 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImposing Consistency for Optical Flow Estimation
Apr 14, 2022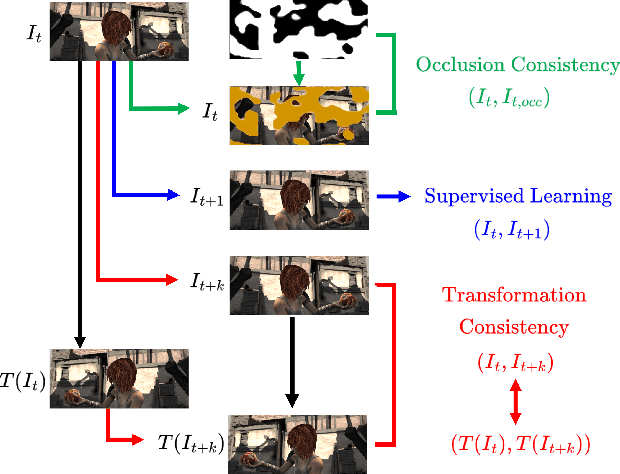
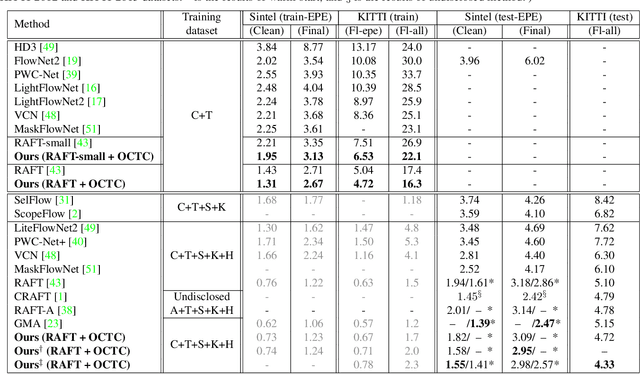

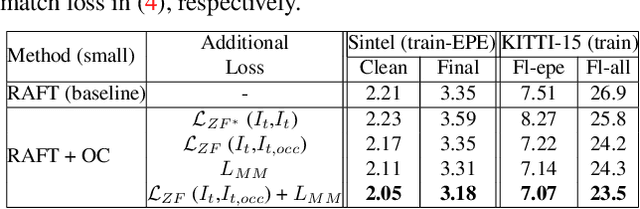
Imposing consistency through proxy tasks has been shown to enhance data-driven learning and enable self-supervision in various tasks. This paper introduces novel and effective consistency strategies for optical flow estimation, a problem where labels from real-world data are very challenging to derive. More specifically, we propose occlusion consistency and zero forcing in the forms of self-supervised learning and transformation consistency in the form of semi-supervised learning. We apply these consistency techniques in a way that the network model learns to describe pixel-level motions better while requiring no additional annotations. We demonstrate that our consistency strategies applied to a strong baseline network model using the original datasets and labels provide further improvements, attaining the state-of-the-art results on the KITTI-2015 scene flow benchmark in the non-stereo category. Our method achieves the best foreground accuracy (4.33% in Fl-all) over both the stereo and non-stereo categories, even though using only monocular image inputs.
