 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe challenges of SVM optimization using Adaboost on a phoneme recognition problem
Jul 22, 2015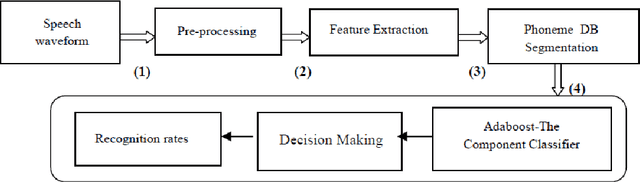
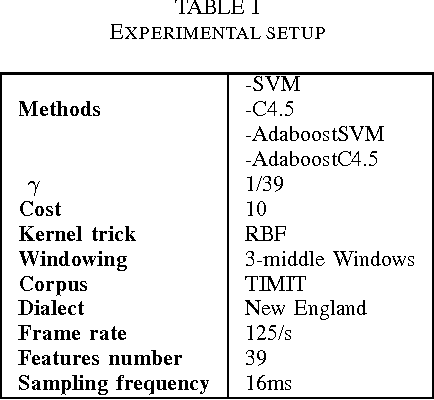
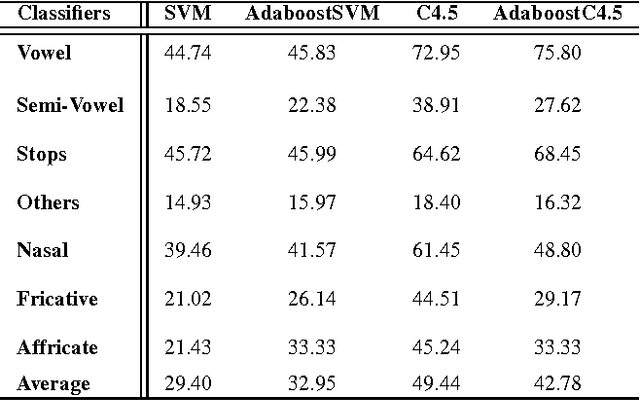
The use of digital technology is growing at a very fast pace which led to the emergence of systems based on the cognitive infocommunications. The expansion of this sector impose the use of combining methods in order to ensure the robustness in cognitive systems.
Incorporating Belief Function in SVM for Phoneme Recognition
Jul 22, 2015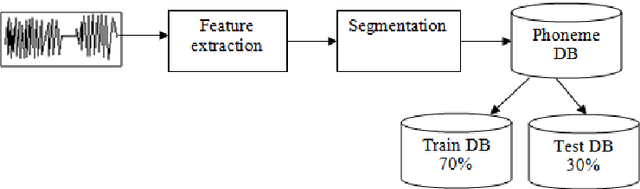
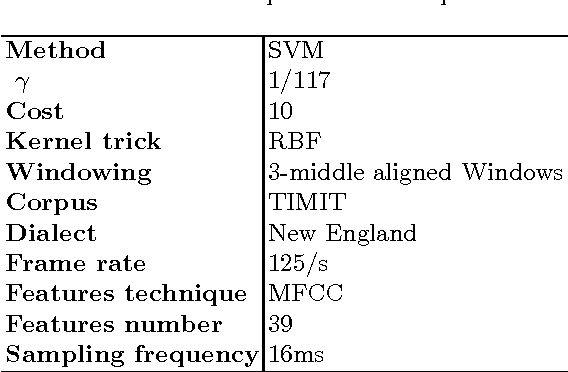
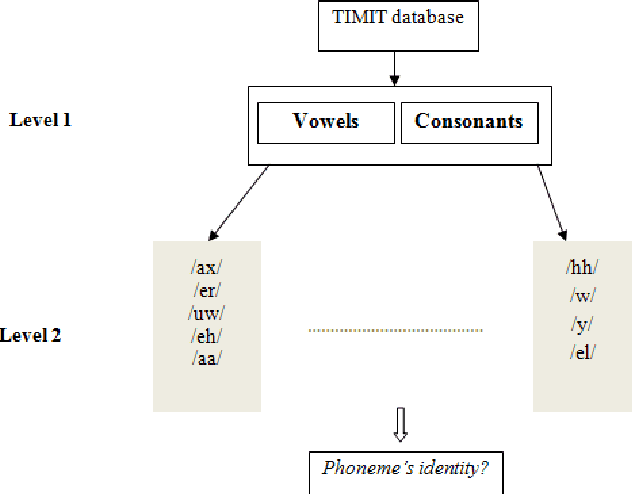
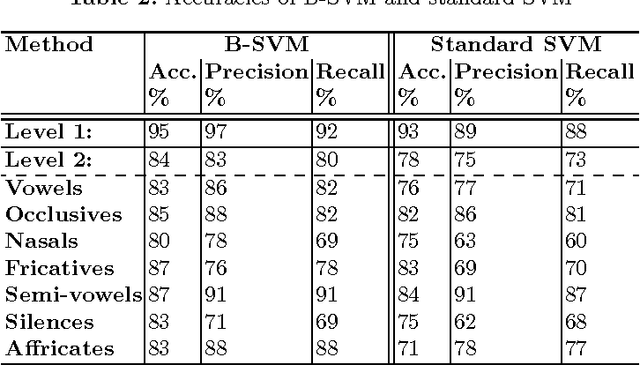
The Support Vector Machine (SVM) method has been widely used in numerous classification tasks. The main idea of this algorithm is based on the principle of the margin maximization to find an hyperplane which separates the data into two different classes.In this paper, SVM is applied to phoneme recognition task. However, in many real-world problems, each phoneme in the data set for recognition problems may differ in the degree of significance due to noise, inaccuracies, or abnormal characteristics; All those problems can lead to the inaccuracies in the prediction phase. Unfortunately, the standard