 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Challenging Multimodal Video Summary: Simultaneously Extracting and Generating Keyframe-Caption Pairs from Video
Dec 04, 2023



This paper proposes a practical multimodal video summarization task setting and a dataset to train and evaluate the task. The target task involves summarizing a given video into a predefined number of keyframe-caption pairs and displaying them in a listable format to grasp the video content quickly. This task aims to extract crucial scenes from the video in the form of images (keyframes) and generate corresponding captions explaining each keyframe's situation. This task is useful as a practical application and presents a highly challenging problem worthy of study. Specifically, achieving simultaneous optimization of the keyframe selection performance and caption quality necessitates careful consideration of the mutual dependence on both preceding and subsequent keyframes and captions. To facilitate subsequent research in this field, we also construct a dataset by expanding upon existing datasets and propose an evaluation framework. Furthermore, we develop two baseline systems and report their respective performance.
Off-Policy Evaluation of Ranking Policies under Diverse User Behavior
Jun 26, 2023Ranking interfaces are everywhere in online platforms. There is thus an ever growing interest in their Off-Policy Evaluation (OPE), aiming towards an accurate performance evaluation of ranking policies using logged data. A de-facto approach for OPE is Inverse Propensity Scoring (IPS), which provides an unbiased and consistent value estimate. However, it becomes extremely inaccurate in the ranking setup due to its high variance under large action spaces. To deal with this problem, previous studies assume either independent or cascade user behavior, resulting in some ranking versions of IPS. While these estimators are somewhat effective in reducing the variance, all existing estimators apply a single universal assumption to every user, causing excessive bias and variance. Therefore, this work explores a far more general formulation where user behavior is diverse and can vary depending on the user context. We show that the resulting estimator, which we call Adaptive IPS (AIPS), can be unbiased under any complex user behavior. Moreover, AIPS achieves the minimum variance among all unbiased estimators based on IPS. We further develop a procedure to identify the appropriate user behavior model to minimize the mean squared error (MSE) of AIPS in a data-driven fashion. Extensive experiments demonstrate that the empirical accuracy improvement can be significant, enabling effective OPE of ranking systems even under diverse user behavior.
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model
Feb 03, 2022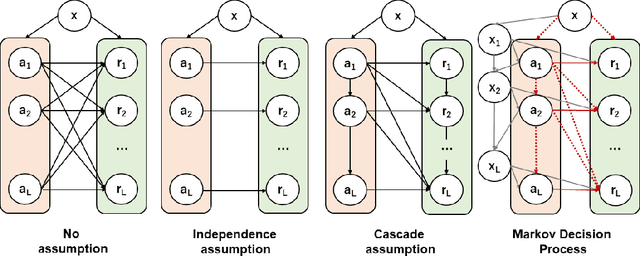
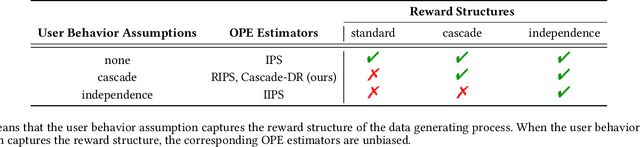

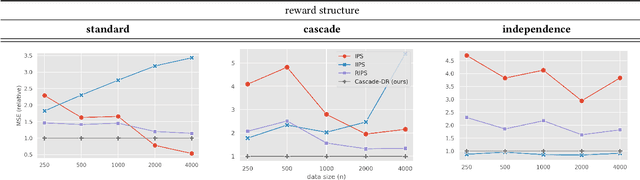
In real-world recommender systems and search engines, optimizing ranking decisions to present a ranked list of relevant items is critical. Off-policy evaluation (OPE) for ranking policies is thus gaining a growing interest because it enables performance estimation of new ranking policies using only logged data. Although OPE in contextual bandits has been studied extensively, its naive application to the ranking setting faces a critical variance issue due to the huge item space. To tackle this problem, previous studies introduce some assumptions on user behavior to make the combinatorial item space tractable. However, an unrealistic assumption may, in turn, cause serious bias. Therefore, appropriately controlling the bias-variance tradeoff by imposing a reasonable assumption is the key for success in OPE of ranking policies. To achieve a well-balanced bias-variance tradeoff, we propose the Cascade Doubly Robust estimator building on the cascade assumption, which assumes that a user interacts with items sequentially from the top position in a ranking. We show that the proposed estimator is unbiased in more cases compared to existing estimators that make stronger assumptions. Furthermore, compared to a previous estimator based on the same cascade assumption, the proposed estimator reduces the variance by leveraging a control variate. Comprehensive experiments on both synthetic and real-world data demonstrate that our estimator leads to more accurate OPE than existing estimators in a variety of settings.
