 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster & Tune: Boost Cold Start Performance in Text Classification
Mar 20, 2022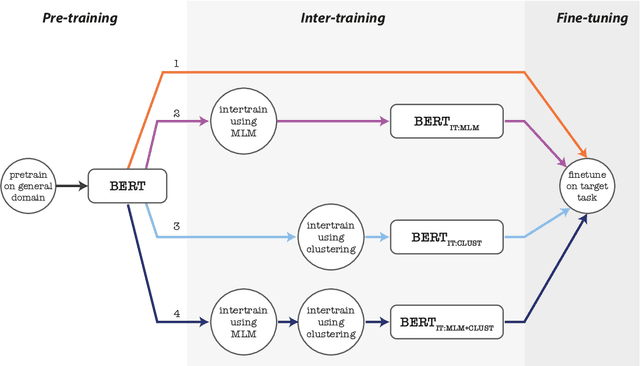
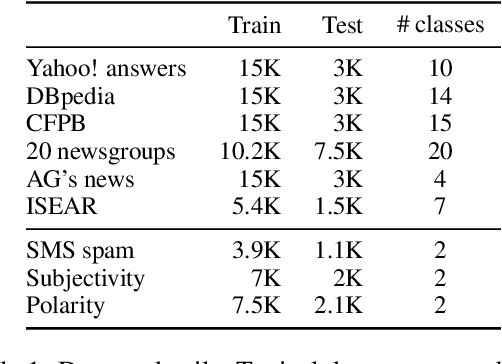
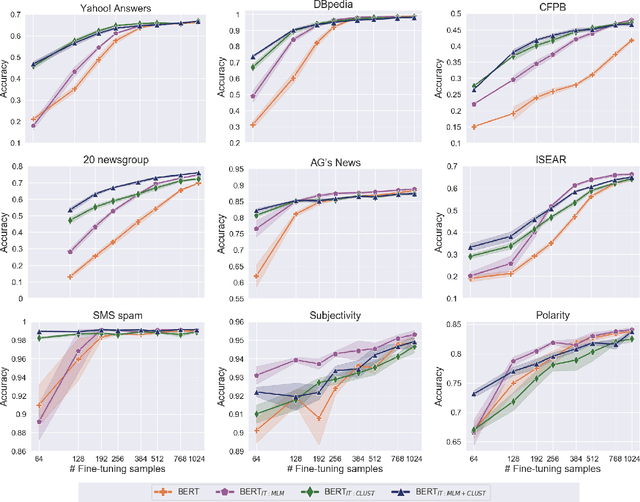
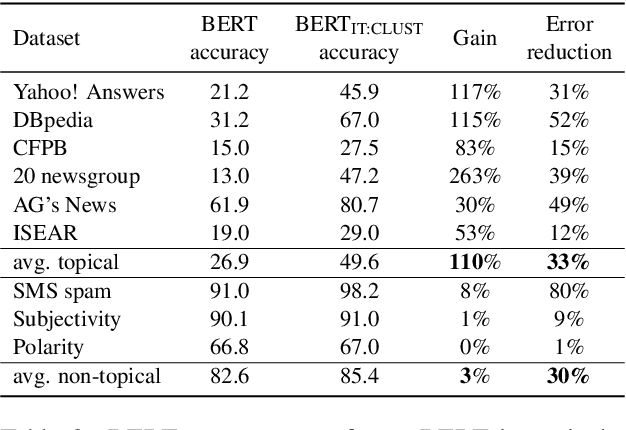
In real-world scenarios, a text classification task often begins with a cold start, when labeled data is scarce. In such cases, the common practice of fine-tuning pre-trained models, such as BERT, for a target classification task, is prone to produce poor performance. We suggest a method to boost the performance of such models by adding an intermediate unsupervised classification task, between the pre-training and fine-tuning phases. As such an intermediate task, we perform clustering and train the pre-trained model on predicting the cluster labels. We test this hypothesis on various data sets, and show that this additional classification phase can significantly improve performance, mainly for topical classification tasks, when the number of labeled instances available for fine-tuning is only a couple of dozen to a few hundred.