MatteFormer: Transformer-Based Image Matting via Prior-Tokens
Mar 29, 2022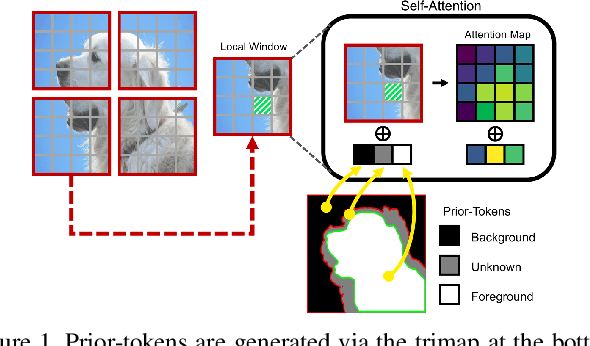
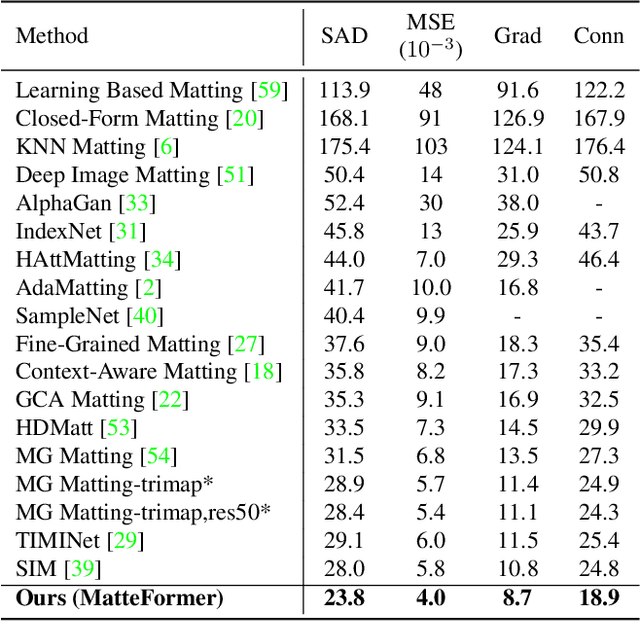
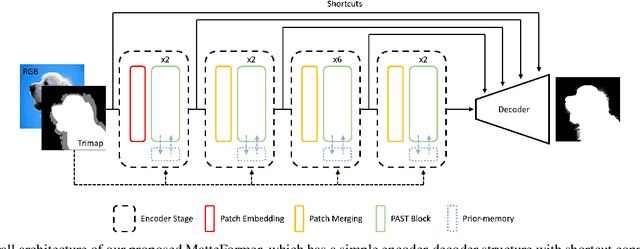
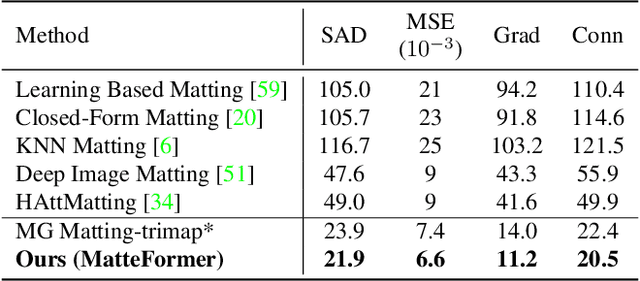
In this paper, we propose a transformer-based image matting model called MatteFormer, which takes full advantage of trimap information in the transformer block. Our method first introduces a prior-token which is a global representation of each trimap region (e.g. foreground, background and unknown). These prior-tokens are used as global priors and participate in the self-attention mechanism of each block. Each stage of the encoder is composed of PAST (Prior-Attentive Swin Transformer) block, which is based on the Swin Transformer block, but differs in a couple of aspects: 1) It has PA-WSA (Prior-Attentive Window Self-Attention) layer, performing self-attention not only with spatial-tokens but also with prior-tokens. 2) It has prior-memory which saves prior-tokens accumulatively from the previous blocks and transfers them to the next block. We evaluate our MatteFormer on the commonly used image matting datasets: Composition-1k and Distinctions-646. Experiment results show that our proposed method achieves state-of-the-art performance with a large margin. Our codes are available at https://github.com/webtoon/matteformer.