Deep Learning Based Multi-modal Addressee Recognition in Visual Scenes with Utterances
Sep 12, 2018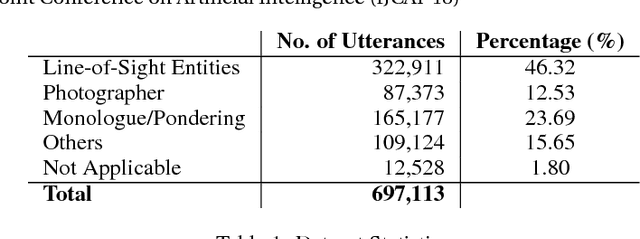

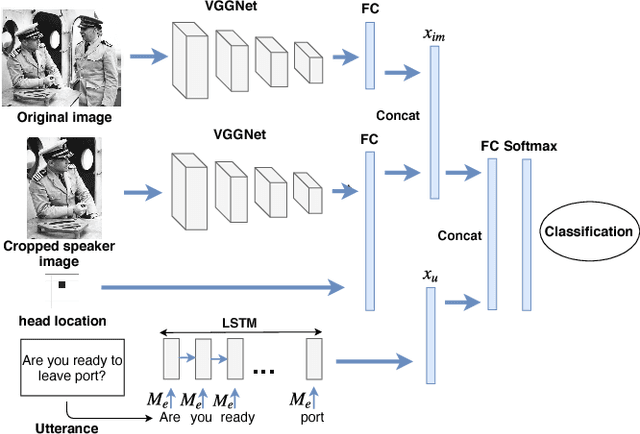
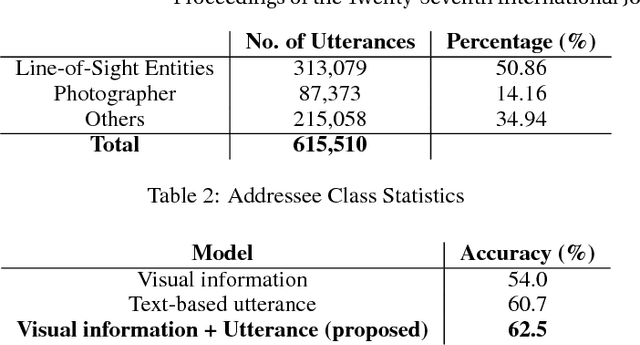
With the widespread use of intelligent systems, such as smart speakers, addressee recognition has become a concern in human-computer interaction, as more and more people expect such systems to understand complicated social scenes, including those outdoors, in cafeterias, and hospitals. Because previous studies typically focused only on pre-specified tasks with limited conversational situations such as controlling smart homes, we created a mock dataset called Addressee Recognition in Visual Scenes with Utterances (ARVSU) that contains a vast body of image variations in visual scenes with an annotated utterance and a corresponding addressee for each scenario. We also propose a multi-modal deep-learning-based model that takes different human cues, specifically eye gazes and transcripts of an utterance corpus, into account to predict the conversational addressee from a specific speaker's view in various real-life conversational scenarios. To the best of our knowledge, we are the first to introduce an end-to-end deep learning model that combines vision and transcripts of utterance for addressee recognition. As a result, our study suggests that future addressee recognition can reach the ability to understand human intention in many social situations previously unexplored, and our modality dataset is a first step in promoting research in this field.
