 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy of Phonemes Confusions in Hierarchical Automatic Phoneme Recognition System
Aug 07, 2015
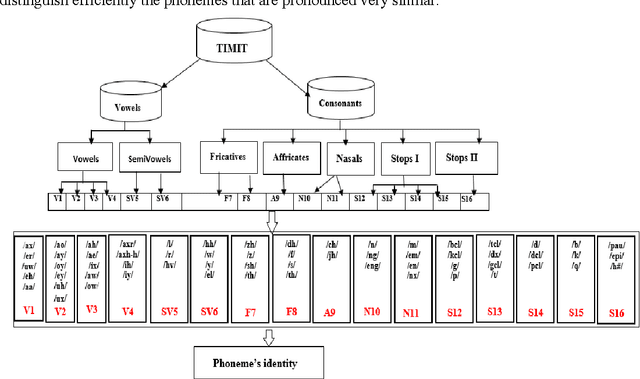
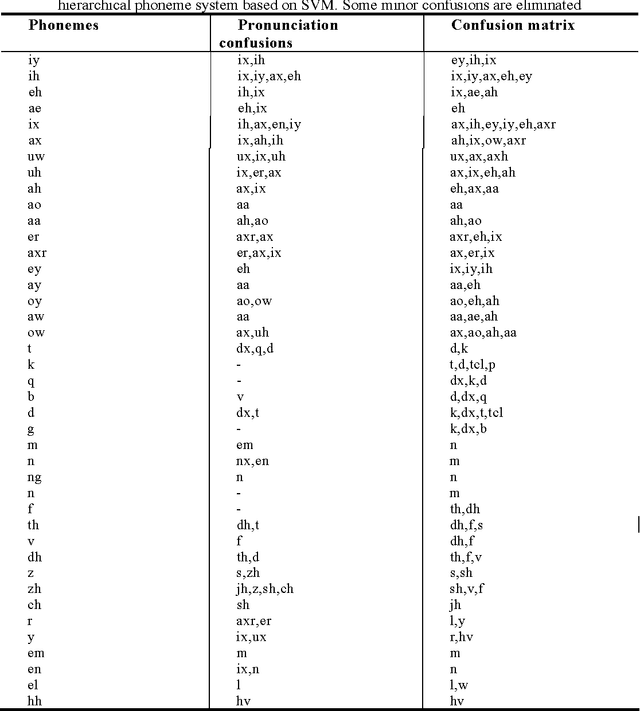
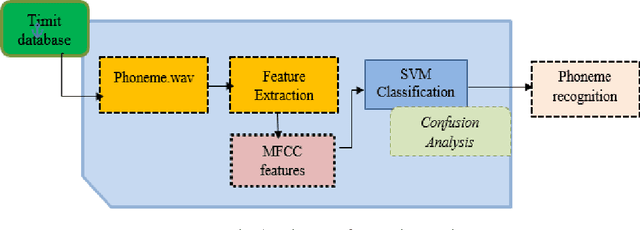
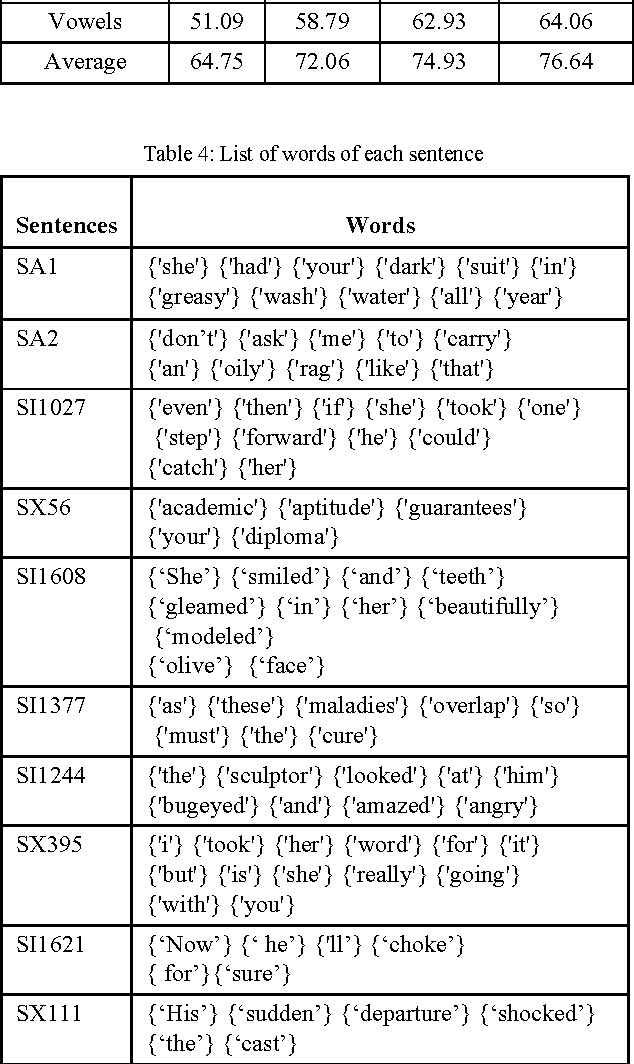
In this paper, we have analyzed the impact of confusions on the robustness of phoneme recognitions system. The confusions are detected at the pronunciation and the confusions matrices of the phoneme recognizer. The confusions show that some similarities between phonemes at the pronunciation affect significantly the recognition rates. This paper proposes to understand those confusions in order to improve the performance of the phoneme recognition system by isolating the problematic phonemes. Confusion analysis leads to build a new hierarchical recognizer using new phoneme distribution and the information from the confusion matrices. This new hierarchical phoneme recognition system shows significant improvements of the recognition rates on TIMIT database.