Pose-MUM : Reinforcing Key Points Relationship for Semi-Supervised Human Pose Estimation
Mar 15, 2022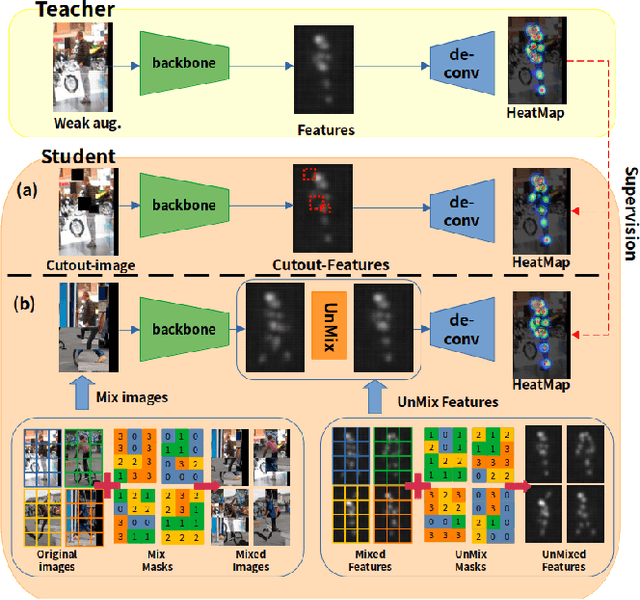
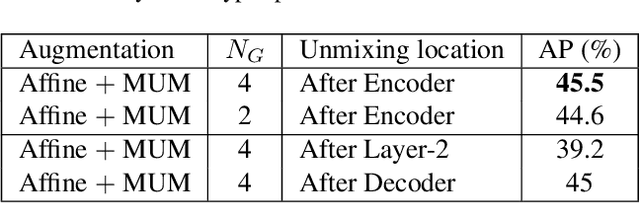
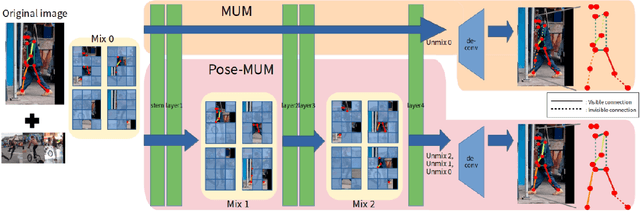
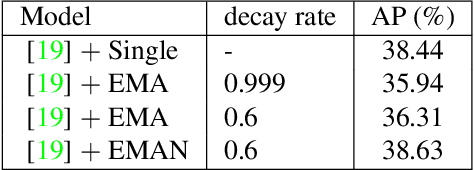
A well-designed strong-weak augmentation strategy and the stable teacher to generate reliable pseudo labels are essential in the teacher-student framework of semi-supervised learning (SSL). Considering these in mind, to suit the semi-supervised human pose estimation (SSHPE) task, we propose a novel approach referred to as Pose-MUM that modifies Mix/UnMix (MUM) augmentation. Like MUM in the dense prediction task, the proposed Pose-MUM makes strong-weak augmentation for pose estimation and leads the network to learn the relationship between each human key point much better than the conventional methods by adding the mixing process in intermediate layers in a stochastic manner. In addition, we employ the exponential-moving-average-normalization (EMAN) teacher, which is stable and well-suited to the SSL framework and furthermore boosts the performance. Extensive experiments on MS-COCO dataset show the superiority of our proposed method by consistently improving the performance over the previous methods following SSHPE benchmark.
