 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Turing~Machine for Conditional Transition Graph Modeling
Jul 15, 2019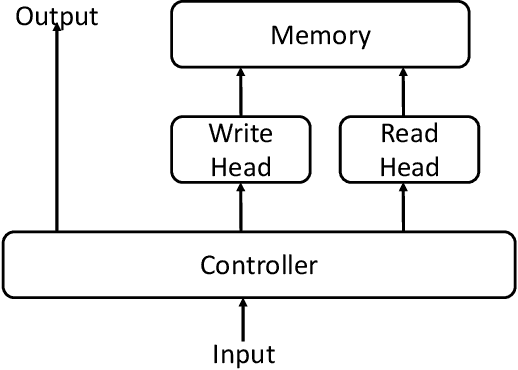
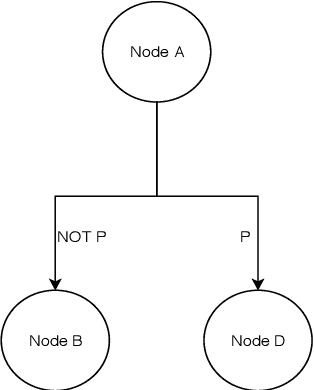
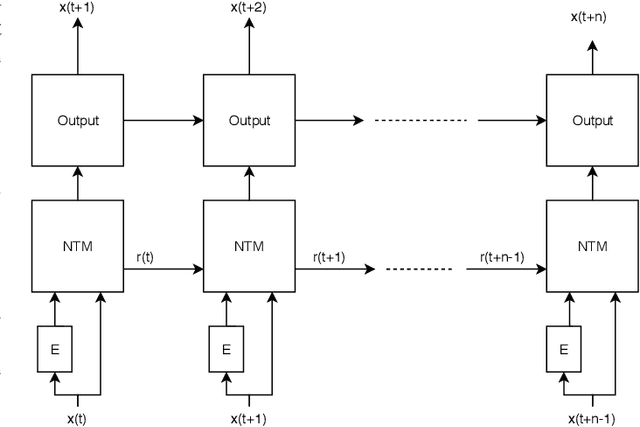

Graphs are an essential part of many machine learning problems such as analysis of parse trees, social networks, knowledge graphs, transportation systems, and molecular structures. Applying machine learning in these areas typically involves learning the graph structure and the relationship between the nodes of the graph. However, learning the graph structure is often complex, particularly when the graph is cyclic, and the transitions from one node to another are conditioned such as graphs used to represent a finite state machine. To solve this problem, we propose to extend the memory based Neural Turing Machine (NTM) with two novel additions. We allow for transitions between nodes to be influenced by information received from external environments, and we let the NTM learn the context of those transitions. We refer to this extension as the Conditional Neural Turing Machine (CNTM). We show that the CNTM can infer conditional transition graphs by empirically verifiying the model on two data sets: a large set of randomly generated graphs, and a graph modeling the information retrieval process during certain crisis situations. The results show that the CNTM is able to reproduce the paths inside the graph with accuracy ranging from 82,12% for 10 nodes graphs to 65,25% for 100 nodes graphs.
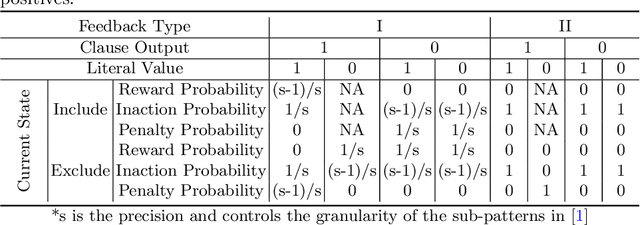
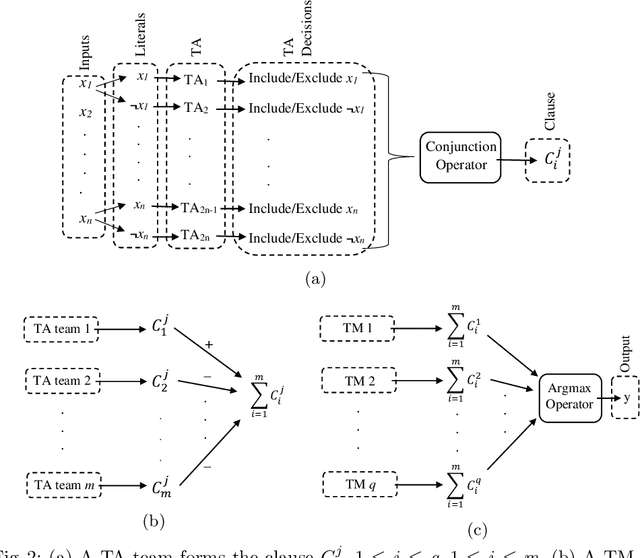
The Convolutional Tsetlin Machine
May 25, 2019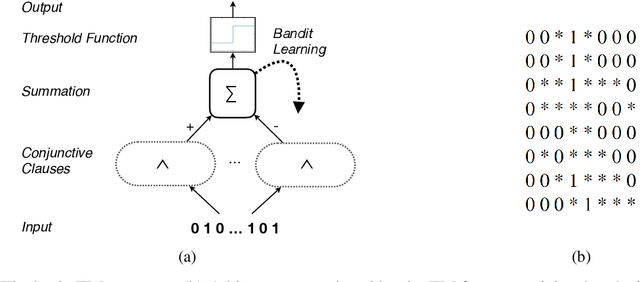
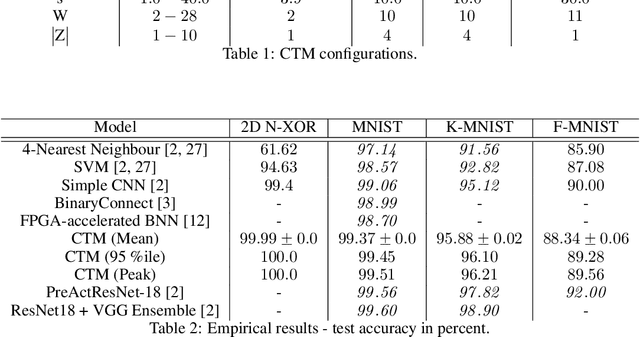
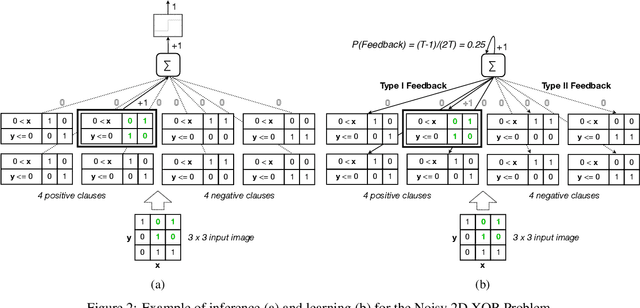
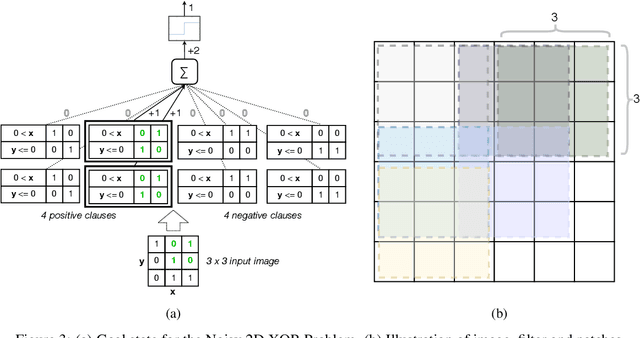
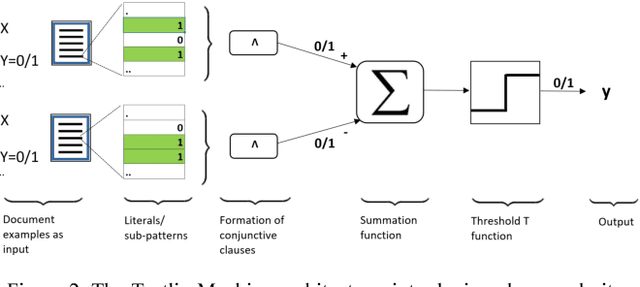