The challenges of SVM optimization using Adaboost on a phoneme recognition problem
Jul 22, 2015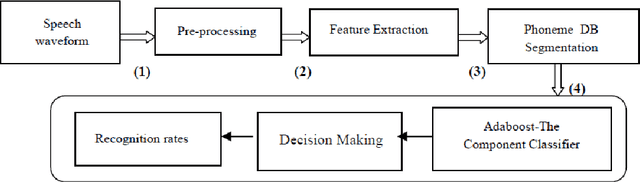
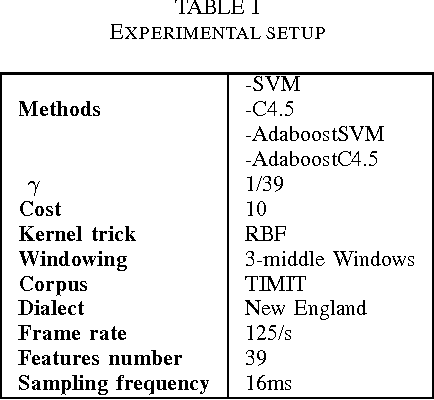
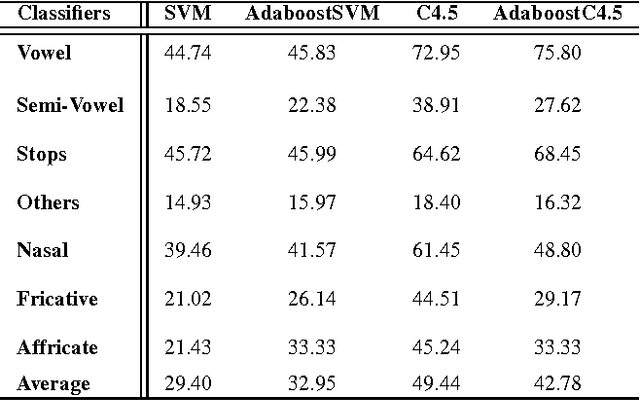
The use of digital technology is growing at a very fast pace which led to the emergence of systems based on the cognitive infocommunications. The expansion of this sector impose the use of combining methods in order to ensure the robustness in cognitive systems.
An Empirical Comparison of SVM and Some Supervised Learning Algorithms for Vowel recognition
Jul 22, 2015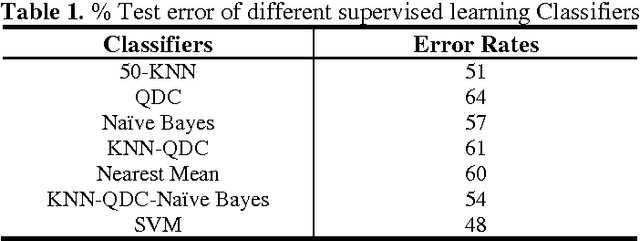

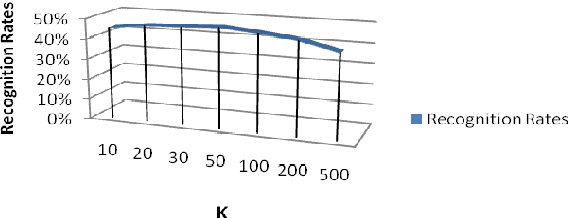
In this article, we conduct a study on the performance of some supervised learning algorithms for vowel recognition. This study aims to compare the accuracy of each algorithm. Thus, we present an empirical comparison between five supervised learning classifiers and two combined classifiers: SVM, KNN, Naive Bayes, Quadratic Bayes Normal (QDC) and Nearst Mean. Those algorithms were tested for vowel recognition using TIMIT Corpus and Mel-frequency cepstral coefficients (MFCCs).