Detection of Word Adversarial Examples in Text Classification: Benchmark and Baseline via Robust Density Estimation
Mar 03, 2022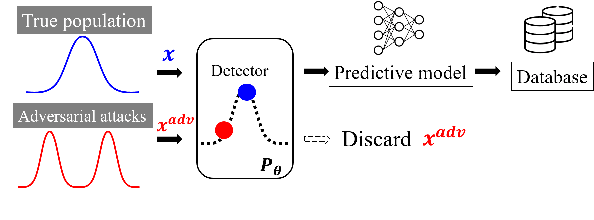
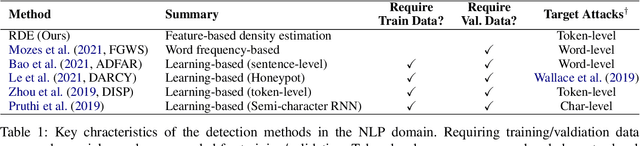
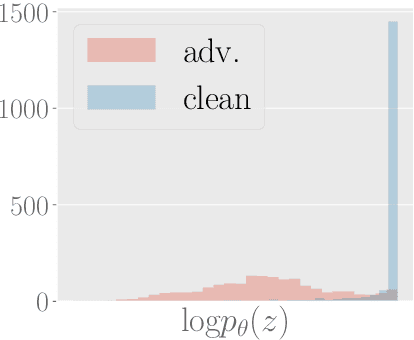

Word-level adversarial attacks have shown success in NLP models, drastically decreasing the performance of transformer-based models in recent years. As a countermeasure, adversarial defense has been explored, but relatively few efforts have been made to detect adversarial examples. However, detecting adversarial examples may be crucial for automated tasks (e.g. review sentiment analysis) that wish to amass information about a certain population and additionally be a step towards a robust defense system. To this end, we release a dataset for four popular attack methods on four datasets and four models to encourage further research in this field. Along with it, we propose a competitive baseline based on density estimation that has the highest AUC on 29 out of 30 dataset-attack-model combinations. Source code is available in https://github.com/anoymous92874838/text-adv-detection.
Self-Distilled Self-Supervised Representation Learning
Nov 25, 2021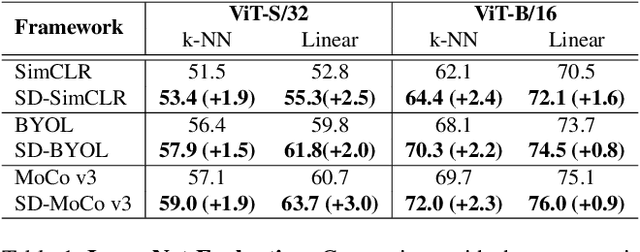
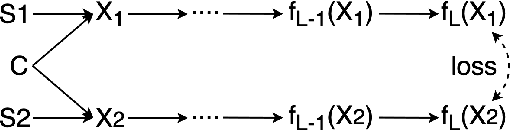
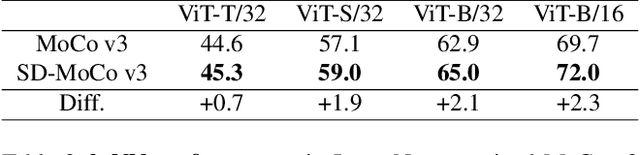
State-of-the-art frameworks in self-supervised learning have recently shown that fully utilizing transformer-based models can lead to performance boost compared to conventional CNN models. Thriving to maximize the mutual information of two views of an image, existing works apply a contrastive loss to the final representations. In our work, we further exploit this by allowing the intermediate representations to learn from the final layers via the contrastive loss, which is maximizing the upper bound of the original goal and the mutual information between two layers. Our method, Self-Distilled Self-Supervised Learning (SDSSL), outperforms competitive baselines (SimCLR, BYOL and MoCo v3) using ViT on various tasks and datasets. In the linear evaluation and k-NN protocol, SDSSL not only leads to superior performance in the final layers, but also in most of the lower layers. Furthermore, positive and negative alignments are used to explain how representations are formed more effectively. Code will be available.
Smoothing the Generative Latent Space with Mixup-based Distance Learning
Nov 23, 2021

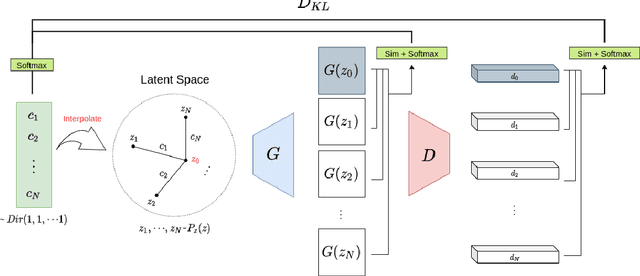

Producing diverse and realistic images with generative models such as GANs typically requires large scale training with vast amount of images. GANs trained with extremely limited data can easily overfit to few training samples and display undesirable properties like "stairlike" latent space where transitions in latent space suffer from discontinuity, occasionally yielding abrupt changes in outputs. In this work, we consider the situation where neither large scale dataset of our interest nor transferable source dataset is available, and seek to train existing generative models with minimal overfitting and mode collapse. We propose latent mixup-based distance regularization on the feature space of both a generator and the counterpart discriminator that encourages the two players to reason not only about the scarce observed data points but the relative distances in the feature space they reside. Qualitative and quantitative evaluation on diverse datasets demonstrates that our method is generally applicable to existing models to enhance both fidelity and diversity under the constraint of limited data. Code will be made public.
