 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHINO-MAG: Recursive H-Field Inference based on Observed Magnetic Flux under Dynamic Excitation
Mar 31, 2026Driven by the MagNet Challenge 2025 (MC2), increased research interest is directed towards modeling transient magnetic fields within ferrite material. An accurate time-resolved and temperature-aware H-field prediction is essential for optimizing magnetic components in applications with quasi-stationary / non-stationary excitation waveforms. Within the scope of this investigation, a selection of model structures with varying degrees of physically motivated structure are compared. Based on a Pareto investigation, a rather black-box gated recurrent unit (GRU) model structure with a graceful initialization setup is found to offer the most attractive model size vs. model accuracy trade-off, while the physics-inspired models performed worse. For a GRU-based model with only 325 parameters, a sequence relative error of 8.02 % and a normalized energy relative error of 1.07 % averaged across five different materials are achieved on unseen test data. With this excellent parameter efficiency, the proposed model won the first place in the performance category of the MC2.
HARDCORE: H-field and power loss estimation for arbitrary waveforms with residual, dilated convolutional neural networks in ferrite cores
Jan 23, 2024



The MagNet Challenge 2023 calls upon competitors to develop data-driven models for the material-specific, waveform-agnostic estimation of steady-state power losses in toroidal ferrite cores. The following HARDCORE (H-field and power loss estimation for Arbitrary waveforms with Residual, Dilated convolutional neural networks in ferrite COREs) approach shows that a residual convolutional neural network with physics-informed extensions can serve this task efficiently when trained on observational data beforehand. One key solution element is an intermediate model layer which first reconstructs the bh curve and then estimates the power losses based on the curve's area rendering the proposed topology physically interpretable. In addition, emphasis was placed on expert-based feature engineering and information-rich inputs in order to enable a lean model architecture. A model is trained from scratch for each material, while the topology remains the same. A Pareto-style trade-off between model size and estimation accuracy is demonstrated, which yields an optimum at as low as 1755 parameters and down to below 8\,\% for the 95-th percentile of the relative error for the worst-case material with sufficient samples.
Distributed Control of Partial Differential Equations Using Convolutional Reinforcement Learning
Jan 25, 2023We present a convolutional framework which significantly reduces the complexity and thus, the computational effort for distributed reinforcement learning control of dynamical systems governed by partial differential equations (PDEs). Exploiting translational invariances, the high-dimensional distributed control problem can be transformed into a multi-agent control problem with many identical, uncoupled agents. Furthermore, using the fact that information is transported with finite velocity in many cases, the dimension of the agents' environment can be drastically reduced using a convolution operation over the state space of the PDE. In this setting, the complexity can be flexibly adjusted via the kernel width or by using a stride greater than one. Moreover, scaling from smaller to larger systems -- or the transfer between different domains -- becomes a straightforward task requiring little effort. We demonstrate the performance of the proposed framework using several PDE examples with increasing complexity, where stabilization is achieved by training a low-dimensional deep deterministic policy gradient agent using minimal computing resources.