Practical Selection of SVM Supervised Parameters with Different Feature Representations for Vowel Recognition
Jul 22, 2015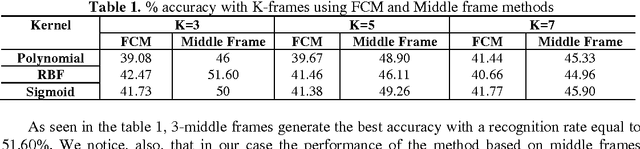
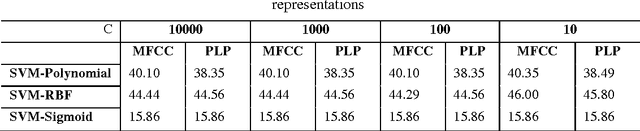
It is known that the classification performance of Support Vector Machine (SVM) can be conveniently affected by the different parameters of the kernel tricks and the regularization parameter, C. Thus, in this article, we propose a study in order to find the suitable kernel with which SVM may achieve good generalization performance as well as the parameters to use. We need to analyze the behavior of the SVM classifier when these parameters take very small or very large values. The study is conducted for a multi-class vowel recognition using the TIMIT corpus. Furthermore, for the experiments, we used different feature representations such as MFCC and PLP. Finally, a comparative study was done to point out the impact of the choice of the parameters, kernel trick and feature representations on the performance of the SVM classifier
Improved Frame Level Features and SVM Supervectors Approach for the Recogniton of Emotional States from Speech: Application to categorical and dimensional states
Jun 23, 2014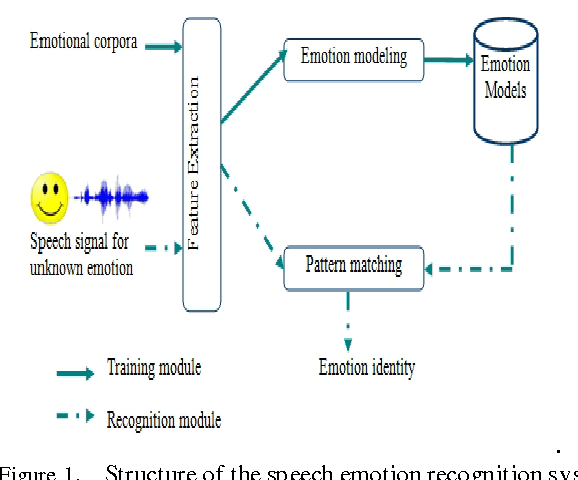
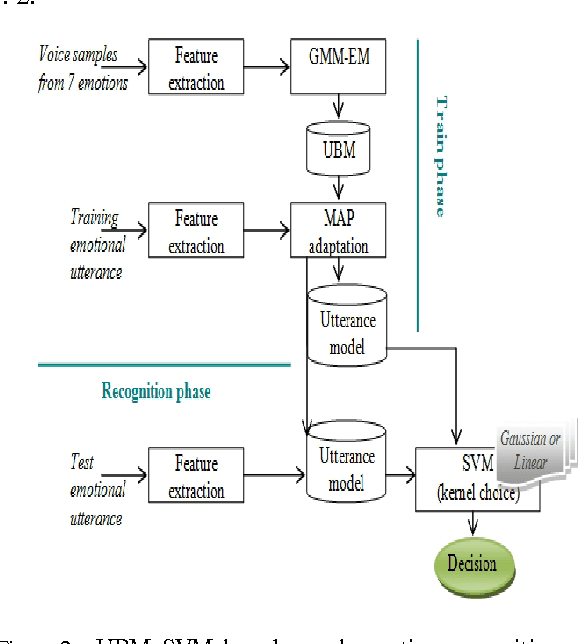

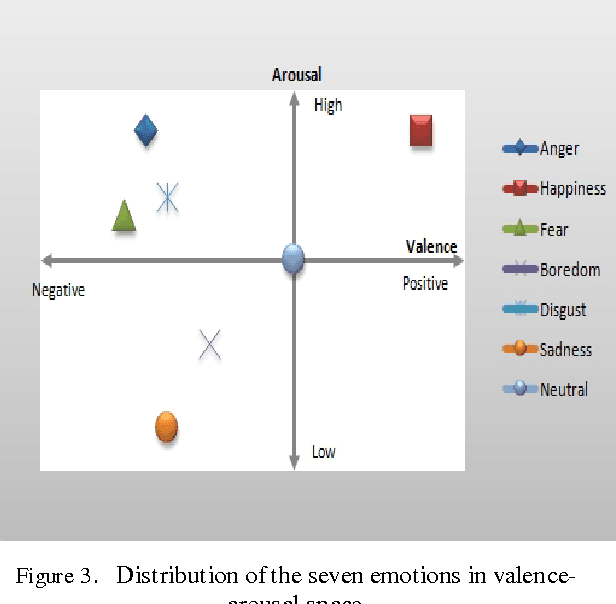
The purpose of speech emotion recognition system is to classify speakers utterances into different emotional states such as disgust, boredom, sadness, neutral and happiness. Speech features that are commonly used in speech emotion recognition rely on global utterance level prosodic features. In our work, we evaluate the impact of frame level feature extraction. The speech samples are from Berlin emotional database and the features extracted from these utterances are energy, different variant of mel frequency cepstrum coefficients, velocity and acceleration features.
