 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMary Astell's words in A Serious Proposal to the Ladies , a lexicographic inquiry with NooJ
Dec 03, 2014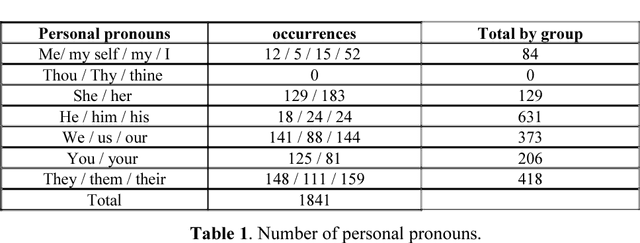
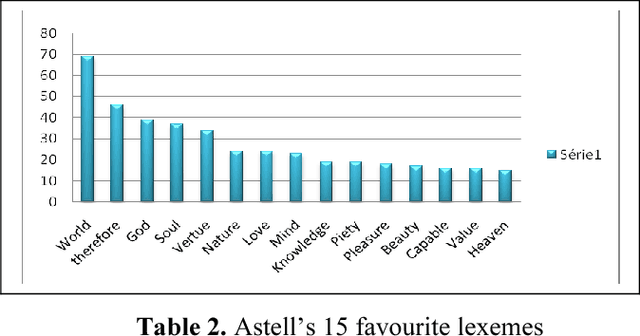
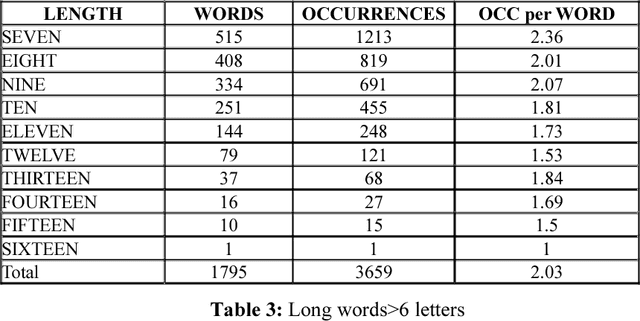
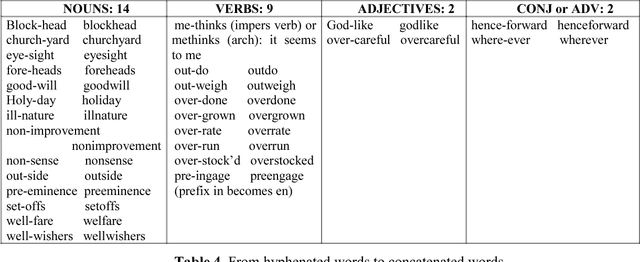
In the following article we elected to study with NooJ the lexis of a 17 th century text, Mary Astell's seminal essay, A Serious Proposal to the Ladies, part I, published in 1694. We first focused on the semantics to see how Astell builds her vindication of the female sex, which words she uses to sensitise women to their alienated condition and promote their education. Then we studied the morphology of the lexemes (which is different from contemporary English) used by the author, thanks to the NooJ tools we have devised for this purpose. NooJ has great functionalities for lexicographic work. Its commands and graphs prove to be most efficient in the spotting of archaic words or variants in spelling. Introduction In our previous articles, we have studied the singularities of 17 th century English within the framework of a diachronic analysis thanks to syntactical and morphological graphs and thanks to the dictionaries we have compiled from a corpus that may be expanded overtime. Our early work was based on a limited corpus of English travel literature to Greece in the 17 th century. This article deals with a late seventeenth century text written by a woman philosopher and essayist, Mary Astell (1666--1731), considered as one of the first English feminists. Astell wrote her essay at a time in English history when women were "the weaker vessel" and their main business in life was to charm and please men by their looks and submissiveness. In this essay we will see how NooJ can help us analyse Astell's rhetoric (what point of view does she adopt, does she speak in her own name, in the name of all women, what is her representation of men and women and their relationships in the text, what are the goals of education?). Then we will turn our attention to the morphology of words in the text and use NooJ commands and graphs to carry out a lexicographic inquiry into Astell's lexemes.