Steady-State Error Compensation in Reference Tracking and Disturbance Rejection Problems for Reinforcement Learning-Based Control
Jan 31, 2022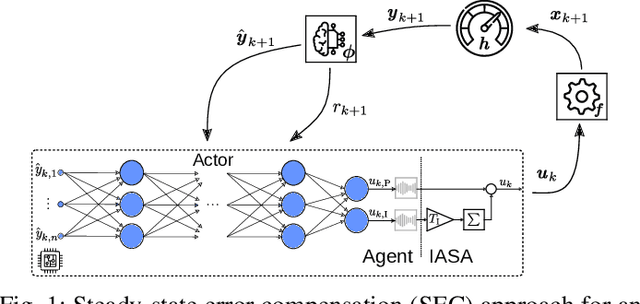
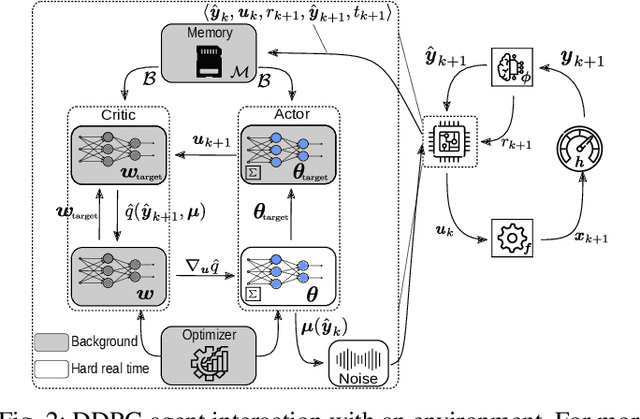
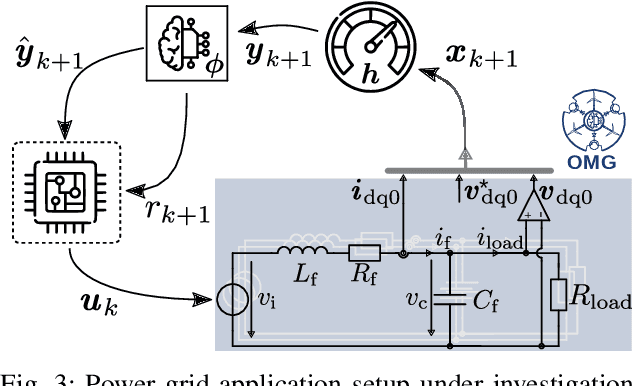
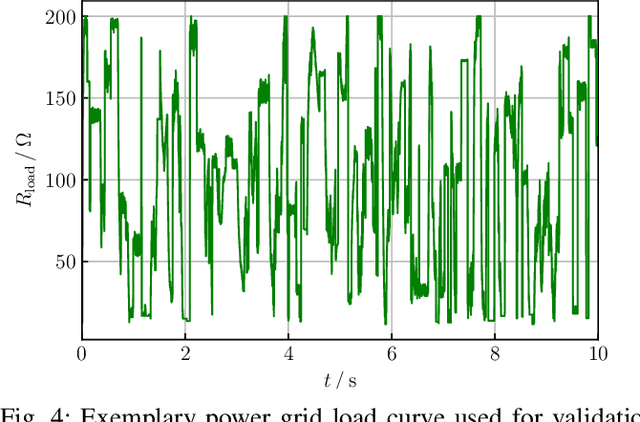
Reinforcement learning (RL) is a promising, upcoming topic in automatic control applications. Where classical control approaches require a priori system knowledge, data-driven control approaches like RL allow a model-free controller design procedure, rendering them emergent techniques for systems with changing plant structures and varying parameters. While it was already shown in various applications that the transient control behavior for complex systems can be sufficiently handled by RL, the challenge of non-vanishing steady-state control errors remains, which arises from the usage of control policy approximations and finite training times. To overcome this issue, an integral action state augmentation (IASA) for actor-critic-based RL controllers is introduced that mimics an integrating feedback, which is inspired by the delta-input formulation within model predictive control. This augmentation does not require any expert knowledge, leaving the approach model free. As a result, the RL controller learns how to suppress steady-state control deviations much more effectively. Two exemplary applications from the domain of electrical energy engineering validate the benefit of the developed method both for reference tracking and disturbance rejection. In comparison to a standard deep deterministic policy gradient (DDPG) setup, the suggested IASA extension allows to reduce the steady-state error by up to 52 $\%$ within the considered validation scenarios.