Spike Timing Dependent Competitive Learning in Recurrent Self Organizing Pulsed Neural Networks Case Study: Phoneme and Word Recognition
Sep 24, 2012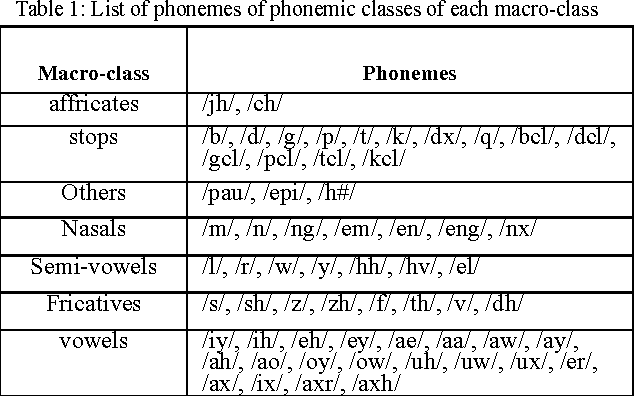
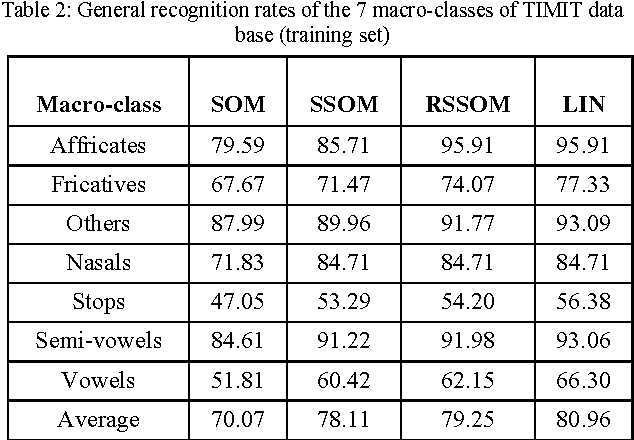
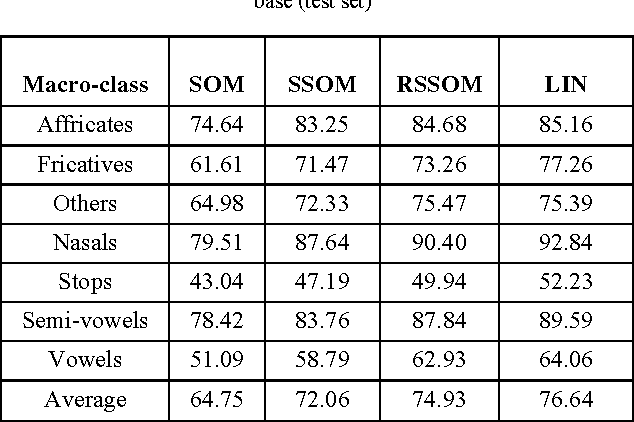
Synaptic plasticity seems to be a capital aspect of the dynamics of neural networks. It is about the physiological modifications of the synapse, which have like consequence a variation of the value of the synaptic weight. The information encoding is based on the precise timing of single spike events that is based on the relative timing of the pre- and post-synaptic spikes, local synapse competitions within a single neuron and global competition via lateral connections. In order to classify temporal sequences, we present in this paper how to use a local hebbian learning, spike-timing dependent plasticity for unsupervised competitive learning, preserving self-organizing maps of spiking neurons. In fact we present three variants of self-organizing maps (SOM) with spike-timing dependent Hebbian learning rule, the Leaky Integrators Neurons (LIN), the Spiking_SOM and the recurrent Spiking_SOM (RSSOM) models. The case study of the proposed SOM variants is phoneme classification and word recognition in continuous speech and speaker independent.
* 10 pages, 15 tables