formulation of SVM does not take into account all those problems and, in particular, the variation in the speech input. This paper presents a new formulation of SVM (B-SVM) that attributes to each phoneme a confidence degree computed based on its geometric position in the space. Then, this degree is used in order to strengthen the class membership of the tested phoneme. Hence, we introduce a reformulation of the standard SVM that incorporates the degree of belief. Experimental performance on TIMIT database shows the effectiveness of the proposed method B-SVM on a phoneme recognition problem.
* 9th International Conference, Hybrid Artificial Intelligence Systems, Salamanca, Spain, June 11-13, 2014
An Empirical Comparison of SVM and Some Supervised Learning Algorithms for Vowel recognition
Jul 22, 2015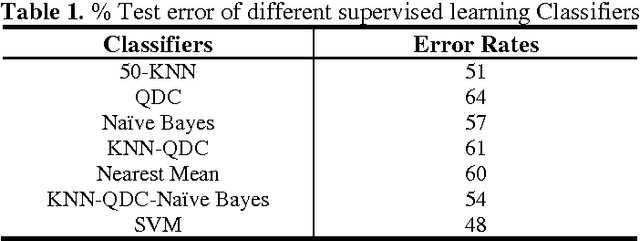

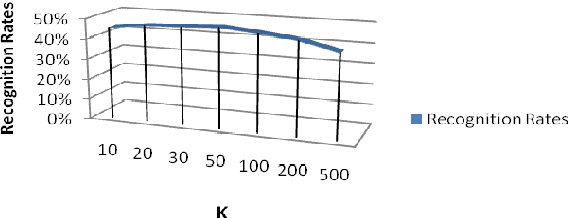
In this article, we conduct a study on the performance of some supervised learning algorithms for vowel recognition. This study aims to compare the accuracy of each algorithm. Thus, we present an empirical comparison between five supervised learning classifiers and two combined classifiers: SVM, KNN, Naive Bayes, Quadratic Bayes Normal (QDC) and Nearst Mean. Those algorithms were tested for vowel recognition using TIMIT Corpus and Mel-frequency cepstral coefficients (MFCCs).