Fortunately, Discourse Markers Can Enhance Language Models for Sentiment Analysis
Jan 06, 2022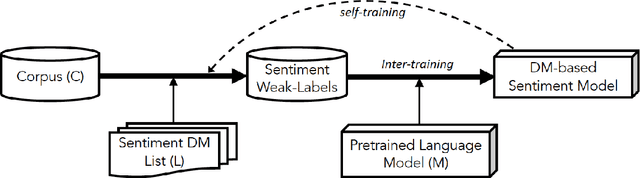

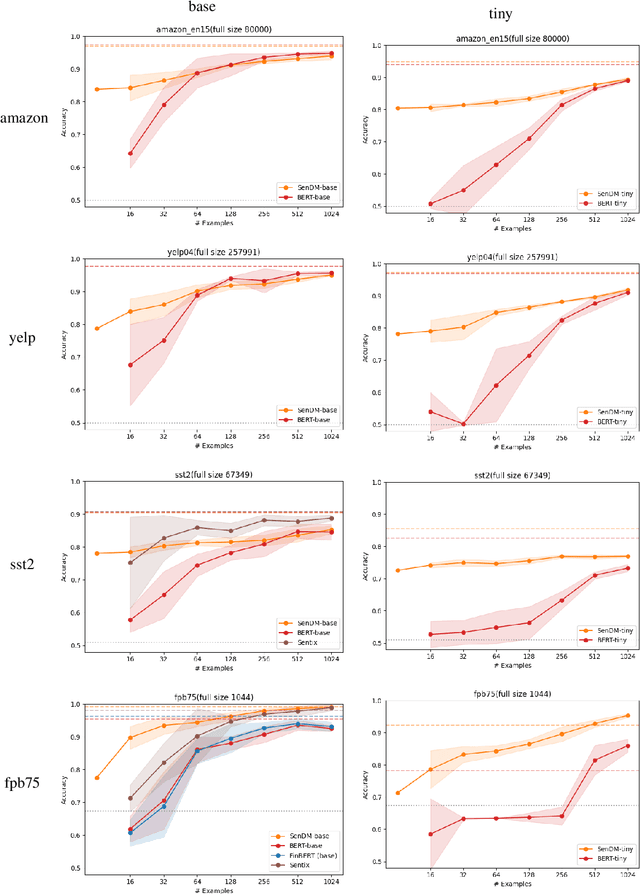
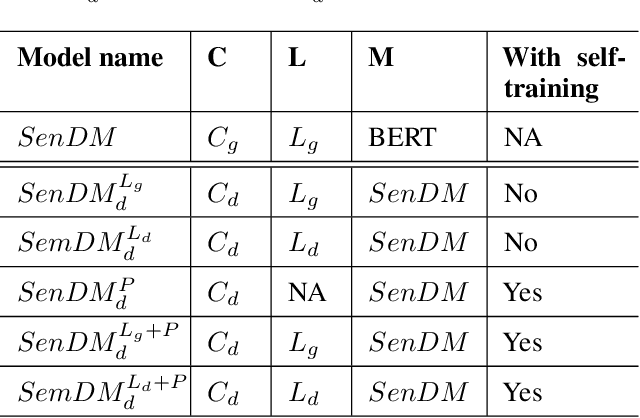
In recent years, pretrained language models have revolutionized the NLP world, while achieving state of the art performance in various downstream tasks. However, in many cases, these models do not perform well when labeled data is scarce and the model is expected to perform in the zero or few shot setting. Recently, several works have shown that continual pretraining or performing a second phase of pretraining (inter-training) which is better aligned with the downstream task, can lead to improved results, especially in the scarce data setting. Here, we propose to leverage sentiment-carrying discourse markers to generate large-scale weakly-labeled data, which in turn can be used to adapt language models for sentiment analysis. Extensive experimental results show the value of our approach on various benchmark datasets, including the finance domain. Code, models and data are available at https://github.com/ibm/tslm-discourse-markers.