Deep neural networks have obtained astounding successes for important pattern recognition tasks, but they suffer from high computational complexity and the lack of interpretability. The recent Tsetlin Machine (TM) attempts to address this lack by using easy-to-interpret conjunctive clauses in propositional logic to solve complex pattern recognition problems. The TM provides competitive accuracy in several benchmarks, while keeping the important property of interpretability. It further facilitates hardware-near implementation since inputs, patterns, and outputs are expressed as bits, while recognition and learning rely on straightforward bit manipulation. In this paper, we exploit the TM paradigm by introducing the Convolutional Tsetlin Machine (CTM), as an interpretable alternative to convolutional neural networks (CNNs). Whereas the TM categorizes an image by employing each clause once to the whole image, the CTM uses each clause as a convolution filter. That is, a clause is evaluated multiple times, once per image patch taking part in the convolution. To make the clauses location-aware, each patch is further augmented with its coordinates within the image. The output of a convolution clause is obtained simply by ORing the outcome of evaluating the clause on each patch. In the learning phase of the TM, clauses that evaluate to 1 are contrasted against the input. For the CTM, we instead contrast against one of the patches, randomly selected among the patches that made the clause evaluate to 1. Accordingly, the standard Type I and Type II feedback of the classic TM can be employed directly, without further modification. The CTM obtains a peak test accuracy of 99.51% on MNIST, 96.21% on Kuzushiji-MNIST, 89.56% on Fashion-MNIST, and 100.0% on the 2D Noisy XOR Problem, which is competitive with results reported for simple 4-layer CNNs, BinaryConnect, and a recent FPGA-accelerated Binary CNN.