Local-Selective Feature Distillation for Single Image Super-Resolution
Nov 22, 2021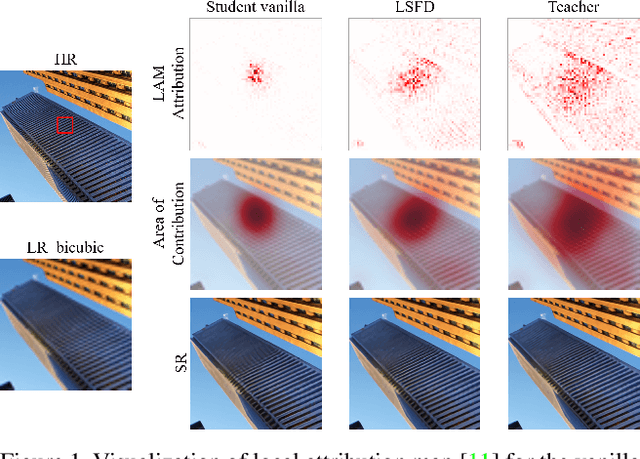
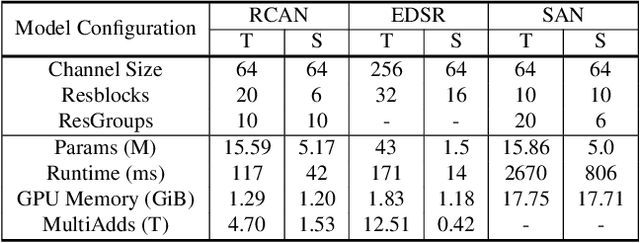
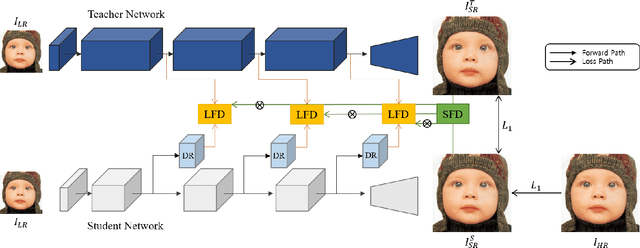
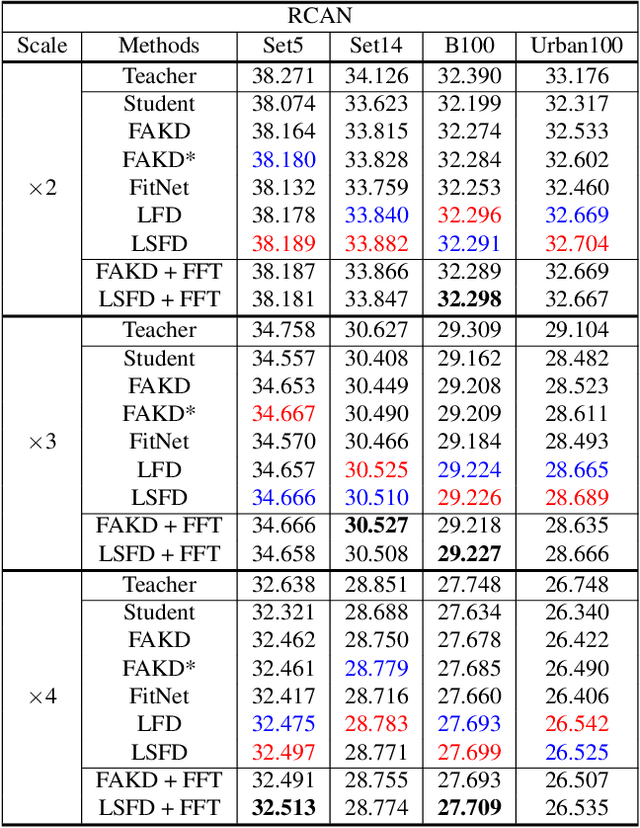
Recent improvements in convolutional neural network (CNN)-based single image super-resolution (SISR) methods rely heavily on fabricating network architectures, rather than finding a suitable training algorithm other than simply minimizing the regression loss. Adapting knowledge distillation (KD) can open a way for bringing further improvement for SISR, and it is also beneficial in terms of model efficiency. KD is a model compression method that improves the performance of Deep Neural Networks (DNNs) without using additional parameters for testing. It is getting the limelight recently for its competence at providing a better capacity-performance tradeoff. In this paper, we propose a novel feature distillation (FD) method which is suitable for SISR. We show the limitations of the existing FitNet-based FD method that it suffers in the SISR task, and propose to modify the existing FD algorithm to focus on local feature information. In addition, we propose a teacher-student-difference-based soft feature attention method that selectively focuses on specific pixel locations to extract feature information. We call our method local-selective feature distillation (LSFD) and verify that our method outperforms conventional FD methods in SISR problems.
