 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Factorisation for Polypharmacy Side Effect Prediction
Apr 17, 2024Adverse reactions caused by drug combinations are an increasingly common phenomenon, making their accurate prediction an important challenge in modern medicine. However, the polynomial nature of this problem renders lab-based identification of adverse reactions insufficient. Dozens of computational approaches have therefore been proposed for the task in recent years, with varying degrees of success. One group of methods that has seemingly been under-utilised in this area is tensor factorisation, despite their clear applicability to this type of data. In this work, we apply three such models to a benchmark dataset in order to compare them against established techniques. We find, in contrast to previous reports, that for this task tensor factorisation models are competitive with state-of-the-art graph neural network models and we recommend that future work in this field considers cheaper methods with linear complexity before running costly deep learning processes.
Assessing the Effects of Hyperparameters on Knowledge Graph Embedding Quality
Jul 05, 2022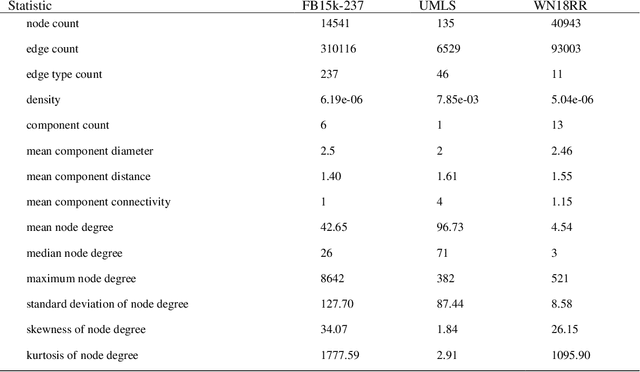
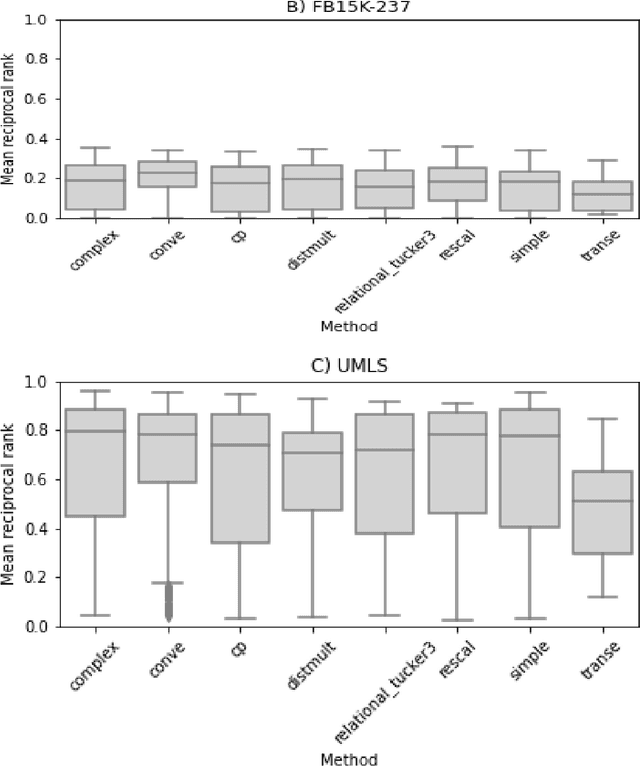
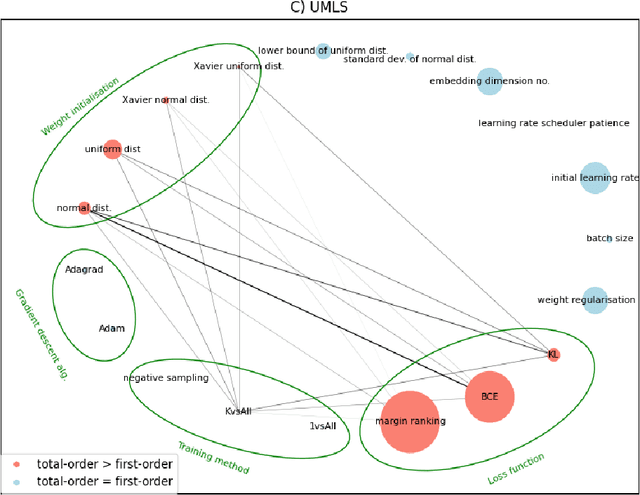
Embedding knowledge graphs into low-dimensional spaces is a popular method for applying approaches, such as link prediction or node classification, to these databases. This embedding process is very costly in terms of both computational time and space. Part of the reason for this is the optimisation of hyperparameters, which involves repeatedly sampling, by random, guided, or brute-force selection, from a large hyperparameter space and testing the resulting embeddings for their quality. However, not all hyperparameters in this search space will be equally important. In fact, with prior knowledge of the relative importance of the hyperparameters, some could be eliminated from the search altogether without significantly impacting the overall quality of the outputted embeddings. To this end, we ran a Sobol sensitivity analysis to evaluate the effects of tuning different hyperparameters on the variance of embedding quality. This was achieved by performing thousands of embedding trials, each time measuring the quality of embeddings produced by different hyperparameter configurations. We regressed the embedding quality on those hyperparameter configurations, using this model to generate Sobol sensitivity indices for each of the hyperparameters. By evaluating the correlation between Sobol indices, we find substantial variability in the hyperparameter sensitivities between knowledge graphs, with differing dataset characteristics being the probable cause of these inconsistencies. As an additional contribution of this work we identify several relations in the UMLS knowledge graph that may cause data leakage via inverse relations, and derive and present UMLS-43, a leakage-robust variant of that graph.