The Regression Tsetlin Machine: A Tsetlin Machine for Continuous Output Problems
May 10, 2019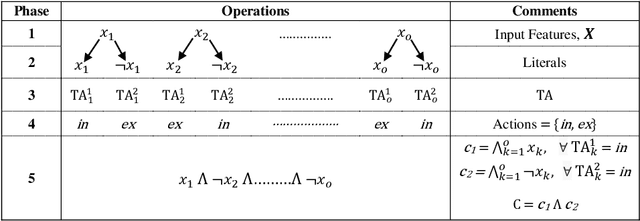
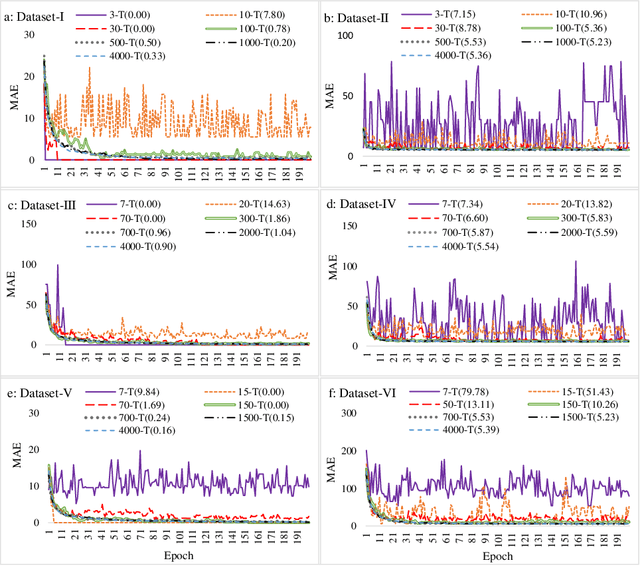
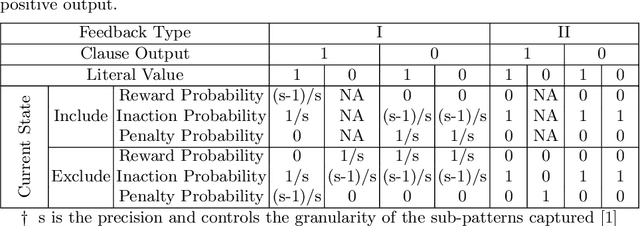
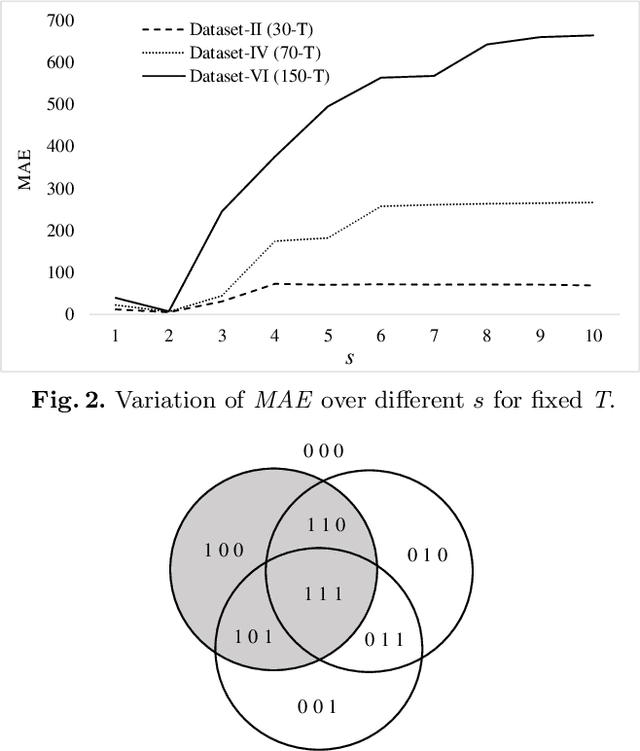
The recently introduced Tsetlin Machine (TM) has provided competitive pattern classification accuracy in several benchmarks, composing patterns with easy-to-interpret conjunctive clauses in propositional logic. In this paper, we go beyond pattern classification by introducing a new type of TMs, namely, the Regression Tsetlin Machine (RTM). In all brevity, we modify the inner inference mechanism of the TM so that input patterns are transformed into a single continuous output, rather than to distinct categories. We achieve this by: (1) using the conjunctive clauses of the TM to capture arbitrarily complex patterns; (2) mapping these patterns to a continuous output through a novel voting and normalization mechanism; and (3) employing a feedback scheme that updates the TM clauses to minimize the regression error. The feedback scheme uses a new activation probability function that stabilizes the updating of clauses, while the overall system converges towards an accurate input-output mapping. The performance of the proposed approach is evaluated using six different artificial datasets with and without noise. The performance of the RTM is compared with the Classical Tsetlin Machine (CTM) and the Multiclass Tsetlin Machine (MTM). Our empirical results indicate that the RTM obtains the best training and testing results for both noisy and noise-free datasets, with a smaller number of clauses. This, in turn, translates to higher regression accuracy, using significantly less computational resources.