MUM : Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection
Nov 22, 2021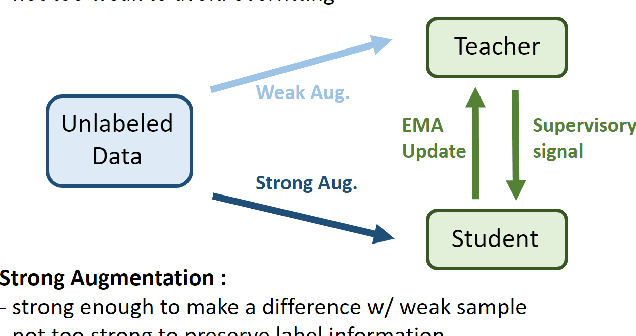
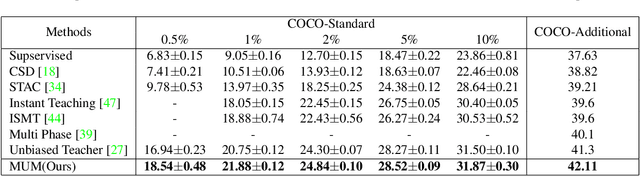
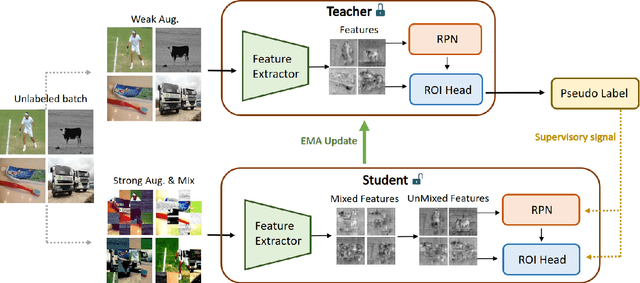
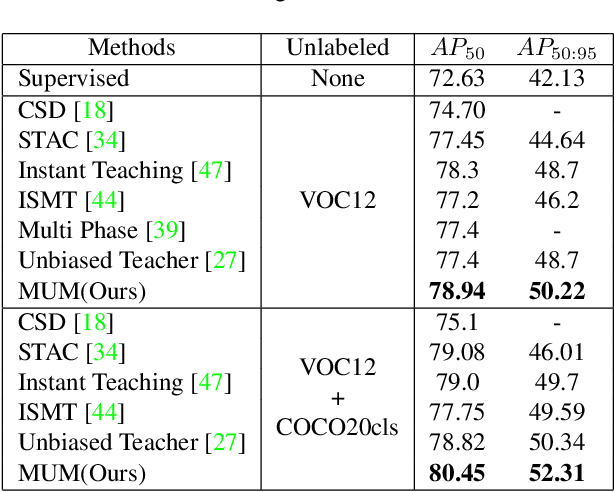
Many recent semi-supervised learning (SSL) studies build teacher-student architecture and train the student network by the generated supervisory signal from the teacher. Data augmentation strategy plays a significant role in the SSL framework since it is hard to create a weak-strong augmented input pair without losing label information. Especially when extending SSL to semi-supervised object detection (SSOD), many strong augmentation methodologies related to image geometry and interpolation-regularization are hard to utilize since they possibly hurt the location information of the bounding box in the object detection task. To address this, we introduce a simple yet effective data augmentation method, Mix/UnMix (MUM), which unmixes feature tiles for the mixed image tiles for the SSOD framework. Our proposed method makes mixed input image tiles and reconstructs them in the feature space. Thus, MUM can enjoy the interpolation-regularization effect from non-interpolated pseudo-labels and successfully generate a meaningful weak-strong pair. Furthermore, MUM can be easily equipped on top of various SSOD methods. Extensive experiments on MS-COCO and PASCAL VOC datasets demonstrate the superiority of MUM by consistently improving the mAP performance over the baseline in all the tested SSOD benchmark protocols.