Improved Exploring Starts by Kernel Density Estimation-Based State-Space Coverage Acceleration in Reinforcement Learning
May 19, 2021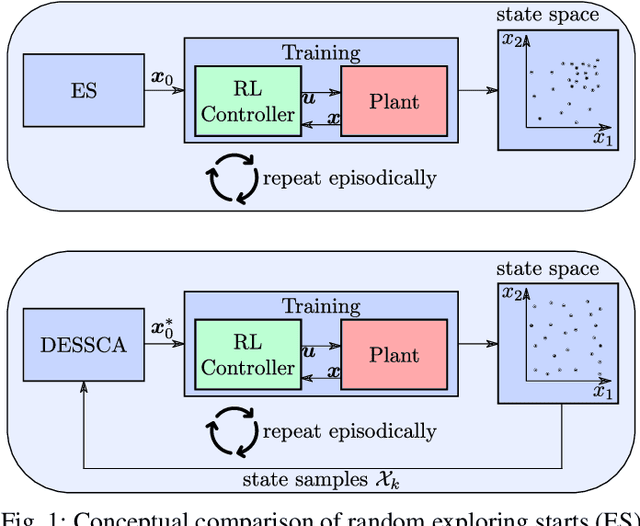
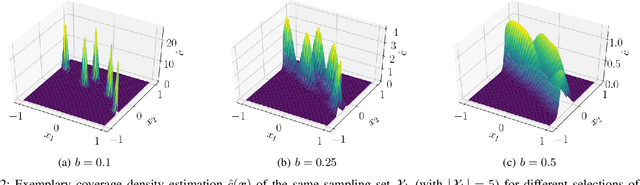
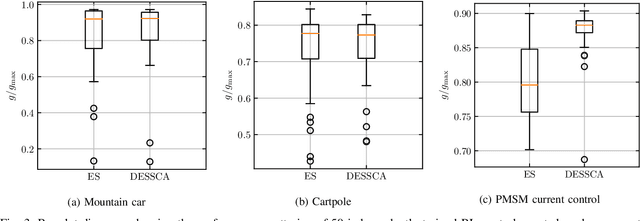
Reinforcement learning (RL) is currently a popular research topic in control engineering and has the potential to make its way to industrial and commercial applications. Corresponding RL controllers are trained in direct interaction with the controlled system, rendering them data-driven and performance-oriented solutions. The best practice of exploring starts (ES) is used by default to support the learning process via randomly picked initial states. However, this method might deliver strongly biased results if the system's dynamic and constraints lead to unfavorable sample distributions in the state space (e.g., condensed sample accumulation in certain state-space areas). To overcome this issue, a kernel density estimation-based state-space coverage acceleration (DESSCA) is proposed, which improves the ES concept by prioritizing infrequently visited states for a more balanced coverage of the state space during training. Considered test scenarios are mountain car, cartpole and electric motor control environments. Using DQN and DDPG as exemplary RL algorithms, it can be shown that DESSCA is a simple yet effective algorithmic extension to the established ES approach.
Thermal Neural Networks: Lumped-Parameter Thermal Modeling With State-Space Machine Learning
Apr 08, 2021
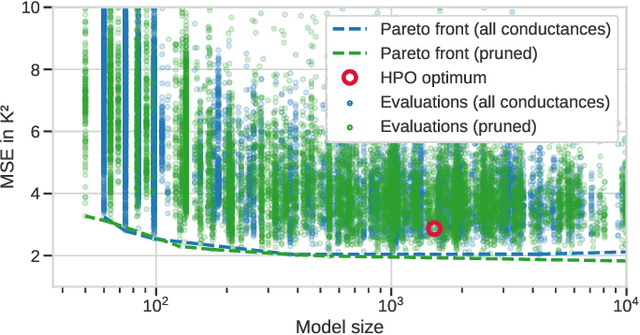