A Scheme for Continuous Input to the Tsetlin Machine with Applications to Forecasting Disease Outbreaks
May 10, 2019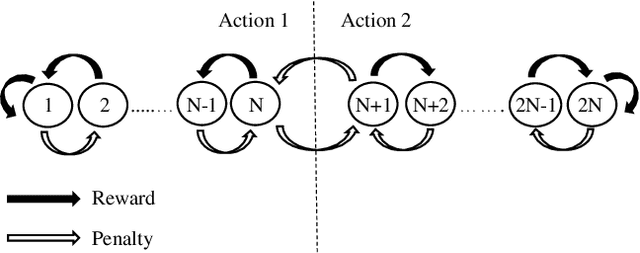
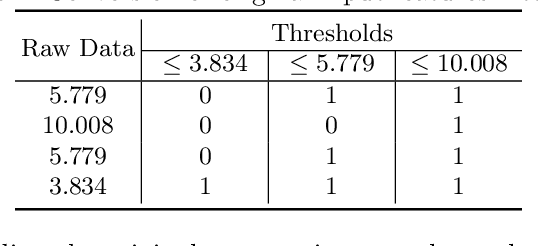
In this paper, we apply a new promising tool for pattern classification, namely, the Tsetlin Machine (TM), to the field of disease forecasting. The TM is interpretable because it is based on manipulating expressions in propositional logic, leveraging a large team of Tsetlin Automata (TA). Apart from being interpretable, this approach is attractive due to its low computational cost and its capacity to handle noise. To attack the problem of forecasting, we introduce a preprocessing method that extends the TM so that it can handle continuous input. Briefly stated, we convert continuous input into a binary representation based on thresholding. The resulting extended TM is evaluated and analyzed using an artificial dataset. The TM is further applied to forecast dengue outbreaks of all the seventeen regions in Philippines using the spatio-temporal properties of the data. Experimental results show that dengue outbreak forecasts made by the TM are more accurate than those obtained by a Support Vector Machine (SVM), Decision Trees (DTs), and several multi-layered Artificial Neural Networks (ANNs), both in terms of forecasting precision and F1-score.
The Dreaming Variational Autoencoder for Reinforcement Learning Environments
Oct 02, 2018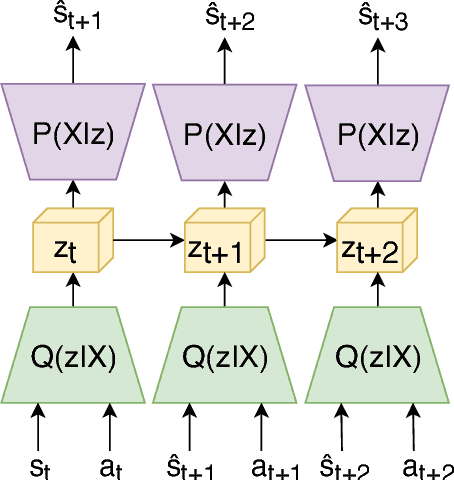

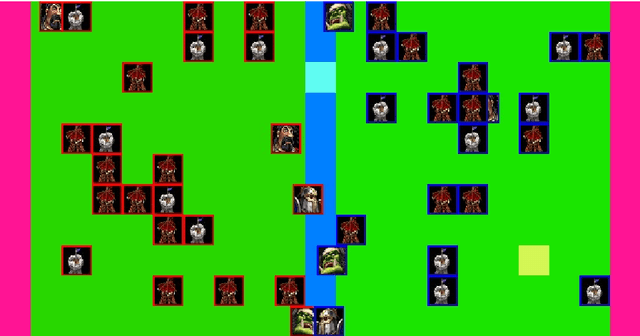
Reinforcement learning has shown great potential in generalizing over raw sensory data using only a single neural network for value optimization. There are several challenges in the current state-of-the-art reinforcement learning algorithms that prevent them from converging towards the global optima. It is likely that the solution to these problems lies in short- and long-term planning, exploration and memory management for reinforcement learning algorithms. Games are often used to benchmark reinforcement learning algorithms as they provide a flexible, reproducible, and easy to control environment. Regardless, few games feature a state-space where results in exploration, memory, and planning are easily perceived. This paper presents The Dreaming Variational Autoencoder (DVAE), a neural network based generative modeling architecture for exploration in environments with sparse feedback. We further present Deep Maze, a novel and flexible maze engine that challenges DVAE in partial and fully-observable state-spaces, long-horizon tasks, and deterministic and stochastic problems. We show initial findings and encourage further work in reinforcement learning driven by generative exploration.
