 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA prototype for projecting HPSG syntactic lexica towards LMF
Aug 31, 2012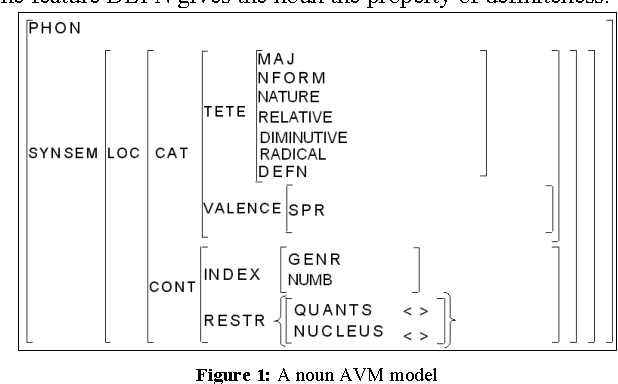
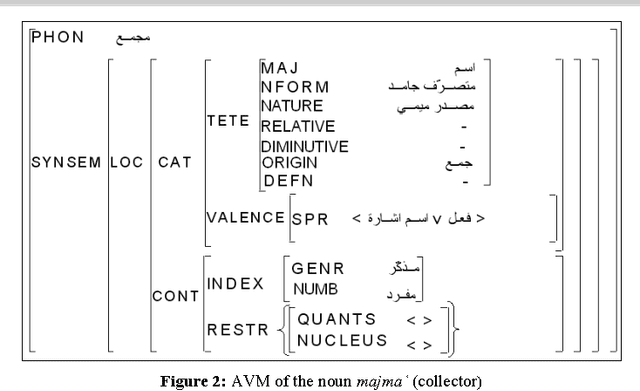
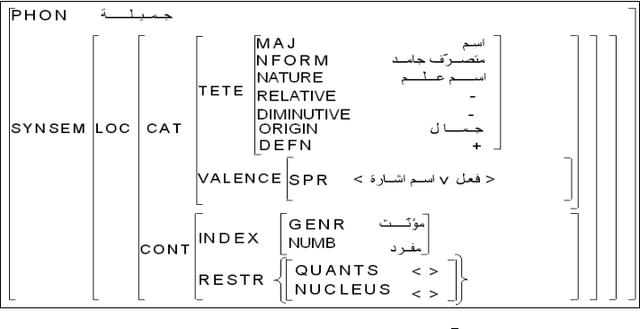
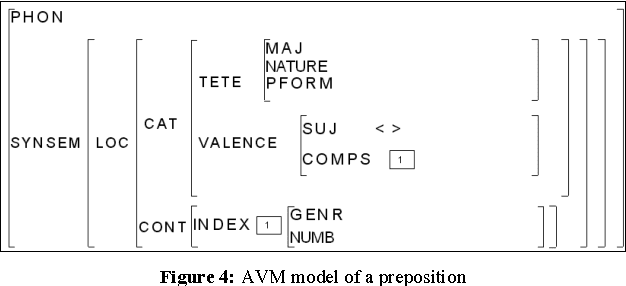
The comparative evaluation of Arabic HPSG grammar lexica requires a deep study of their linguistic coverage. The complexity of this task results mainly from the heterogeneity of the descriptive components within those lexica (underlying linguistic resources and different data categories, for example). It is therefore essential to define more homogeneous representations, which in turn will enable us to compare them and eventually merge them. In this context, we present a method for comparing HPSG lexica based on a rule system. This method is implemented within a prototype for the projection from Arabic HPSG to a normalised pivot language compliant with LMF (ISO 24613 - Lexical Markup Framework) and serialised using a TEI (Text Encoding Initiative) based representation. The design of this system is based on an initial study of the HPSG formalism looking at its adequacy for the representation of Arabic, and from this, we identify the appropriate feature structures corresponding to each Arabic lexical category and their possible LMF counterparts.
Recognition and translation Arabic-French of Named Entities: case of the Sport places
May 31, 2010
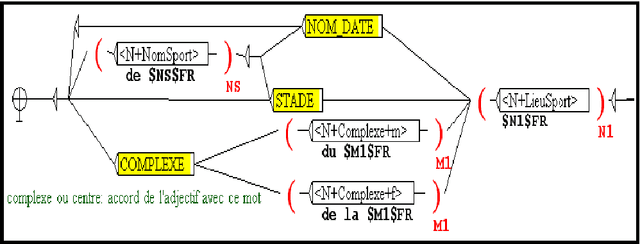
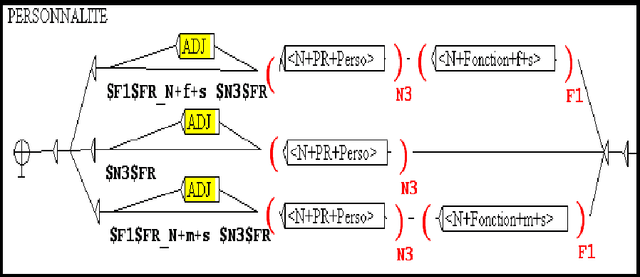

The recognition of Arabic Named Entities (NE) is a problem in different domains of Natural Language Processing (NLP) like automatic translation. Indeed, NE translation allows the access to multilingual in-formation. This translation doesn't always lead to expected result especially when NE contains a person name. For this reason and in order to ameliorate translation, we can transliterate some part of NE. In this context, we propose a method that integrates translation and transliteration together. We used the linguis-tic NooJ platform that is based on local grammars and transducers. In this paper, we focus on sport domain. We will firstly suggest a refinement of the typological model presented at the MUC Conferences we will describe the integration of an Arabic transliteration module into translation system. Finally, we will detail our method and give the results of the evaluation.