Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart of Speech and Universal Dependency effects on English Arabic Machine Translation
Jun 03, 2021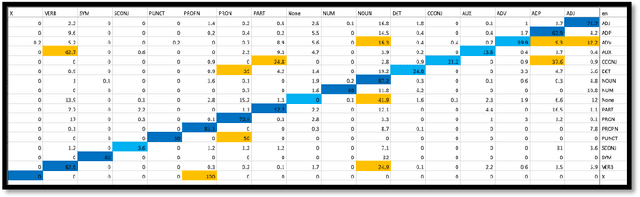
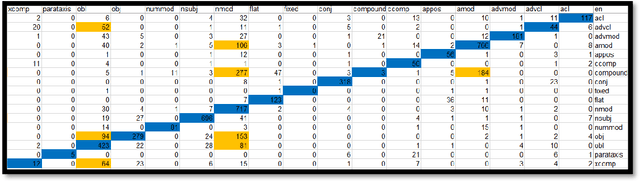
In this research paper, I will elaborate on a method to evaluate machine translation models based on their performance on underlying syntactical phenomena between English and Arabic languages. This method is especially important as such "neural" and "machine learning" are hard to fine-tune and change. Thus, finding a way to evaluate them easily and diversely would greatly help the task of bettering them.
* 19 pages
Via