utilization of the constrained channel, promoting structured representations. We further show that periodically reinitializing the projection head strengthens this effect by encouraging embeddings that remain predictive across multiple discrete encodings. Extensive experiments demonstrate consistent improvements over continuous agreement baselines on image classification, retrieval, and dense visual prediction tasks, as well as under domain shift through self-supervised adaptation. Beyond backbone representations, we analyze the learned binary codes and show that they form a compact and informative discrete language, capturing semantic factors reusable across classes.
How does the degree of novelty impacts semi-supervised representation learning for novel class retrieval?
Aug 17, 2022
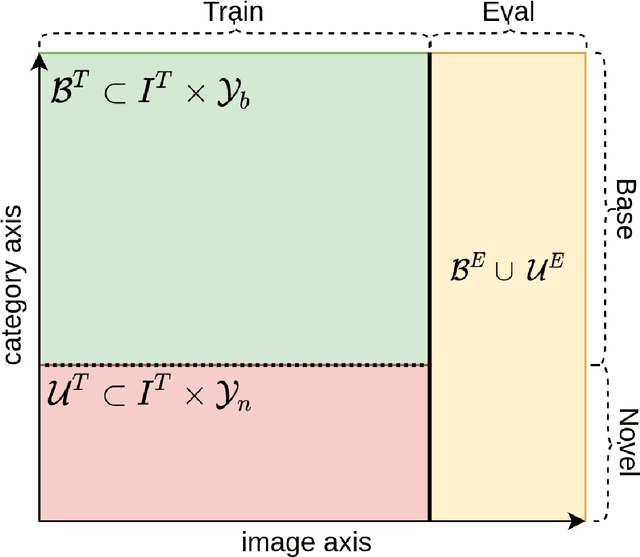
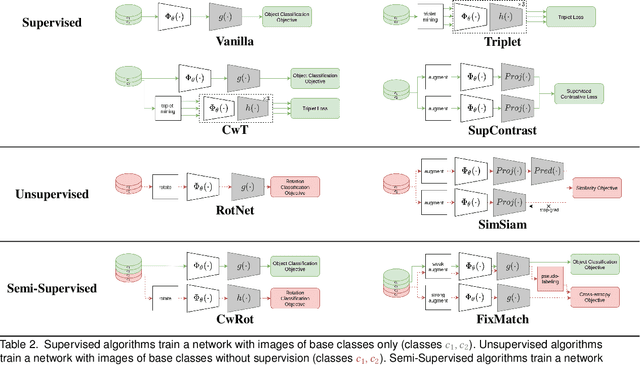
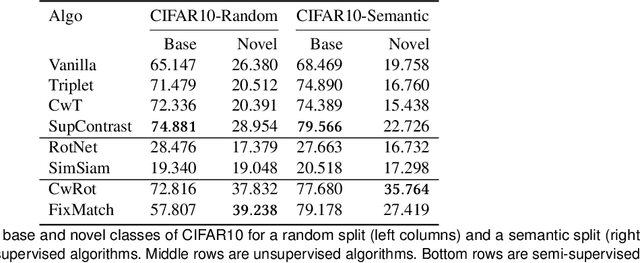
Supervised representation learning with deep networks tends to overfit the training classes and the generalization to novel classes is a challenging question. It is common to evaluate a learned embedding on held-out images of the same training classes. In real applications however, data comes from new sources and novel classes are likely to arise. We hypothesize that incorporating unlabelled images of novel classes in the training set in a semi-supervised fashion would be beneficial for the efficient retrieval of novel-class images compared to a vanilla supervised representation. To verify this hypothesis in a comprehensive way, we propose an original evaluation methodology that varies the degree of novelty of novel classes by partitioning the dataset category-wise either randomly, or semantically, i.e. by minimizing the shared semantics between base and novel classes. This evaluation procedure allows to train a representation blindly to any novel-class labels and evaluate the frozen representation on the retrieval of base or novel classes. We find that a vanilla supervised representation falls short on the retrieval of novel classes even more so when the semantics gap is higher. Semi-supervised algorithms allow to partially bridge this performance gap but there is still much room for improvement.