Overview of the 2021 Key Point Analysis Shared Task
Oct 20, 2021
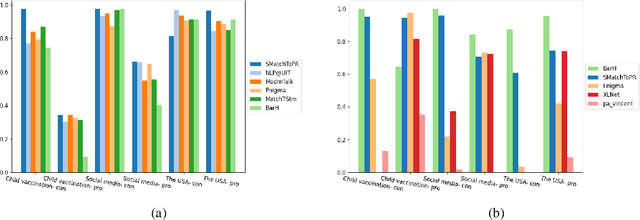
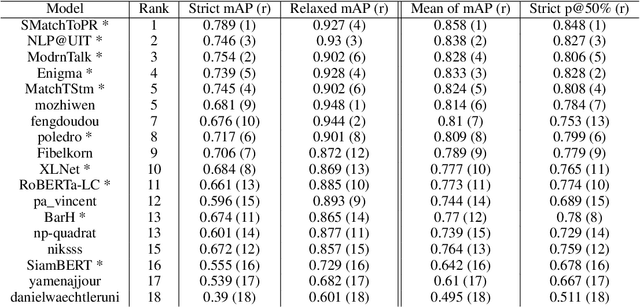
We describe the 2021 Key Point Analysis (KPA-2021) shared task on key point analysis that we organized as a part of the 8th Workshop on Argument Mining (ArgMining 2021) at EMNLP 2021. We outline various approaches and discuss the results of the shared task. We expect the task and the findings reported in this paper to be relevant for researchers working on text summarization and argument mining.
Project Debater APIs: Decomposing the AI Grand Challenge
Oct 03, 2021


Project Debater was revealed in 2019 as the first AI system that can debate human experts on complex topics. Engaging in a live debate requires a diverse set of skills, and Project Debater has been developed accordingly as a collection of components, each designed to perform a specific subtask. Project Debater APIs provide access to many of these capabilities, as well as to more recently developed ones. This diverse set of web services, publicly available for academic use, includes core NLP services, argument mining and analysis capabilities, and higher-level services for content summarization. We describe these APIs and their performance, and demonstrate how they can be used for building practical solutions. In particular, we will focus on Key Point Analysis, a novel technology that identifies the main points and their prevalence in a collection of texts such as survey responses and user reviews.
Every Bite Is an Experience: Key Point Analysis of Business Reviews
Jun 12, 2021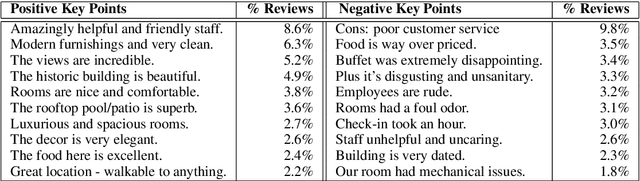

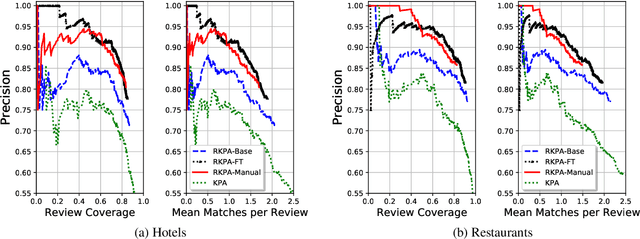
Previous work on review summarization focused on measuring the sentiment toward the main aspects of the reviewed product or business, or on creating a textual summary. These approaches provide only a partial view of the data: aspect-based sentiment summaries lack sufficient explanation or justification for the aspect rating, while textual summaries do not quantify the significance of each element, and are not well-suited for representing conflicting views. Recently, Key Point Analysis (KPA) has been proposed as a summarization framework that provides both textual and quantitative summary of the main points in the data. We adapt KPA to review data by introducing Collective Key Point Mining for better key point extraction; integrating sentiment analysis into KPA; identifying good key point candidates for review summaries; and leveraging the massive amount of available reviews and their metadata. We show empirically that these novel extensions of KPA substantially improve its performance. We demonstrate that promising results can be achieved without any domain-specific annotation, while human supervision can lead to further improvement.
YASO: A New Benchmark for Targeted Sentiment Analysis
Dec 29, 2020


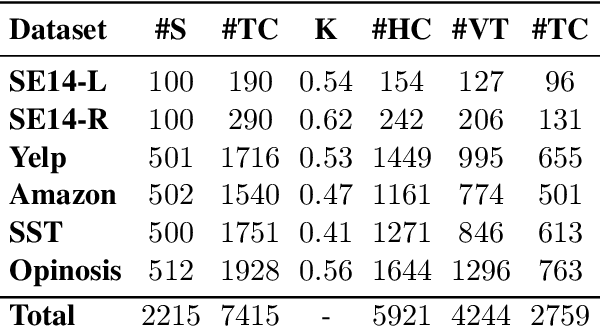
Sentiment analysis research has shifted over the years from the analysis of full documents or single sentences to a finer-level of detail -- identifying the sentiment towards single words or phrases -- with the task of Targeted Sentiment Analysis (TSA). While this problem is attracting a plethora of works focusing on algorithmic aspects, they are typically evaluated on a selection from a handful of datasets, and little effort, if any, is dedicated to the expansion of the available evaluation data. In this work, we present YASO -- a new crowd-sourced TSA evaluation dataset, collected using a new annotation scheme for labeling targets and their sentiments. The dataset contains 2,215 English sentences from movie, business and product reviews, and 7,415 terms and their corresponding sentiments annotated within these sentences. Our analysis verifies the reliability of our annotations, and explores the characteristics of the collected data. Lastly, benchmark results using five contemporary TSA systems lay the foundation for future work, and show there is ample room for improvement on this challenging new dataset.