Using the Tsetlin Machine to Learn Human-Interpretable Rules for High-Accuracy Text Categorization with Medical Applications
Sep 16, 2018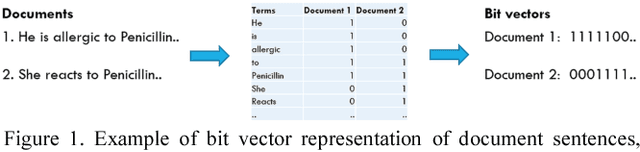
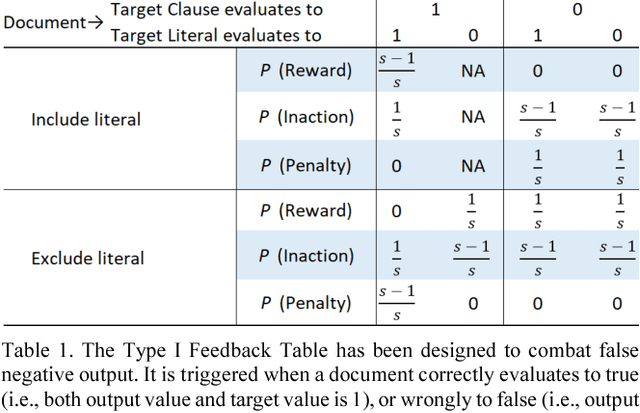
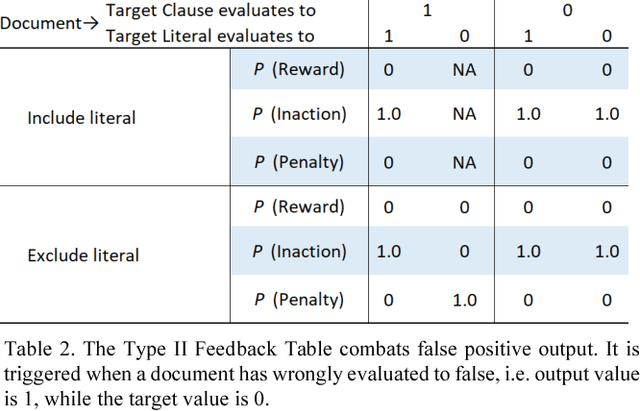
Medical applications challenge today's text categorization techniques by demanding both high accuracy and ease-of-interpretation. Although deep learning has provided a leap ahead in accuracy, this leap comes at the sacrifice of interpretability. To address this accuracy-interpretability challenge, we here introduce, for the first time, a text categorization approach that leverages the recently introduced Tsetlin Machine. In all brevity, we represent the terms of a text as propositional variables. From these, we capture categories using simple propositional formulae, such as: if "rash" and "reaction" and "penicillin" then Allergy. The Tsetlin Machine learns these formulae from a labelled text, utilizing conjunctive clauses to represent the particular facets of each category. Indeed, even the absence of terms (negated features) can be used for categorization purposes. Our empirical comparison with Na\"ive Bayes, decision trees, linear support vector machines (SVMs), random forest, long short-term memory (LSTM) neural networks, and other techniques, is quite conclusive. The Tsetlin Machine either performs on par with or outperforms all of the evaluated methods on both the 20 Newsgroups and IMDb datasets, as well as on a non-public clinical dataset. On average, the Tsetlin Machine delivers the best recall and precision scores across the datasets. Finally, our GPU implementation of the Tsetlin Machine executes 5 to 15 times faster than the CPU implementation, depending on the dataset. We thus believe that our novel approach can have a significant impact on a wide range of text analysis applications, forming a promising starting point for deeper natural language understanding with the Tsetlin Machine.