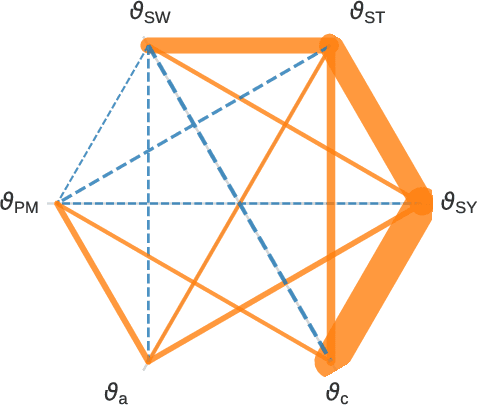
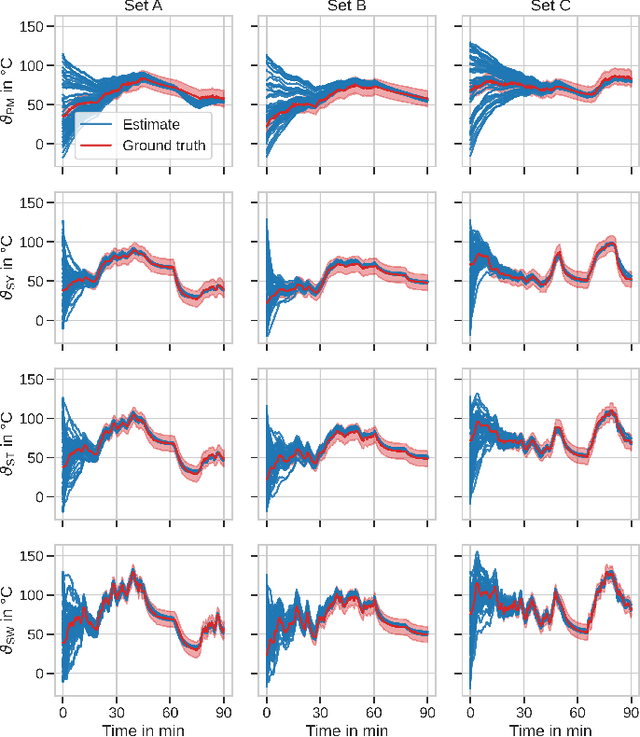
With electric power systems becoming more compact and increasingly powerful, the relevance of thermal stress especially during overload operation is expected to increase ceaselessly. Whenever critical temperatures cannot be measured economically on a sensor base, a thermal model lends itself to estimate those unknown quantities. Thermal models for electric power systems are usually required to be both, real-time capable and of high estimation accuracy. Moreover, ease of implementation and time to production play an increasingly important role. In this work, the thermal neural network (TNN) is introduced, which unifies both, consolidated knowledge in the form of heat-transfer-based lumped-parameter models, and data-driven nonlinear function approximation with supervised machine learning. A quasi-linear parameter-varying system is identified solely from empirical data, where relationships between scheduling variables and system matrices are inferred statistically and automatically. At the same time, a TNN has physically interpretable states through its state-space representation, is end-to-end trainable -- similar to deep learning models -- with automatic differentiation, and requires no material, geometry, nor expert knowledge for its design. Experiments on an electric motor data set show that a TNN achieves higher temperature estimation accuracies than previous white-/grey- or black-box models with a mean squared error of $3.18~\text{K}^2$ and a worst-case error of $5.84~\text{K}$ at 64 model parameters.