Automatic transcription of 17th century English text in Contemporary English with NooJ: Method and Evaluation
Sep 22, 2011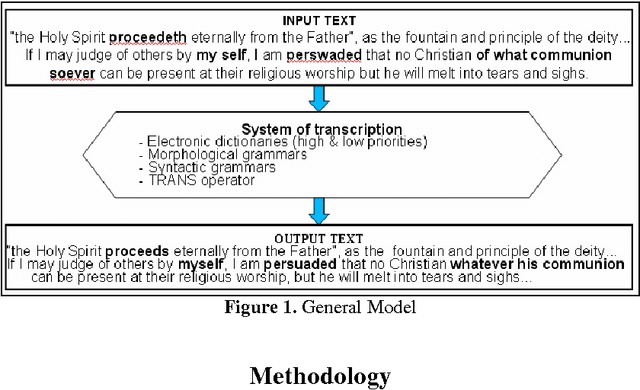
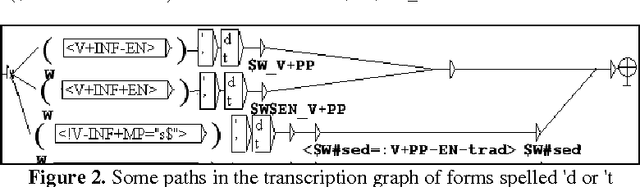
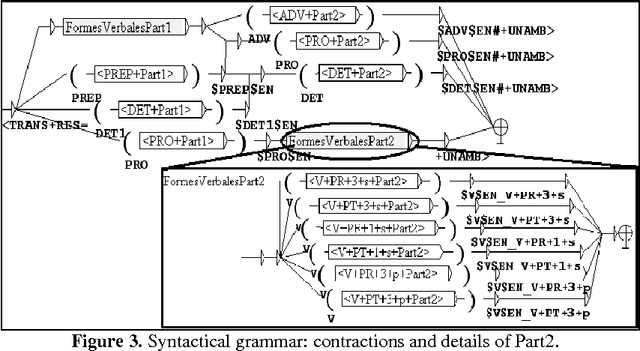
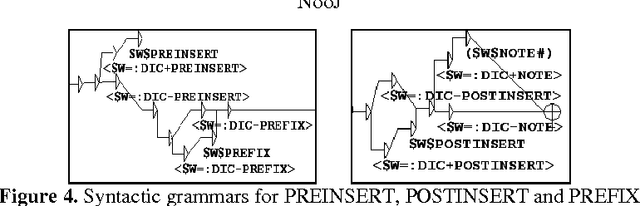
Since 2006 we have undertaken to describe the differences between 17th century English and contemporary English thanks to NLP software. Studying a corpus spanning the whole century (tales of English travellers in the Ottoman Empire in the 17th century, Mary Astell's essay A Serious Proposal to the Ladies and other literary texts) has enabled us to highlight various lexical, morphological or grammatical singularities. Thanks to the NooJ linguistic platform, we created dictionaries indexing the lexical variants and their transcription in CE. The latter is often the result of the validation of forms recognized dynamically by morphological graphs. We also built syntactical graphs aimed at transcribing certain archaic forms in contemporary English. Our previous research implied a succession of elementary steps alternating textual analysis and result validation. We managed to provide examples of transcriptions, but we have not created a global tool for automatic transcription. Therefore we need to focus on the results we have obtained so far, study the conditions for creating such a tool, and analyze possible difficulties. In this paper, we will be discussing the technical and linguistic aspects we have not yet covered in our previous work. We are using the results of previous research and proposing a transcription method for words or sequences identified as archaic.
Recognition and translation Arabic-French of Named Entities: case of the Sport places
May 31, 2010
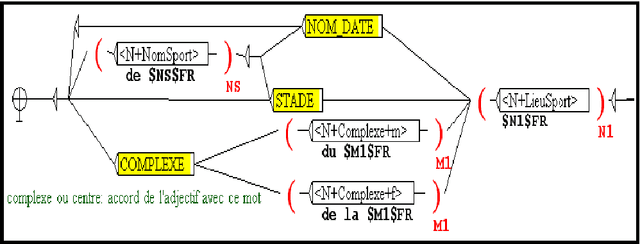
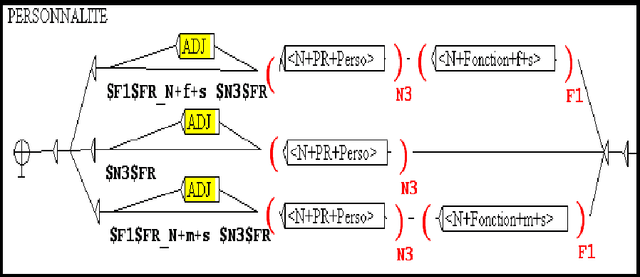

The recognition of Arabic Named Entities (NE) is a problem in different domains of Natural Language Processing (NLP) like automatic translation. Indeed, NE translation allows the access to multilingual in-formation. This translation doesn't always lead to expected result especially when NE contains a person name. For this reason and in order to ameliorate translation, we can transliterate some part of NE. In this context, we propose a method that integrates translation and transliteration together. We used the linguis-tic NooJ platform that is based on local grammars and transducers. In this paper, we focus on sport domain. We will firstly suggest a refinement of the typological model presented at the MUC Conferences we will describe the integration of an Arabic transliteration module into translation system. Finally, we will detail our method and give the results of the evaluation.