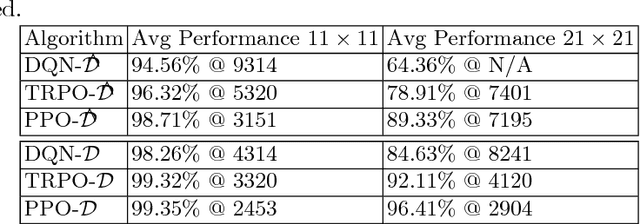
Deep RTS: A Game Environment for Deep Reinforcement Learning in Real-Time Strategy Games
Aug 15, 2018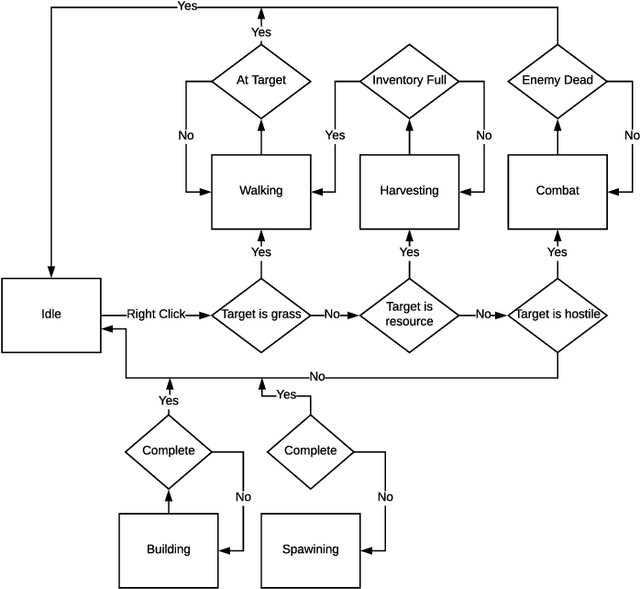
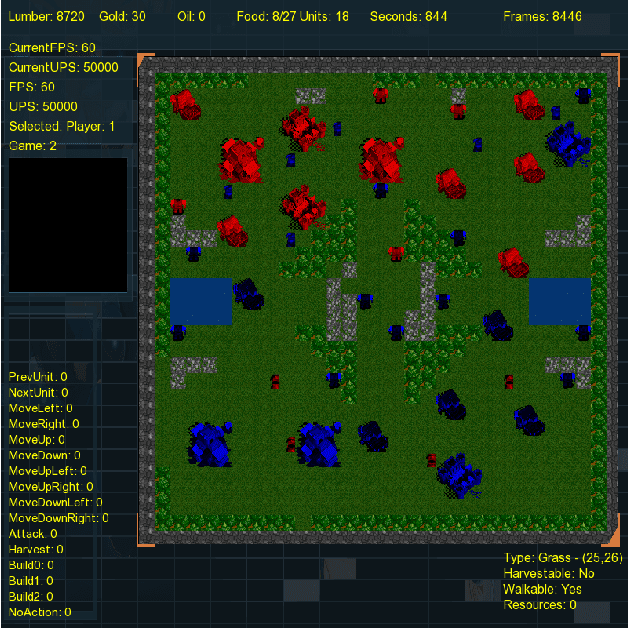
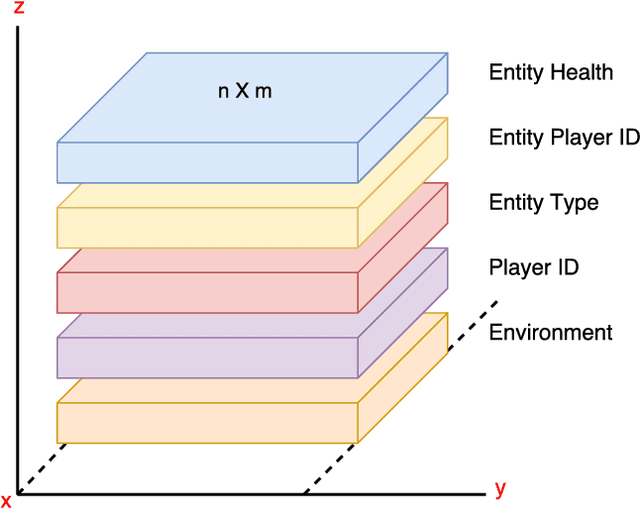
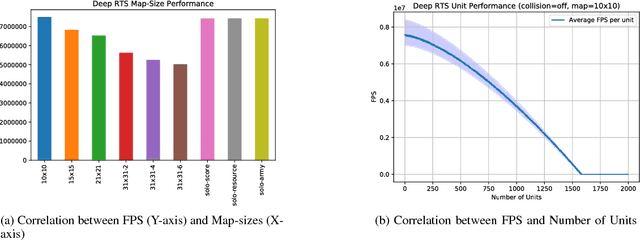
Reinforcement learning (RL) is an area of research that has blossomed tremendously in recent years and has shown remarkable potential for artificial intelligence based opponents in computer games. This success is primarily due to the vast capabilities of convolutional neural networks, that can extract useful features from noisy and complex data. Games are excellent tools to test and push the boundaries of novel RL algorithms because they give valuable insight into how well an algorithm can perform in isolated environments without the real-life consequences. Real-time strategy games (RTS) is a genre that has tremendous complexity and challenges the player in short and long-term planning. There is much research that focuses on applied RL in RTS games, and novel advances are therefore anticipated in the not too distant future. However, there are to date few environments for testing RTS AIs. Environments in the literature are often either overly simplistic, such as microRTS, or complex and without the possibility for accelerated learning on consumer hardware like StarCraft II. This paper introduces the Deep RTS game environment for testing cutting-edge artificial intelligence algorithms for RTS games. Deep RTS is a high-performance RTS game made specifically for artificial intelligence research. It supports accelerated learning, meaning that it can learn at a magnitude of 50 000 times faster compared to existing RTS games. Deep RTS has a flexible configuration, enabling research in several different RTS scenarios, including partially observable state-spaces and map complexity. We show that Deep RTS lives up to our promises by comparing its performance with microRTS, ELF, and StarCraft II on high-end consumer hardware. Using Deep RTS, we show that a Deep Q-Network agent beats random-play agents over 70% of the time. Deep RTS is publicly available at https://github.com/cair/DeepRTS.
The Tsetlin Machine - A Game Theoretic Bandit Driven Approach to Optimal Pattern Recognition with Propositional Logic
