 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMineTheGap: Automatic Mining of Biases in Text-to-Image Models
Dec 15, 2025Text-to-Image (TTI) models generate images based on text prompts, which often leave certain aspects of the desired image ambiguous. When faced with these ambiguities, TTI models have been shown to exhibit biases in their interpretations. These biases can have societal impacts, e.g., when showing only a certain race for a stated occupation. They can also affect user experience when creating redundancy within a set of generated images instead of spanning diverse possibilities. Here, we introduce MineTheGap - a method for automatically mining prompts that cause a TTI model to generate biased outputs. Our method goes beyond merely detecting bias for a given prompt. Rather, it leverages a genetic algorithm to iteratively refine a pool of prompts, seeking for those that expose biases. This optimization process is driven by a novel bias score, which ranks biases according to their severity, as we validate on a dataset with known biases. For a given prompt, this score is obtained by comparing the distribution of generated images to the distribution of LLM-generated texts that constitute variations on the prompt. Code and examples are available on the project's webpage.
Stealing Image-to-Image Translation Models With a Single Query
Jun 02, 2024Training deep neural networks requires significant computational resources and large datasets that are often confidential or expensive to collect. As a result, owners tend to protect their models by allowing access only via an API. Many works demonstrated the possibility of stealing such protected models by repeatedly querying the API. However, to date, research has predominantly focused on stealing classification models, for which a very large number of queries has been found necessary. In this paper, we study the possibility of stealing image-to-image models. Surprisingly, we find that many such models can be stolen with as little as a single, small-sized, query image using simple distillation. We study this phenomenon on a wide variety of model architectures, datasets, and tasks, including denoising, deblurring, deraining, super-resolution, and biological image-to-image translation. Remarkably, we find that the vulnerability to stealing attacks is shared by CNNs and by models with attention mechanisms, and that stealing is commonly possible even without knowing the architecture of the target model.
GAN Steerability without optimization
Dec 09, 2020
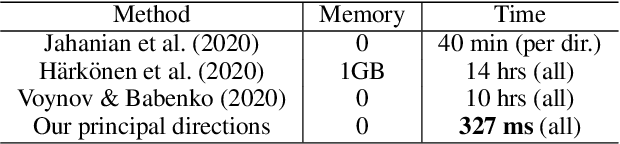
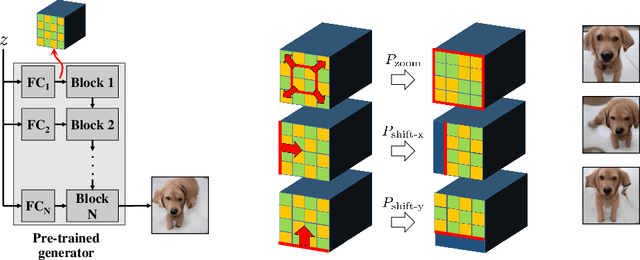
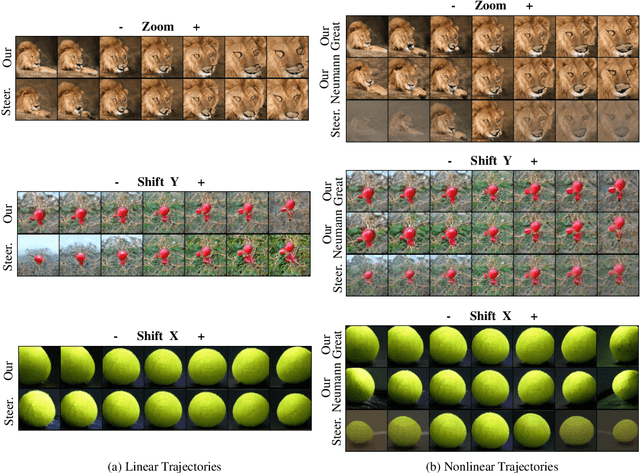
Recent research has shown remarkable success in revealing "steering" directions in the latent spaces of pre-trained GANs. These directions correspond to semantically meaningful image transformations e.g., shift, zoom, color manipulations), and have similar interpretable effects across all categories that the GAN can generate. Some methods focus on user-specified transformations, while others discover transformations in an unsupervised manner. However, all existing techniques rely on an optimization procedure to expose those directions, and offer no control over the degree of allowed interaction between different transformations. In this paper, we show that "steering" trajectories can be computed in closed form directly from the generator's weights without any form of training or optimization. This applies to user-prescribed geometric transformations, as well as to unsupervised discovery of more complex effects. Our approach allows determining both linear and nonlinear trajectories, and has many advantages over previous methods. In particular, we can control whether one transformation is allowed to come on the expense of another (e.g. zoom-in with or without allowing translation to keep the object centered). Moreover, we can determine the natural end-point of the trajectory, which corresponds to the largest extent to which a transformation can be applied without incurring degradation. Finally, we show how transferring attributes between images can be achieved without optimization, even across different categories.