Practical Selection of SVM Supervised Parameters with Different Feature Representations for Vowel Recognition
Jul 22, 2015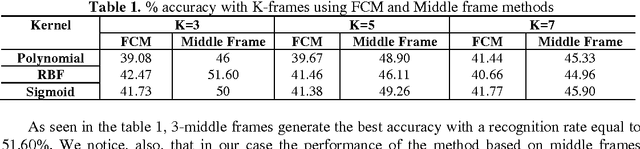
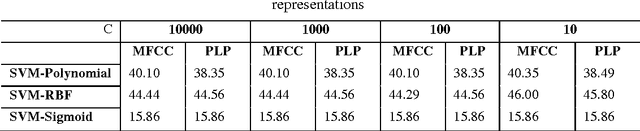
It is known that the classification performance of Support Vector Machine (SVM) can be conveniently affected by the different parameters of the kernel tricks and the regularization parameter, C. Thus, in this article, we propose a study in order to find the suitable kernel with which SVM may achieve good generalization performance as well as the parameters to use. We need to analyze the behavior of the SVM classifier when these parameters take very small or very large values. The study is conducted for a multi-class vowel recognition using the TIMIT corpus. Furthermore, for the experiments, we used different feature representations such as MFCC and PLP. Finally, a comparative study was done to point out the impact of the choice of the parameters, kernel trick and feature representations on the performance of the SVM classifier
On the Use of Different Feature Extraction Methods for Linear and Non Linear kernels
Jun 27, 2014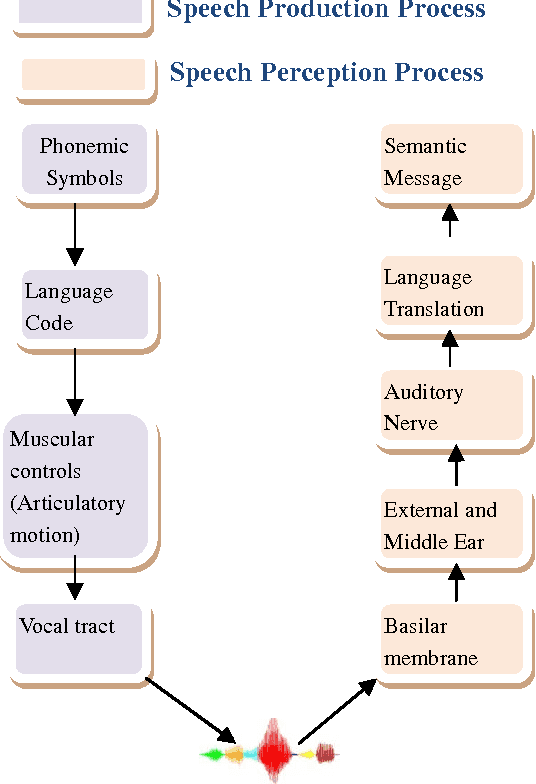

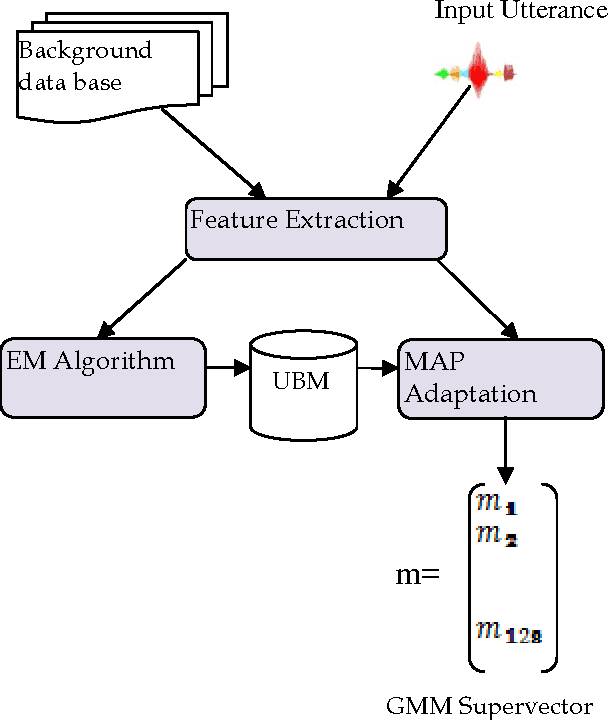
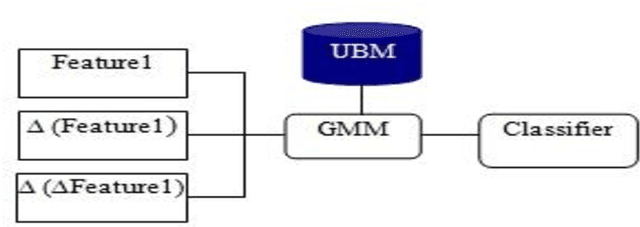
The speech feature extraction has been a key focus in robust speech recognition research; it significantly affects the recognition performance. In this paper, we first study a set of different features extraction methods such as linear predictive coding (LPC), mel