Apr 23, 2018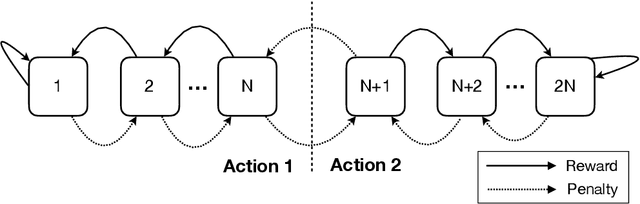
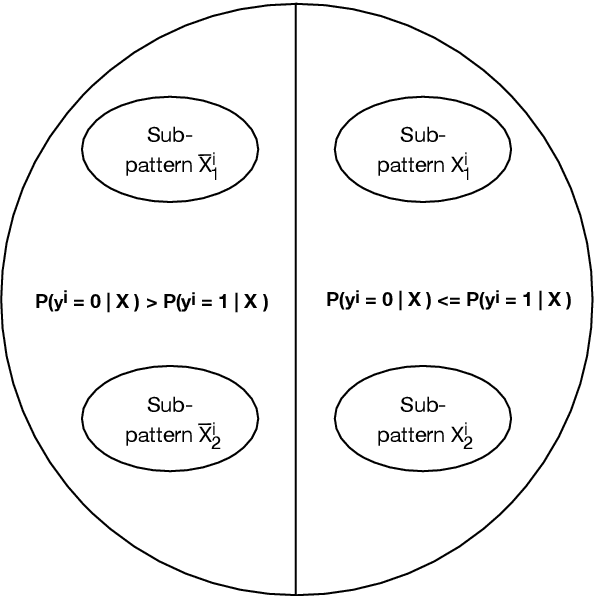

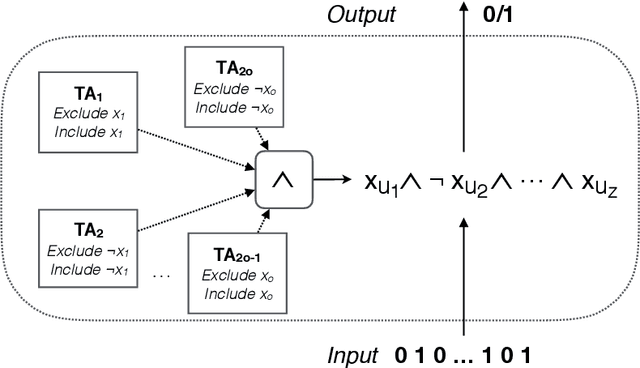
Although simple individually, artificial neurons provide state-of-the-art performance when interconnected in deep networks. Unknown to many, there exists an arguably even simpler and more versatile learning mechanism, namely, the Tsetlin Automaton. Merely by means of a single integer as memory, it learns the optimal action in stochastic environments. In this paper, we introduce the Tsetlin Machine, which solves complex pattern recognition problems with easy-to-interpret propositional formulas, composed by a collective of Tsetlin Automata. To eliminate the longstanding problem of vanishing signal-to-noise ratio, the Tsetlin Machine orchestrates the automata using a novel game. Our theoretical analysis establishes that the Nash equilibria of the game are aligned with the propositional formulas that provide optimal pattern recognition accuracy. This translates to learning without local optima, only global ones. We argue that the Tsetlin Machine finds the propositional formula that provides optimal accuracy, with probability arbitrarily close to unity. In four distinct benchmarks, the Tsetlin Machine outperforms both Neural Networks, SVMs, Random Forests, the Naive Bayes Classifier and Logistic Regression. It further turns out that the accuracy advantage of the Tsetlin Machine increases with lack of data. The Tsetlin Machine has a significant computational performance advantage since both inputs, patterns, and outputs are expressed as bits, while recognition of patterns relies on bit manipulation. The combination of accuracy, interpretability, and computational simplicity makes the Tsetlin Machine a promising tool for a wide range of domains, including safety-critical medicine. Being the first of its kind, we believe the Tsetlin Machine will kick-start completely new paths of research, with a potentially significant impact on the AI field and the applications of AI.
FlashRL: A Reinforcement Learning Platform for Flash Games
Jan 26, 2018
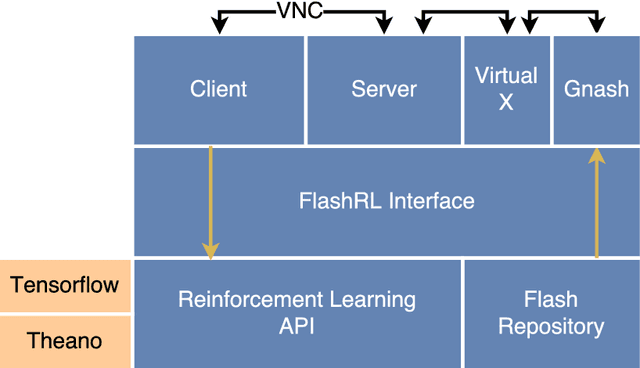