Cross-domain Recommendation via Deep Domain Adaptation
Mar 08, 2018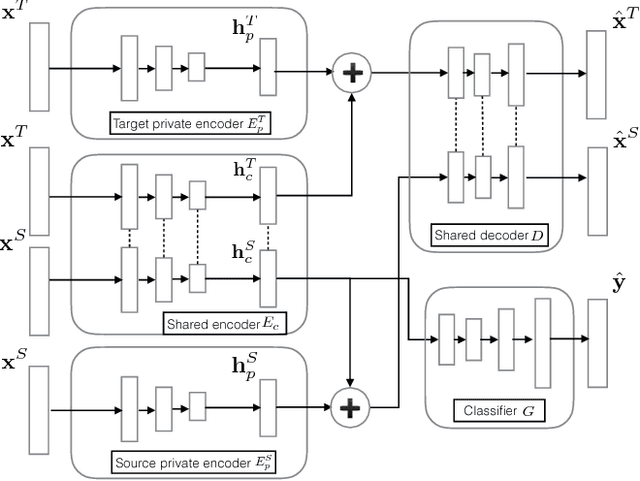
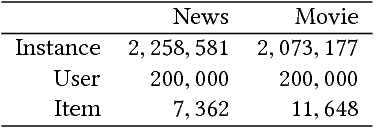
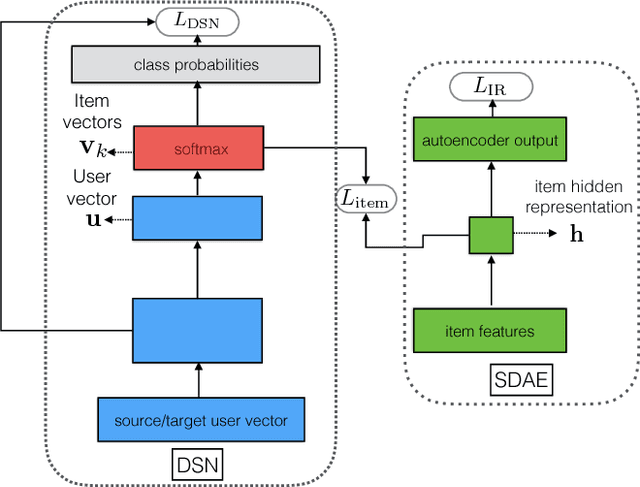
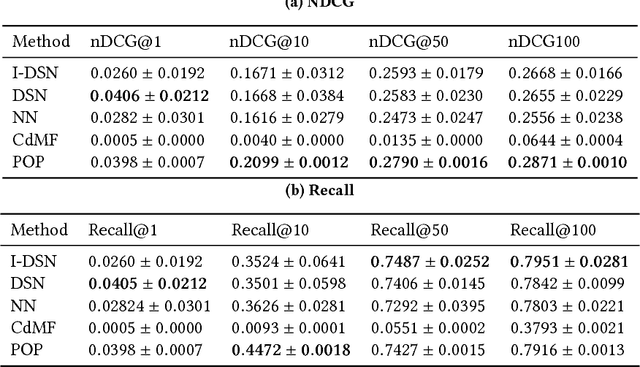
The behavior of users in certain services could be a clue that can be used to infer their preferences and may be used to make recommendations for other services they have never used. However, the cross-domain relationships between items and user consumption patterns are not simple, especially when there are few or no common users and items across domains. To address this problem, we propose a content-based cross-domain recommendation method for cold-start users that does not require user- and item- overlap. We formulate recommendation as extreme multi-class classification where labels (items) corresponding to the users are predicted. With this formulation, the problem is reduced to a domain adaptation setting, in which a classifier trained in the source domain is adapted to the target domain. For this, we construct a neural network that combines an architecture for domain adaptation, Domain Separation Network, with a denoising autoencoder for item representation. We assess the performance of our approach in experiments on a pair of data sets collected from movie and news services of Yahoo! JAPAN and show that our approach outperforms several baseline methods including a cross-domain collaborative filtering method.