frequency cepstral coefficient (MFCC) and perceptual linear prediction (PLP) with several features normalization techniques like rasta filtering and cepstral mean subtraction (CMS). Based on this, a comparative evaluation of these features is performed on the task of text independent speaker identification using a combination between gaussian mixture models (GMM) and linear and non-linear kernels based on support vector machine (SVM).
A Multi Level Data Fusion Approach for Speaker Identification on Telephone Speech
Jun 27, 2014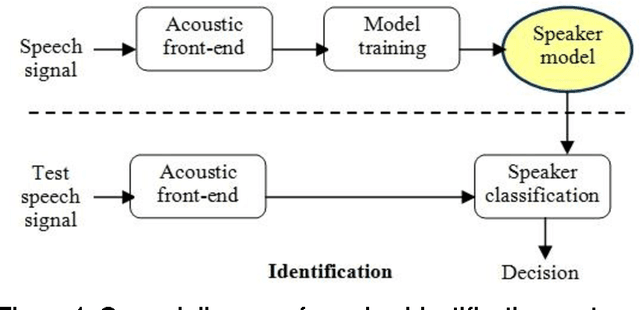
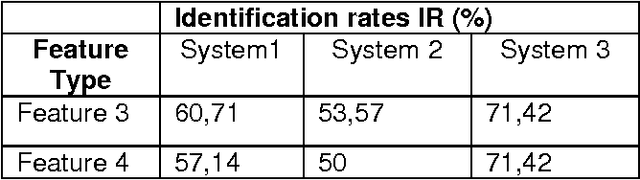
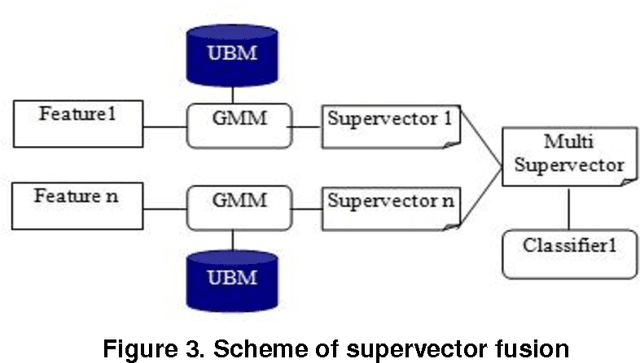
Several speaker identification systems are giving good performance with clean speech but are affected by the degradations introduced by noisy audio conditions. To deal with this problem, we investigate the use of complementary information at different levels for computing a combined match score for the unknown speaker. In this work, we observe the effect of two supervised machine learning approaches including support vectors machines (SVM) and na\"ive bayes (NB). We define two feature vector sets based on mel frequency cepstral coefficients (MFCC) and relative spectral perceptual linear predictive coefficients (RASTA-PLP). Each feature is modeled using the Gaussian Mixture Model (GMM). Several ways of combining these information sources give significant improvements in a text-independent speaker identification task using a very large telephone degraded NTIMIT database.
