 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Where It Matters: A Novel Spike Aware Mixed-Precision Quantization Strategy for LLaMA-based Language Models
Apr 30, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various natural language processing tasks. However, their size presents significant challenges for deployment and inference. This paper investigates the quantization of LLMs, focusing on the LLaMA architecture and its derivatives. We challenge existing assumptions about activation outliers in LLMs and propose a novel mixed-precision quantization approach tailored for LLaMA-like models. Our method leverages the observation that activation spikes in LLaMA architectures are predominantly concentrated in specific projection layers. By applying higher precision (FP16 or FP8) to these layers while quantizing the rest of the model to lower bit-widths, we achieve superior performance compared to existing quantization techniques. Experimental results on LLaMA2, LLaMA3, and Mistral models demonstrate significant improvements in perplexity and zero-shot accuracy, particularly for 8-bit per-tensor quantization. Our approach outperforms general-purpose methods designed to handle outliers across all architecture types, highlighting the benefits of architecture-specific quantization strategies. This research contributes to the ongoing efforts to make LLMs more efficient and deployable, potentially enabling their use in resource-constrained environments. Our findings emphasize the importance of considering model-specific characteristics in developing effective quantization pipelines for state-of-the-art language models by identifying and targeting a small number of projections that concentrate activation spikes.
Gradual Binary Search and Dimension Expansion : A general method for activation quantization in LLMs
Apr 18, 2025Large language models (LLMs) have become pivotal in artificial intelligence, demonstrating strong capabilities in reasoning, understanding, and generating data. However, their deployment on edge devices is hindered by their substantial size, often reaching several billion parameters. Quantization is a widely used method to reduce memory usage and inference time, however LLMs present unique challenges due to the prevalence of outliers in their activations. In this work, we leverage the theoretical advantages of Hadamard matrices over random rotation matrices to push the boundaries of quantization in LLMs. We demonstrate that Hadamard matrices are more effective in reducing outliers, which are a significant obstacle in achieving low-bit quantization. Our method based on a gradual binary search enables 3-bit quantization for weights, activations, and key-value (KV) caches, resulting in a 40\% increase in accuracy on common benchmarks compared to SoTA methods. We extend the use of rotation matrices to support non-power-of-2 embedding dimensions, similar to the Qwen architecture, by employing the Paley algorithm. We theoretically demonstrates the superiority of Hadamard matrices in reducing outliers.We achieved 3-bit quantization for weights, activations, and KV cache, significantly enhancing model performance. Our experimental results on multiple models family like Mistral, LLaMA, and Qwen demonstrate the effectiveness of our approach, outperforming existing methods and enabling practical 3-bit quantization.
SpikeGrad: An ANN-equivalent Computation Model for Implementing Backpropagation with Spikes
Jun 03, 2019



Event-based neuromorphic systems promise to reduce the energy consumption of deep learning tasks by replacing expensive floating point operations on dense matrices by low power sparse and asynchronous operations on spike events. While these systems can be trained increasingly well using approximations of the back-propagation algorithm, these implementations usually require high precision errors for training and are therefore incompatible with the typical communication infrastructure of neuromorphic circuits. In this work, we analyze how the gradient can be discretized into spike events when training a spiking neural network. To accelerate our simulation, we show that using a special implementation of the integrate-and-fire neuron allows us to describe the accumulated activations and errors of the spiking neural network in terms of an equivalent artificial neural network, allowing us to largely speed up training compared to an explicit simulation of all spike events. This way we are able to demonstrate that even for deep networks, the gradients can be discretized sufficiently well with spikes if the gradient is properly rescaled. This form of spike-based backpropagation enables us to achieve equivalent or better accuracies on the MNIST and CIFAR10 dataset than comparable state-of-the-art spiking neural networks trained with full precision gradients. The algorithm, which we call SpikeGrad, is based on accumulation and comparison operations and can naturally exploit sparsity in the gradient computation, which makes it an interesting choice for a spiking neuromorphic systems with on-chip learning capacities.
A Spiking Network for Inference of Relations Trained with Neuromorphic Backpropagation
Mar 11, 2019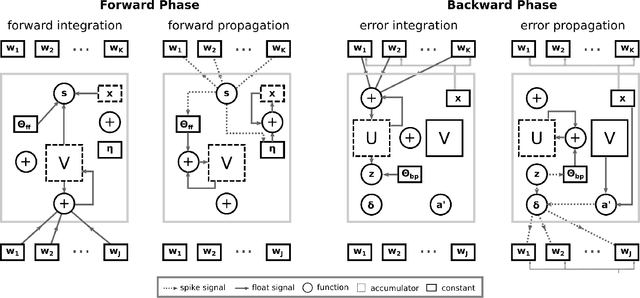
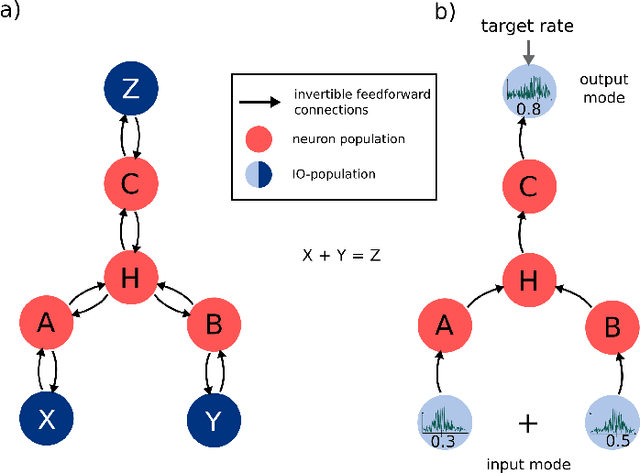
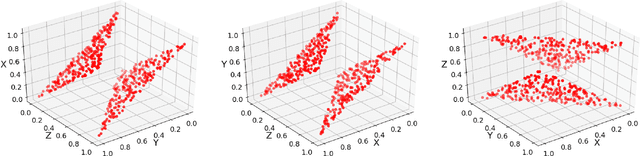
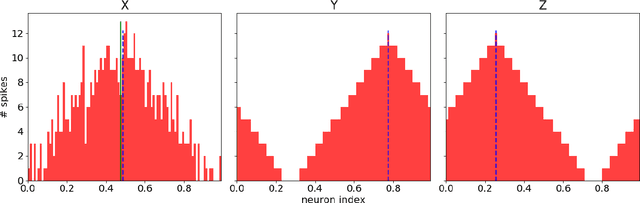
The increasing need for intelligent sensors in a wide range of everyday objects requires the existence of low power information processing systems which can operate autonomously in their environment. In particular, merging and processing the outputs of different sensors efficiently is a necessary requirement for mobile agents with cognitive abilities. In this work, we present a multi-layer spiking neural network for inference of relations between stimuli patterns in dedicated neuromorphic systems. The system is trained with a new version of the backpropagation algorithm adapted to on-chip learning in neuromorphic hardware: Error gradients are encoded as spike signals which are propagated through symmetric synapses, using the same integrate-and-fire hardware infrastructure as used during forward propagation. We demonstrate the strength of the approach on an arithmetic relation inference task and on visual XOR on the MNIST dataset. Compared to previous, biologically-inspired implementations of networks for learning and inference of relations, our approach is able to achieve better performance with less neurons. Our architecture is the first spiking neural network architecture with on-chip learning capabilities, which is able to perform relational inference on complex visual stimuli. These features make our system interesting for sensor fusion applications and embedded learning in autonomous neuromorphic agents.