 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Minimax Risk of Dictionary Learning
Jul 20, 2015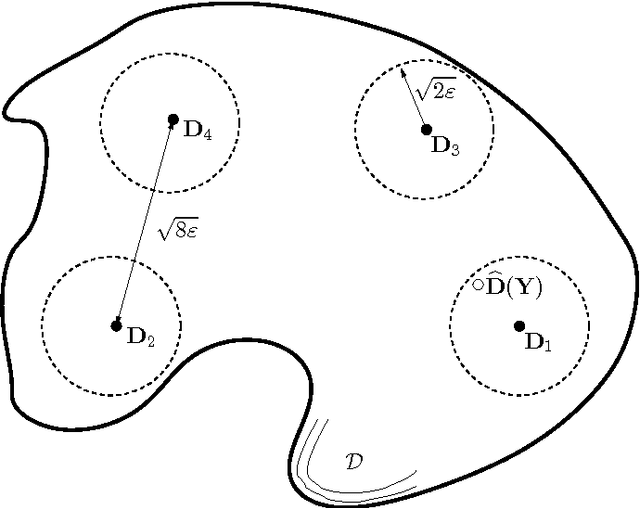

We consider the problem of learning a dictionary matrix from a number of observed signals, which are assumed to be generated via a linear model with a common underlying dictionary. In particular, we derive lower bounds on the minimum achievable worst case mean squared error (MSE), regardless of computational complexity of the dictionary learning (DL) schemes. By casting DL as a classical (or frequentist) estimation problem, the lower bounds on the worst case MSE are derived by following an established information-theoretic approach to minimax estimation. The main conceptual contribution of this paper is the adaption of the information-theoretic approach to minimax estimation for the DL problem in order to derive lower bounds on the worst case MSE of any DL scheme. We derive three different lower bounds applying to different generative models for the observed signals. The first bound applies to a wide range of models, it only requires the existence of a covariance matrix of the (unknown) underlying coefficient vector. By specializing this bound to the case of sparse coefficient distributions, and assuming the true dictionary satisfies the restricted isometry property, we obtain a lower bound on the worst case MSE of DL schemes in terms of a signal to noise ratio (SNR). The third bound applies to a more restrictive subclass of coefficient distributions by requiring the non-zero coefficients to be Gaussian. While, compared with the previous two bounds, the applicability of this final bound is the most limited it is the tightest of the three bounds in the low SNR regime.
Graphical LASSO Based Model Selection for Time Series
Oct 28, 2014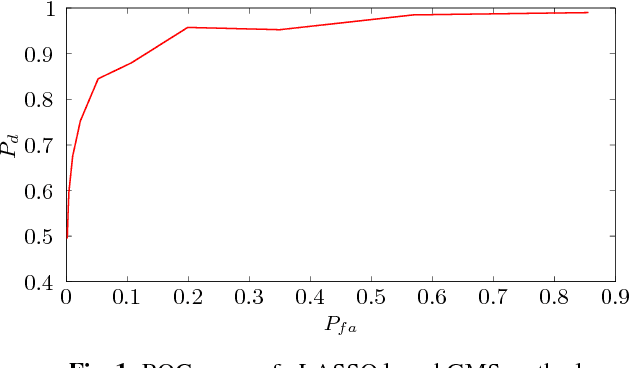
We propose a novel graphical model selection (GMS) scheme for high-dimensional stationary time series or discrete time process. The method is based on a natural generalization of the graphical LASSO (gLASSO), introduced originally for GMS based on i.i.d. samples, and estimates the conditional independence graph (CIG) of a time series from a finite length observation. The gLASSO for time series is defined as the solution of an l1-regularized maximum (approximate) likelihood problem. We solve this optimization problem using the alternating direction method of multipliers (ADMM). Our approach is nonparametric as we do not assume a finite dimensional (e.g., an autoregressive) parametric model for the observed process. Instead, we require the process to be sufficiently smooth in the spectral domain. For Gaussian processes, we characterize the performance of our method theoretically by deriving an upper bound on the probability that our algorithm fails to correctly identify the CIG. Numerical experiments demonstrate the ability of our method to recover the correct CIG from a limited amount of samples.
Performance Limits of Dictionary Learning for Sparse Coding
Jun 27, 2014
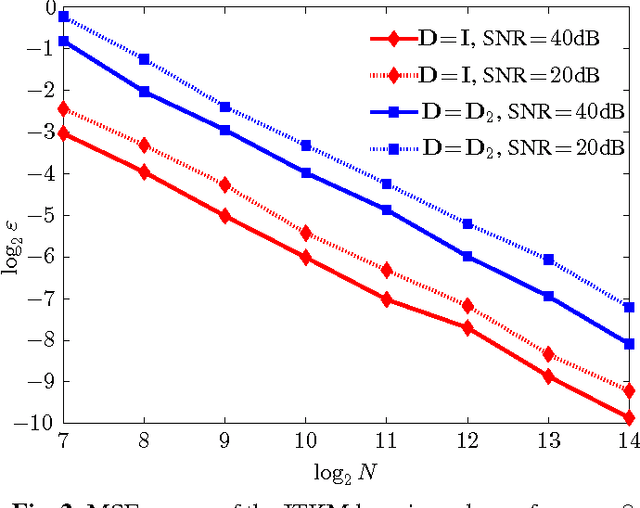
We consider the problem of dictionary learning under the assumption that the observed signals can be represented as sparse linear combinations of the columns of a single large dictionary matrix. In particular, we analyze the minimax risk of the dictionary learning problem which governs the mean squared error (MSE) performance of any learning scheme, regardless of its computational complexity. By following an established information-theoretic method based on Fanos inequality, we derive a lower bound on the minimax risk for a given dictionary learning problem. This lower bound yields a characterization of the sample-complexity, i.e., a lower bound on the required number of observations such that consistent dictionary learning schemes exist. Our bounds may be compared with the performance of a given learning scheme, allowing to characterize how far the method is from optimal performance.