Data Set Description: Identifying the Physics Behind an Electric Motor -- Data-Driven Learning of the Electrical Behavior (Part II)
Mar 25, 2020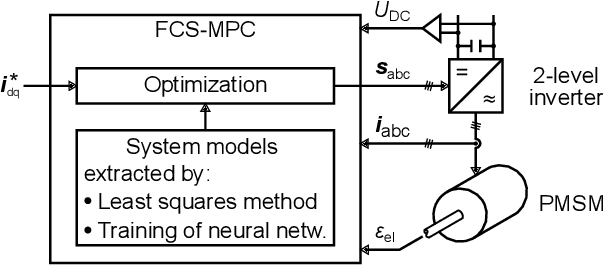
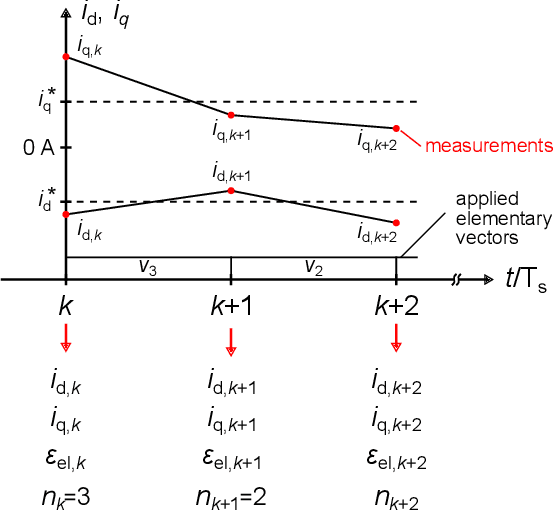

A data set was recorded to evaluate different methods for extracting mathematical models for a three-phase permanent magnet synchronous motor (PMSM) and a two-level IGBT inverter from measurement data. It consists of approximately 40 million multidimensional samples from a defined operating range of the drive. This document describes how to use the published data set \cite{Dataset} and how to extract models using introductory examples. The examples are based on known ordinary differential equations, the least squares method or on (deep) machine learning methods. The extracted models are used for the prediction of system states in a model predictive control (MPC) environment of the drive. In case of model deviations, the performance utilizing MPC remains below its potential. This is the case for state-of-the-art white-box models that are based only on nominal drive parameters and are valid in only limited operation regions. Moreover, many parasitic effects (e.g. from the feeding inverter) are normally not covered in white-box models. In order to achieve a high control performance, it is necessary to use models that cover the motor behavior in all operating points sufficiently well.
Data Set Description: Identifying the Physics Behind an Electric Motor -- Data-Driven Learning of the Electrical Behavior
Mar 25, 2020Two of the most important aspects of electric vehicles are their efficiency or achievable range. In order to achieve high efficiency and thus a long range, it is essential to avoid over-dimensioning the drive train. Therefore, the drive train has to be kept as lightweight as possible while at the same time being utilized to the best possible extent. This can only be achieved if the dynamic behavior of the drive train is accurately known by the controller. The task of the controller is to