Unsupervised Expressive Rules Provide Explainability and Assist Human Experts Grasping New Domains
Oct 19, 2020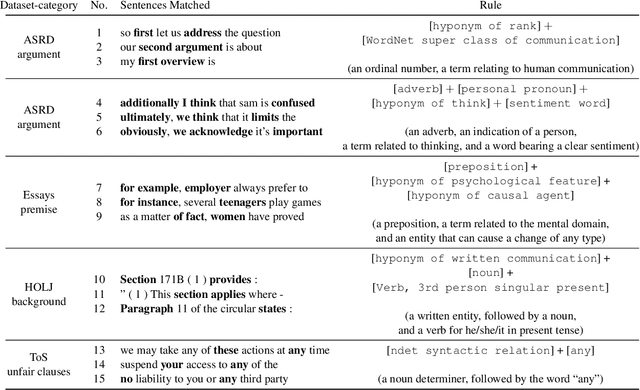
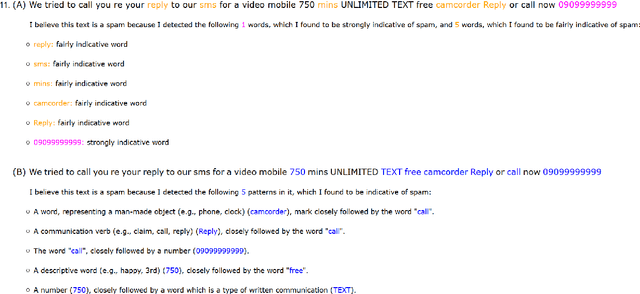
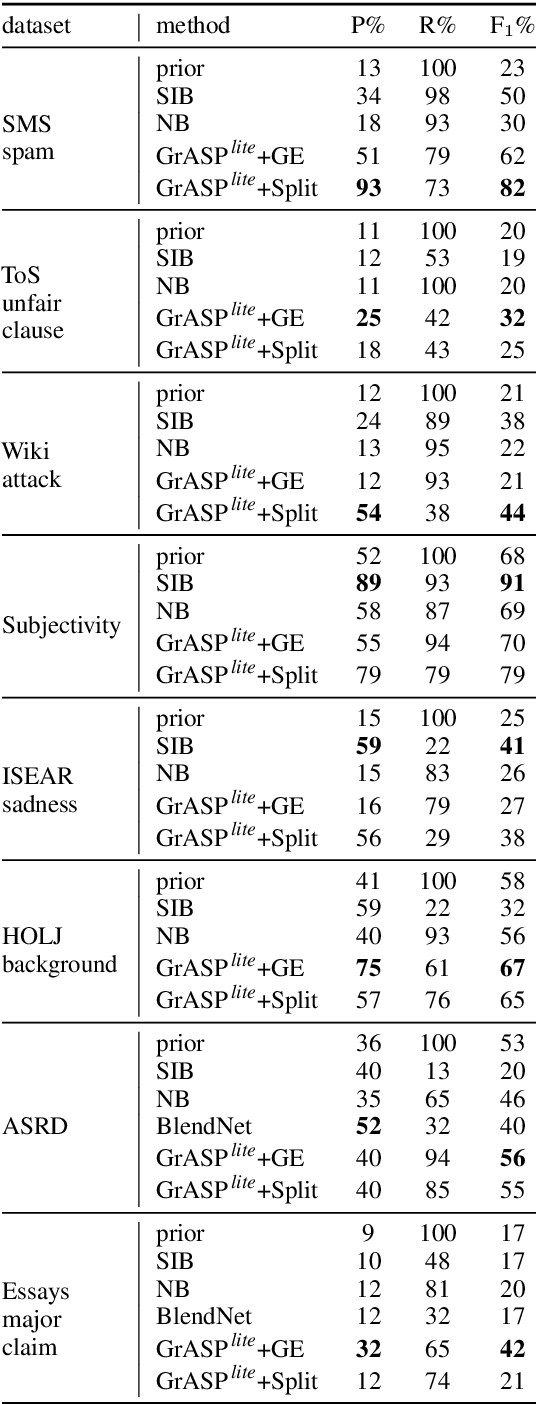
Approaching new data can be quite deterrent; you do not know how your categories of interest are realized in it, commonly, there is no labeled data at hand, and the performance of domain adaptation methods is unsatisfactory. Aiming to assist domain experts in their first steps into a new task over a new corpus, we present an unsupervised approach to reveal complex rules which cluster the unexplored corpus by its prominent categories (or facets). These rules are human-readable, thus providing an important ingredient which has become in short supply lately - explainability. Each rule provides an explanation for the commonality of all the texts it clusters together. We present an extensive evaluation of the usefulness of these rules in identifying target categories, as well as a user study which assesses their interpretability.
