 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema Inference for Tabular Data Repositories Using Large Language Models
Sep 04, 2025Minimally curated tabular data often contain representational inconsistencies across heterogeneous sources, and are accompanied by sparse metadata. Working with such data is intimidating. While prior work has advanced dataset discovery and exploration, schema inference remains difficult when metadata are limited. We present SI-LLM (Schema Inference using Large Language Models), which infers a concise conceptual schema for tabular data using only column headers and cell values. The inferred schema comprises hierarchical entity types, attributes, and inter-type relationships. In extensive evaluation on two datasets from web tables and open data, SI-LLM achieves promising end-to-end results, as well as better or comparable results to state-of-the-art methods at each step. All source code, full prompts, and datasets of SI-LLM are available at https://github.com/PierreWoL/SILLM.
Gem: Gaussian Mixture Model Embeddings for Numerical Feature Distributions
Oct 09, 2024Embeddings are now used to underpin a wide variety of data management tasks, including entity resolution, dataset search and semantic type detection. Such applications often involve datasets with numerical columns, but there has been more emphasis placed on the semantics of categorical data in embeddings than on the distinctive features of numerical data. In this paper, we propose a method called Gem (Gaussian mixture model embeddings) that creates embeddings that build on numerical value distributions from columns. The proposed method specializes a Gaussian Mixture Model (GMM) to identify and cluster columns with similar value distributions. We introduce a signature mechanism that generates a probability matrix for each column, indicating its likelihood of belonging to specific Gaussian components, which can be used for different applications, such as to determine semantic types. Finally, we generate embeddings for three numerical data properties: distributional, statistical, and contextual. Our core method focuses solely on numerical columns without using table names or neighboring columns for context. However, the method can be combined with other types of evidence, and we later integrate attribute names with the Gaussian embeddings to evaluate the method's contribution to improving overall performance. We compare Gem with several baseline methods for numeric only and numeric + context tasks, showing that Gem consistently outperforms the baselines on four benchmark datasets.
Cost-effective Variational Active Entity Resolution
Nov 20, 2020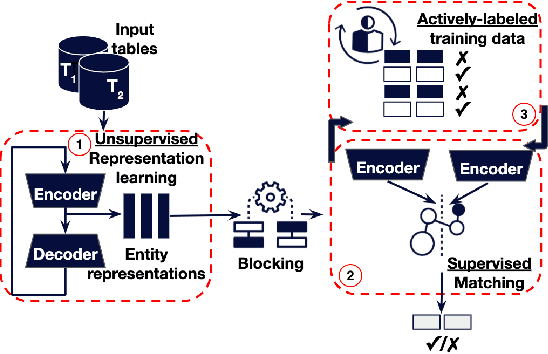



Accurately identifying different representations of the same real-world entity is an integral part of data cleaning and many methods have been proposed to accomplish it. The challenges of this entity resolution task that demand so much research attention are often rooted in the task-specificity and user-dependence of the process. Adopting deep learning techniques has the potential to lessen these challenges. In this paper, we set out to devise an entity resolution method that builds on the robustness conferred by deep autoencoders to reduce human-involvement costs. Specifically, we reduce the cost of training deep entity resolution models by performing unsupervised representation learning. This unveils a transferability property of the resulting model that can further reduce the cost of applying the approach to new datasets by means of transfer learning. Finally, we reduce the cost of labelling training data through an active learning approach that builds on the properties conferred by the use of deep autoencoders. Empirical evaluation confirms the accomplishment of our cost-reduction desideratum while achieving comparable effectiveness with state-of-the-art alternatives.