Dynamic Iterative Refinement for Efficient 3D Hand Pose Estimation
Nov 11, 2021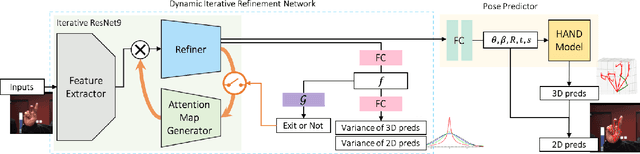
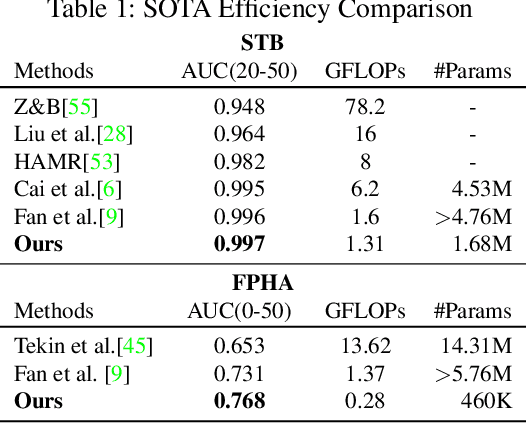
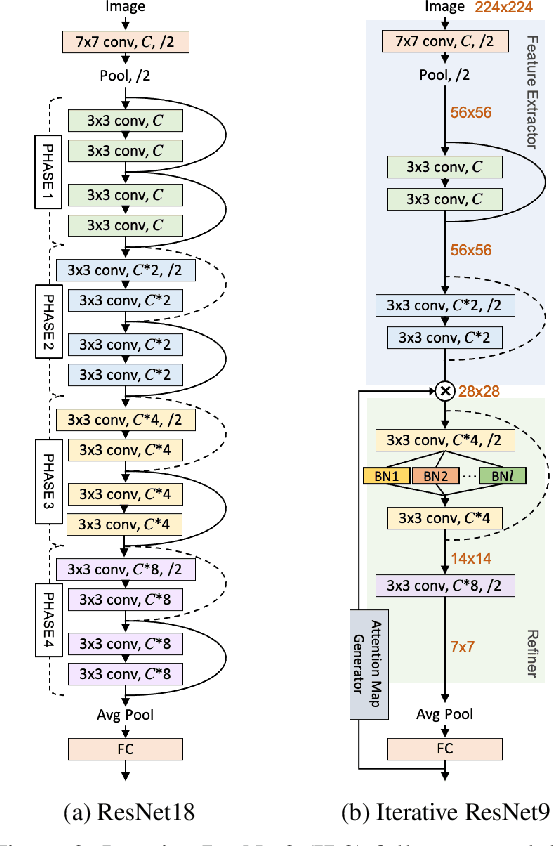
While hand pose estimation is a critical component of most interactive extended reality and gesture recognition systems, contemporary approaches are not optimized for computational and memory efficiency. In this paper, we propose a tiny deep neural network of which partial layers are recursively exploited for refining its previous estimations. During its iterative refinements, we employ learned gating criteria to decide whether to exit from the weight-sharing loop, allowing per-sample adaptation in our model. Our network is trained to be aware of the uncertainty in its current predictions to efficiently gate at each iteration, estimating variances after each loop for its keypoint estimates. Additionally, we investigate the effectiveness of end-to-end and progressive training protocols for our recursive structure on maximizing the model capacity. With the proposed setting, our method consistently outperforms state-of-the-art 2D/3D hand pose estimation approaches in terms of both accuracy and efficiency for widely used benchmarks.