Multilingual Argument Mining: Datasets and Analysis
Oct 13, 2020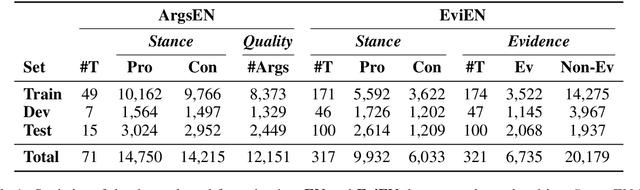
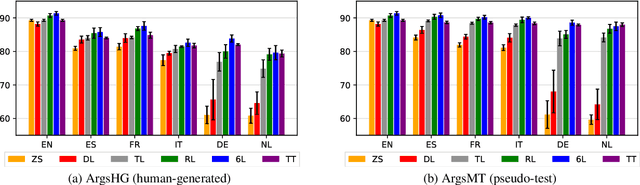
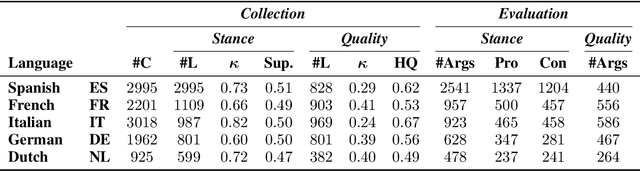
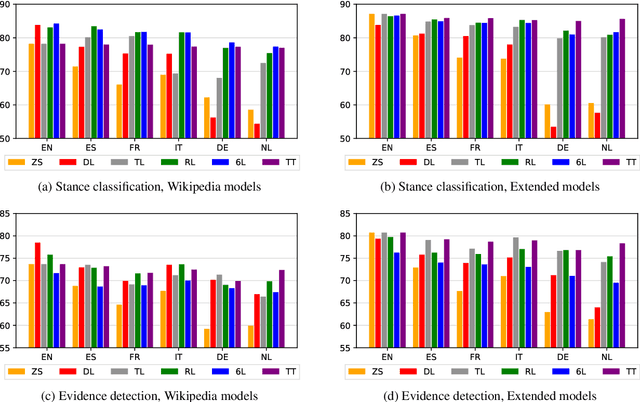
The growing interest in argument mining and computational argumentation brings with it a plethora of Natural Language Understanding (NLU) tasks and corresponding datasets. However, as with many other NLU tasks, the dominant language is English, with resources in other languages being few and far between. In this work, we explore the potential of transfer learning using the multilingual BERT model to address argument mining tasks in non-English languages, based on English datasets and the use of machine translation. We show that such methods are well suited for classifying the stance of arguments and detecting evidence, but less so for assessing the quality of arguments, presumably because quality is harder to preserve under translation. In addition, focusing on the translate-train approach, we show how the choice of languages for translation, and the relations among them, affect the accuracy of the resultant model. Finally, to facilitate evaluation of transfer learning on argument mining tasks, we provide a human-generated dataset with more than 10k arguments in multiple languages, as well as machine translation of the English datasets.