achieve a desired torque at the wheels of the car by controlling the currents of the electric motor. With machine learning modeling techniques, accurate models describing the behavior can be extracted from measurement data and then used by the controller. For the comparison of the different modeling approaches, a data set consisting of about 40 million data points was recorded at a test bench for electric drive trains. The data set is published on Kaggle, an online community of data scientists.
Data-Driven Permanent Magnet Temperature Estimation in Synchronous Motors with Supervised Machine Learning
Jan 17, 2020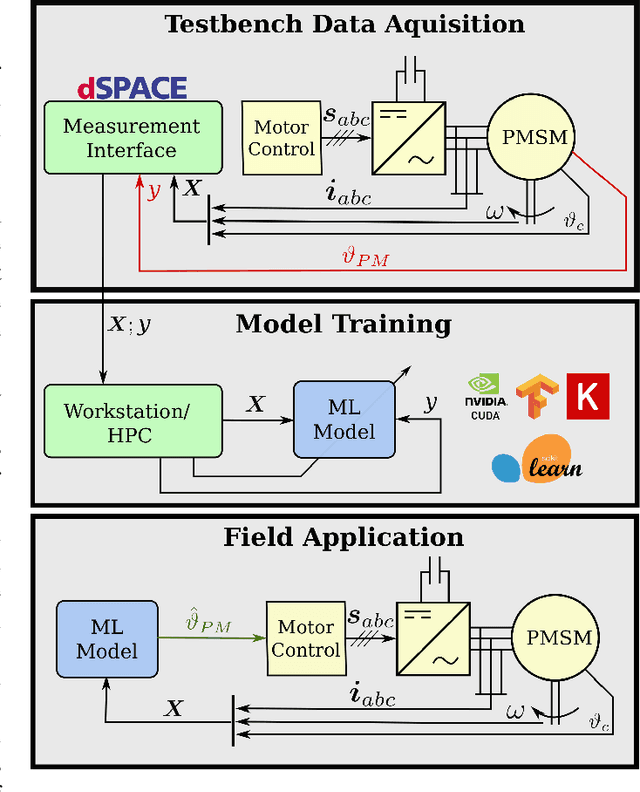

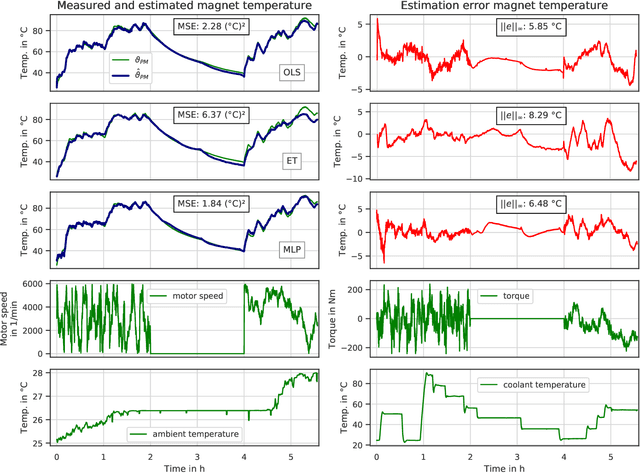
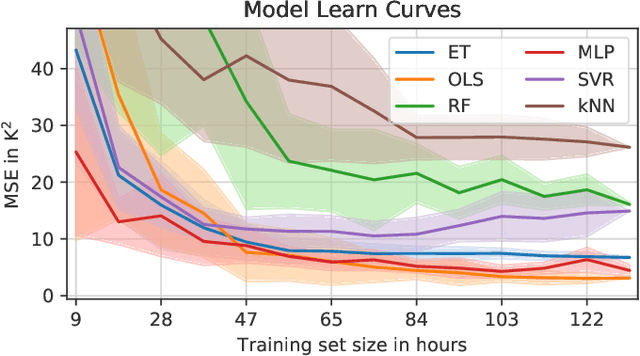
Monitoring the magnet temperature in permanent magnet synchronous motors (PMSMs) for automotive applications is a challenging task for several decades now, as signal injection or sensor-based methods still prove unfeasible in a commercial context. Overheating results in severe motor deterioration and is thus of high concern for the machine's control strategy and its design. Lack of precise temperature estimations leads to lesser device utilization and higher material cost. In this work, several machine learning (ML) models are empirically evaluated on their estimation accuracy for the task of predicting latent high-dynamic magnet temperature profiles. The range of selected algorithms covers as diverse approaches as possible with ordinary and weighted least squares, support vector regression, $k$-nearest neighbors, randomized trees and neural networks. Having test bench data available, it is shown that ML approaches relying merely on collected data meet the estimation performance of classical thermal models built on thermodynamic theory, yet not all kinds of models render efficient use of large datasets or sufficient modeling capacities. Especially linear regression and simple feed-forward neural networks with optimized hyperparameters mark strong predictive quality at low to moderate model sizes.