Exploiting Inter-pixel Correlations in Unsupervised Domain Adaptation for Semantic Segmentation
Oct 21, 2021
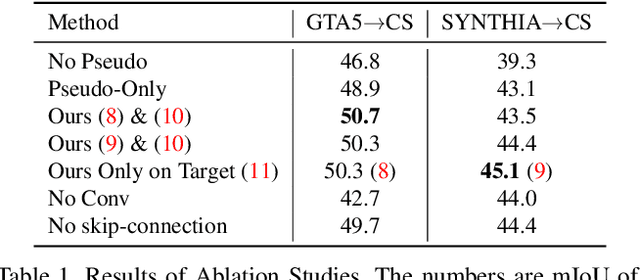
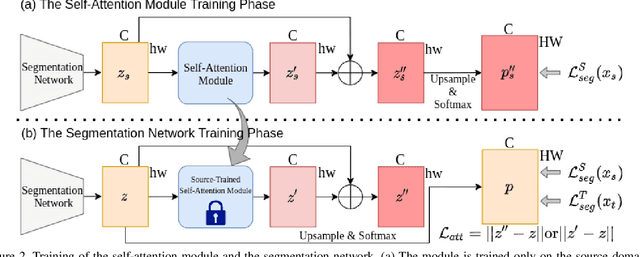
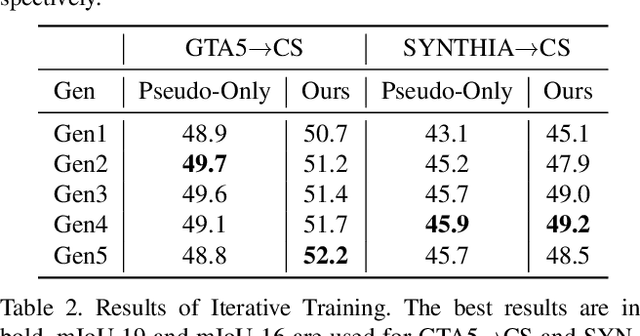
"Self-training" has become a dominant method for semantic segmentation via unsupervised domain adaptation (UDA). It creates a set of pseudo labels for the target domain to give explicit supervision. However, the pseudo labels are noisy, sparse and do not provide any information about inter-pixel correlations. We regard inter-pixel correlation quite important because semantic segmentation is a task of predicting highly structured pixel-level outputs. Therefore, in this paper, we propose a method of transferring the inter-pixel correlations from the source domain to the target domain via a self-attention module. The module takes the prediction of the segmentation network as an input and creates a self-attended prediction that correlates similar pixels. The module is trained only on the source domain to learn the domain-invariant inter-pixel correlations, then later, it is used to train the segmentation network on the target domain. The network learns not only from the pseudo labels but also by following the output of the self-attention module which provides additional knowledge about the inter-pixel correlations. Through extensive experiments, we show that our method significantly improves the performance on two standard UDA benchmarks and also can be combined with recent state-of-the-art method to achieve better performance.