The workweek is the best time to start a family -- A Study of GPT-2 Based Claim Generation
Oct 13, 2020
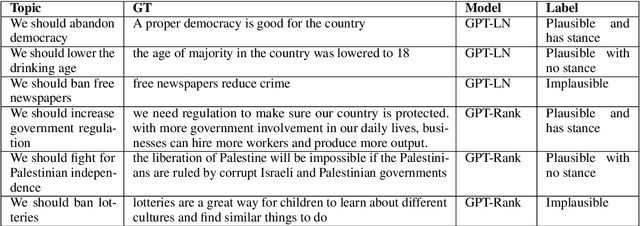


Argument generation is a challenging task whose research is timely considering its potential impact on social media and the dissemination of information. Here we suggest a pipeline based on GPT-2 for generating coherent claims, and explore the types of claims that it produces, and their veracity, using an array of manual and automatic assessments. In addition, we explore the interplay between this task and the task of Claim Retrieval, showing how they can complement one another.
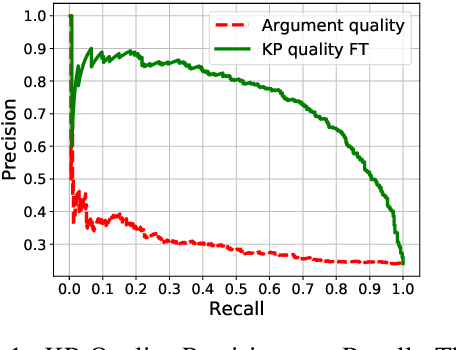
Quantitative Argument Summarization and Beyond: Cross-Domain Key Point Analysis
Oct 11, 2020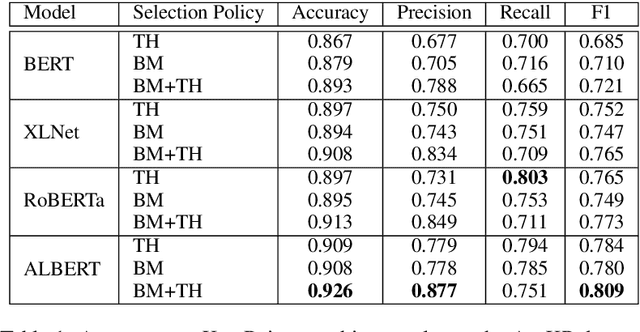

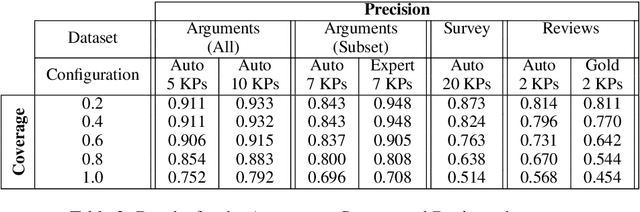
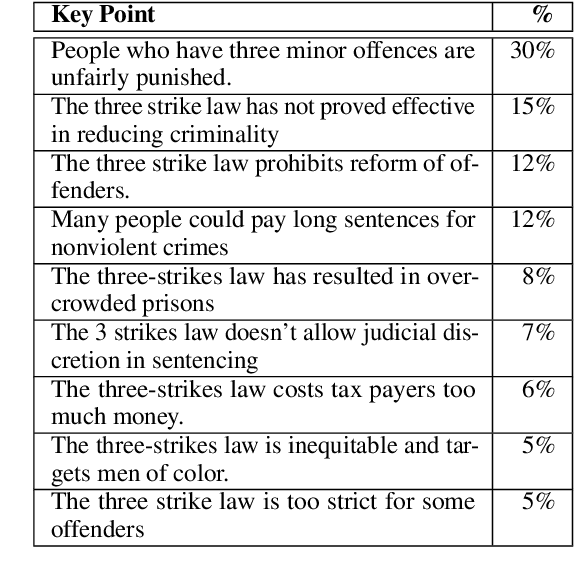
When summarizing a collection of views, arguments or opinions on some topic, it is often desirable not only to extract the most salient points, but also to quantify their prevalence. Work on multi-document summarization has traditionally focused on creating textual summaries, which lack this quantitative aspect. Recent work has proposed to summarize arguments by mapping them to a small set of expert-generated key points, where the salience of each key point corresponds to the number of its matching arguments. The current work advances key point analysis in two important respects: first, we develop a method for automatic extraction of key points, which enables fully automatic analysis, and is shown to achieve performance comparable to a human expert. Second, we demonstrate that the applicability of key point analysis goes well beyond argumentation data. Using models trained on publicly available argumentation datasets, we achieve promising results in two additional domains: municipal surveys and user reviews. An additional contribution is an in-depth evaluation of argument-to-key point matching models, where we substantially outperform previous results.