Improved Frame Level Features and SVM Supervectors Approach for the Recogniton of Emotional States from Speech: Application to categorical and dimensional states
Jun 23, 2014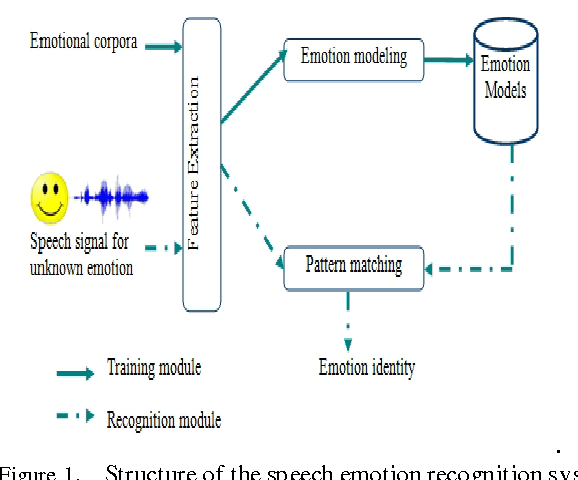
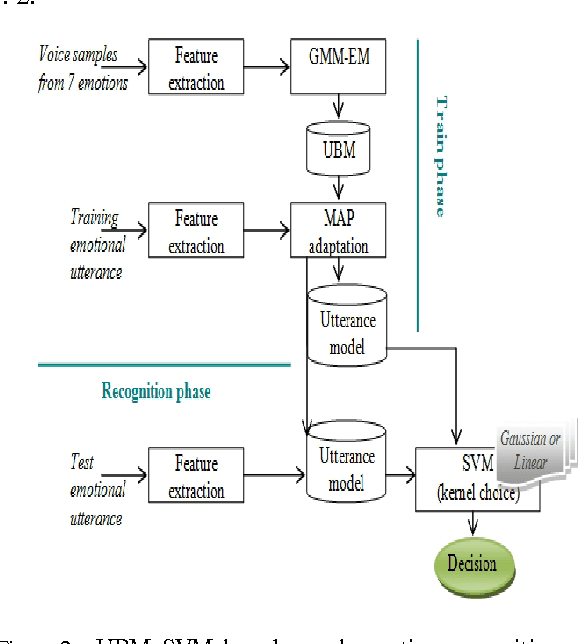

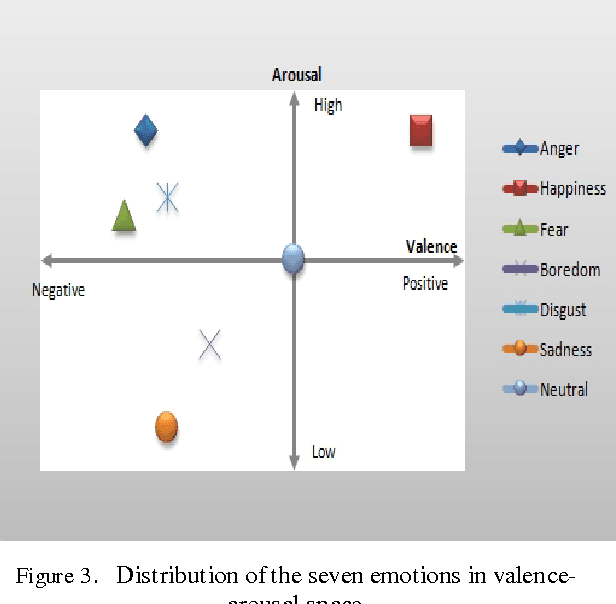
The purpose of speech emotion recognition system is to classify speakers utterances into different emotional states such as disgust, boredom, sadness, neutral and happiness. Speech features that are commonly used in speech emotion recognition rely on global utterance level prosodic features. In our work, we evaluate the impact of frame level feature extraction. The speech samples are from Berlin emotional database and the features extracted from these utterances are energy, different variant of mel frequency cepstrum coefficients, velocity and acceleration features.