Morphological study of Albanian words, and processing with NooJ
Feb 02, 2010
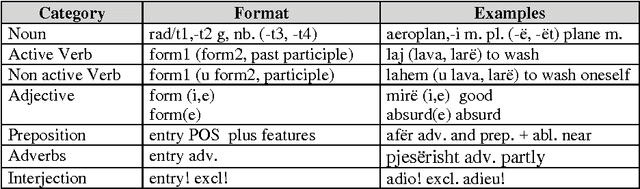
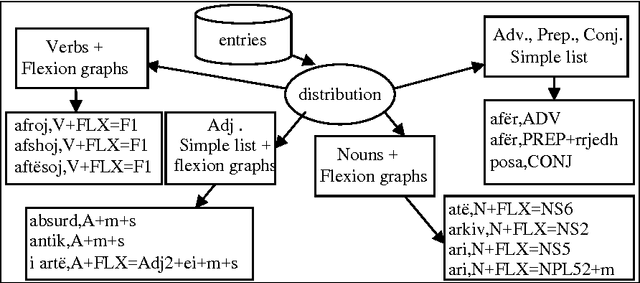
We are developing electronic dictionaries and transducers for the automatic processing of the Albanian Language. We will analyze the words inside a linear segment of text. We will also study the relationship between units of sense and units of form. The composition of words takes different forms in Albanian. We have found that morphemes are frequently concatenated or simply juxtaposed or contracted. The inflected grammar of NooJ allows constructing the dictionaries of flexed forms (declensions or conjugations). The diversity of word structures requires tools to identify words created by simple concatenation, or to treat contractions. The morphological tools of NooJ allow us to create grammatical tools to represent and treat these phenomena. But certain problems exceed the morphological analysis and must be represented by syntactical grammars.
"Mind your p's and q's": or the peregrinations of an apostrophe in 17th Century English
Feb 02, 2010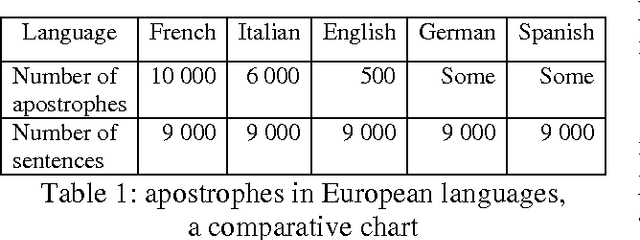
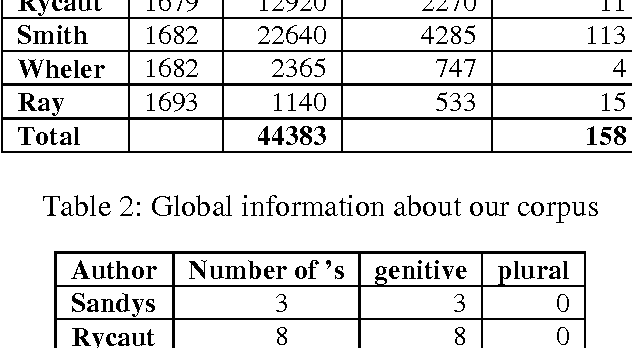
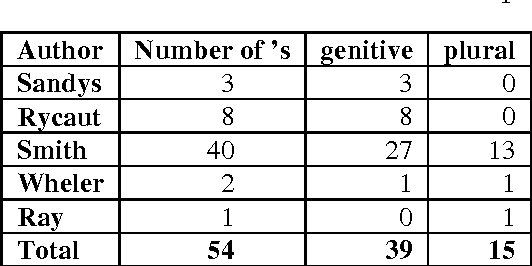

If the use of the apostrophe in contemporary English often marks the Saxon genitive, it may also indicate the omission of one or more let-ters. Some writers (wrongly?) use it to mark the plural in symbols or abbreviations, visual-ised thanks to the isolation of the morpheme "s". This punctuation mark was imported from the Continent in the 16th century. During the 19th century its use was standardised. However the rules of its usage still seem problematic to many, including literate speakers of English. "All too often, the apostrophe is misplaced", or "errant apostrophes are springing up every-where" is a complaint that Internet users fre-quently come across when visiting grammar websites. Many of them detail its various uses and misuses, and attempt to correct the most common mistakes about it, especially its mis-use in the plural, called greengrocers' apostro-phes and humorously misspelled "greengro-cers apostrophe's". While studying English travel accounts published in the seventeenth century, we noticed that the different uses of this symbol may accompany various models of metaplasms. We were able to highlight the linguistic variations of some lexemes, and trace the origin of modern grammar rules gov-erning its usage.