Reinforcement Learning (RL) is a research area that has blossomed tremendously in recent years and has shown remarkable potential in among others successfully playing computer games. However, there only exists a few game platforms that provide diversity in tasks and state-space needed to advance RL algorithms. The existing platforms offer RL access to Atari- and a few web-based games, but no platform fully expose access to Flash games. This is unfortunate because applying RL to Flash games have potential to push the research of RL algorithms. This paper introduces the Flash Reinforcement Learning platform (FlashRL) which attempts to fill this gap by providing an environment for thousands of Flash games on a novel platform for Flash automation. It opens up easy experimentation with RL algorithms for Flash games, which has previously been challenging. The platform shows excellent performance with as little as 5% CPU utilization on consumer hardware. It shows promising results for novel reinforcement learning algorithms.
Towards a Deep Reinforcement Learning Approach for Tower Line Wars
Dec 17, 2017
There have been numerous breakthroughs with reinforcement learning in the recent years, perhaps most notably on Deep Reinforcement Learning successfully playing and winning relatively advanced computer games. There is undoubtedly an anticipation that Deep Reinforcement Learning will play a major role when the first AI masters the complicated game plays needed to beat a professional Real-Time Strategy game player. For this to be possible, there needs to be a game environment that targets and fosters AI research, and specifically Deep Reinforcement Learning. Some game environments already exist, however, these are either overly simplistic such as Atari 2600 or complex such as Starcraft II from Blizzard Entertainment. We propose a game environment in between Atari 2600 and Starcraft II, particularly targeting Deep Reinforcement Learning algorithm research. The environment is a variant of Tower Line Wars from Warcraft III, Blizzard Entertainment. Further, as a proof of concept that the environment can harbor Deep Reinforcement algorithms, we propose and apply a Deep Q-Reinforcement architecture. The architecture simplifies the state space so that it is applicable to Q-learning, and in turn improves performance compared to current state-of-the-art methods. Our experiments show that the proposed architecture can learn to play the environment well, and score 33% better than standard Deep Q-learning which in turn proves the usefulness of the game environment.