Towards a Reinforcement Learning Environment Toolbox for Intelligent Electric Motor Control
Oct 21, 2019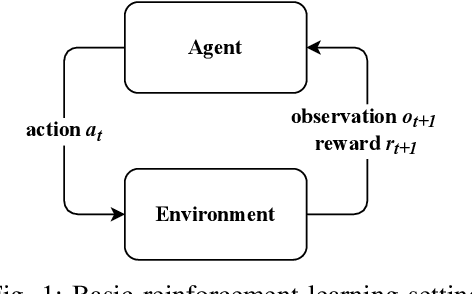
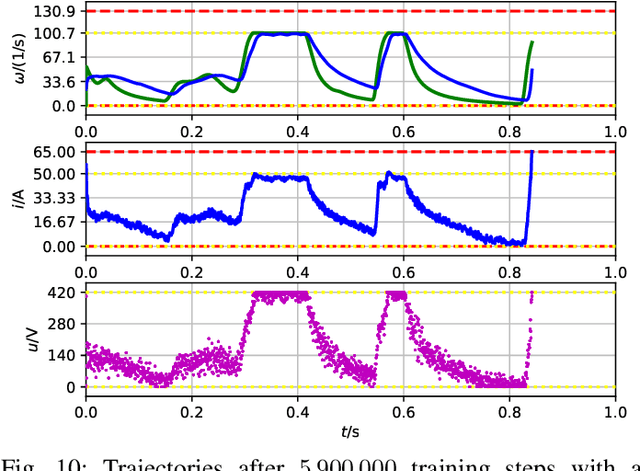
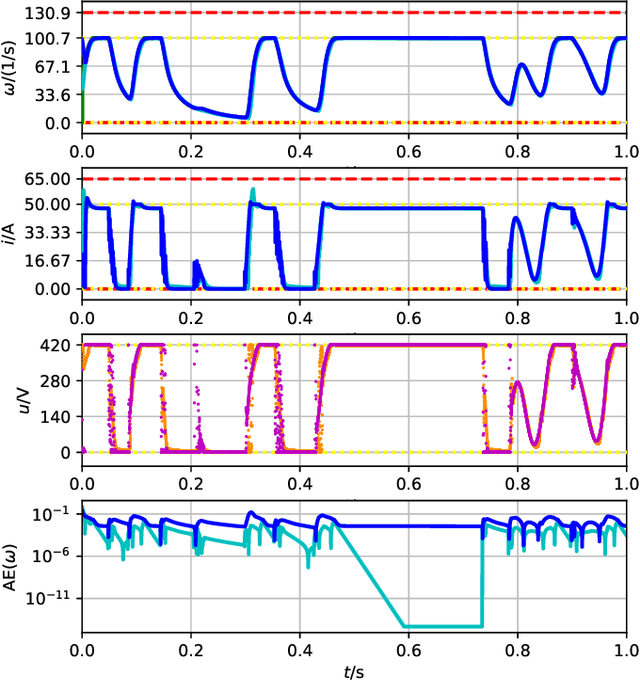
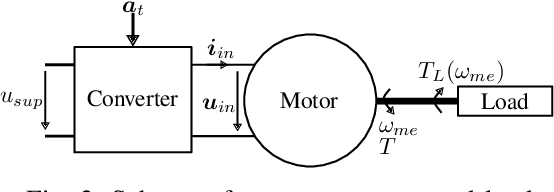
Electric motors are used in many applications and their efficiency is strongly dependent on their control. Among others, PI approaches or model predictive control methods are well-known in the scientific literature and industrial practice. A novel approach is to use reinforcement learning (RL) to have an agent learn electric drive control from scratch merely by interacting with a suitable control environment. RL achieved remarkable results with super-human performance in many games (e.g. Atari classics or Go) and also becomes more popular in control tasks like cartpole or swinging pendulum benchmarks. In this work, the open-source Python package gym-electric-motor (GEM) is developed for ease of training of RL-agents for electric motor control. Furthermore, this package can be used to compare the trained agents with other state-of-the-art control approaches. It is based on the OpenAI Gym framework that provides a widely used interface for the evaluation of RL-agents. The initial package version covers different DC motor variants and the prevalent permanent magnet synchronous motor as well as different power electronic converters and a mechanical load model. Due to the modular setup of the proposed toolbox, additional motor, load, and power electronic devices can be easily extended in the future. Furthermore, different secondary effects like controller interlocking time or noise are considered. An intelligent controller example based on the deep deterministic policy gradient algorithm which controls a series DC motor is presented and compared to a cascaded PI-controller as a baseline for future research. Fellow researchers are encouraged to use the framework in their RL investigations or to contribute to the functional scope (e.g. further motor types) of the package.