Étude et traitement automatique de l'anglais du XVIIe siècle : outils morphosyntaxiques et dictionnaires
Feb 02, 2010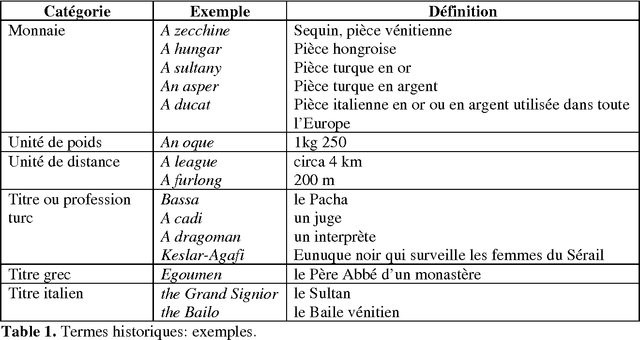
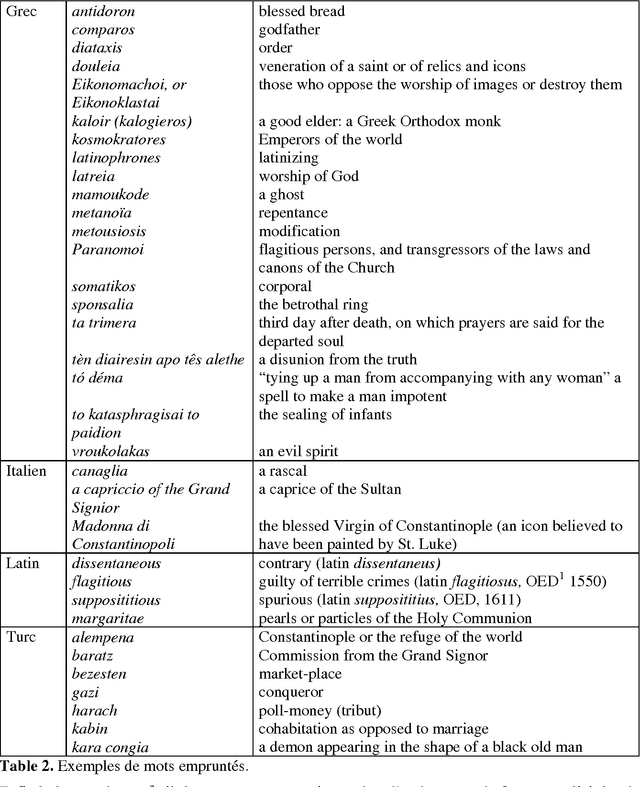
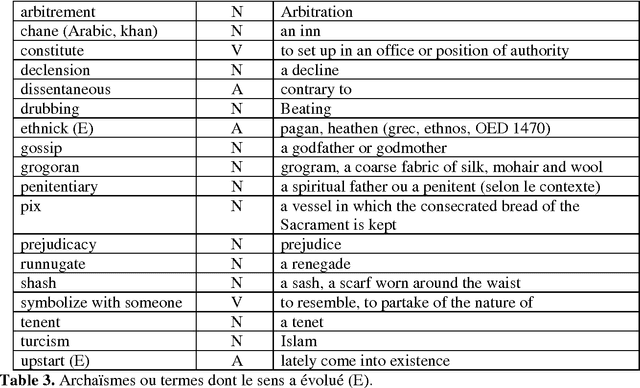

In this article, we record the main linguistic differences or singularities of 17th century English, analyse them morphologically and syntactically and propose equivalent forms in contemporary English. We show how 17th century texts may be transcribed into modern English, combining the use of electronic dictionaries with rules of transcription implemented as transducers. Apr\`es avoir expos\'e la constitution du corpus, nous recensons les principales diff\'erences ou particularit\'es linguistiques de la langue anglaise du XVIIe si\`ecle, les analysons du point de vue morphologique et syntaxique et proposons des \'equivalents en anglais contemporain (AC). Nous montrons comment nous pouvons effectuer une transcription automatique de textes anglais du XVIIe si\`ecle en anglais moderne, en combinant l'utilisation de dictionnaires \'electroniques avec des r\`egles de transcriptions impl\'ement\'ees sous forme de transducteurs.