 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInitialization Strategies of Spatio-Temporal Convolutional Neural Networks
Mar 25, 2015

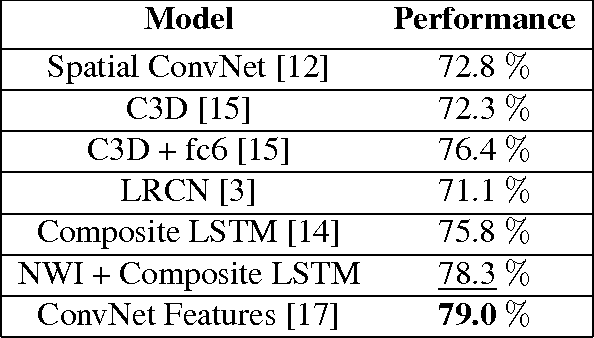

We propose a new way of incorporating temporal information present in videos into Spatial Convolutional Neural Networks (ConvNets) trained on images, that avoids training Spatio-Temporal ConvNets from scratch. We describe several initializations of weights in 3D Convolutional Layers of Spatio-Temporal ConvNet using 2D Convolutional Weights learned from ImageNet. We show that it is important to initialize 3D Convolutional Weights judiciously in order to learn temporal representations of videos. We evaluate our methods on the UCF-101 dataset and demonstrate improvement over Spatial ConvNets.
Learning Generative Models with Visual Attention
Feb 21, 2015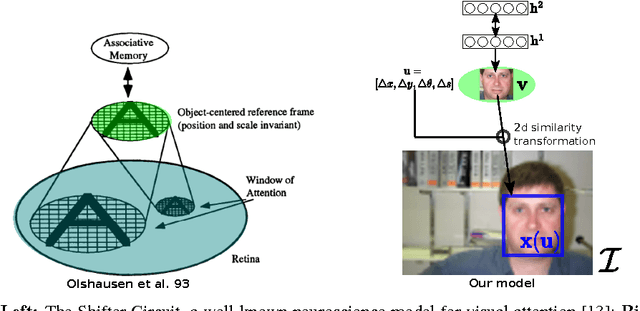

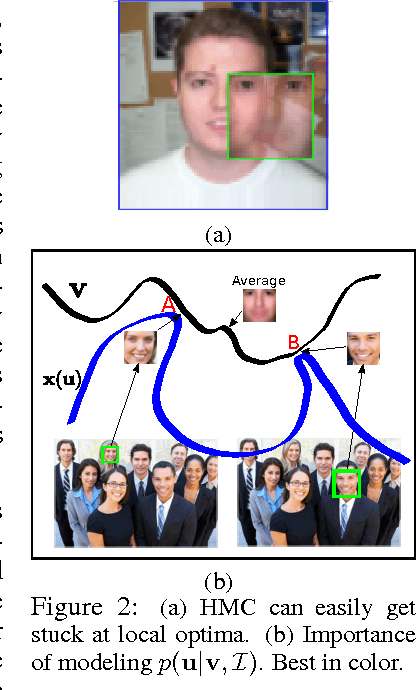
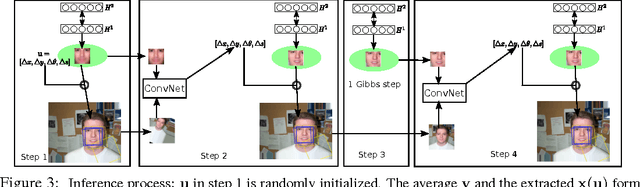
Attention has long been proposed by psychologists as important for effectively dealing with the enormous sensory stimulus available in the neocortex. Inspired by the visual attention models in computational neuroscience and the need of object-centric data for generative models, we describe for generative learning framework using attentional mechanisms. Attentional mechanisms can propagate signals from region of interest in a scene to an aligned canonical representation, where generative modeling takes place. By ignoring background clutter, generative models can concentrate their resources on the object of interest. Our model is a proper graphical model where the 2D Similarity transformation is a part of the top-down process. A ConvNet is employed to provide good initializations during posterior inference which is based on Hamiltonian Monte Carlo. Upon learning images of faces, our model can robustly attend to face regions of novel test subjects. More importantly, our model can learn generative models of new faces from a novel dataset of large images where the face locations are not known.
Modeling Documents with Deep Boltzmann Machines
Sep 26, 2013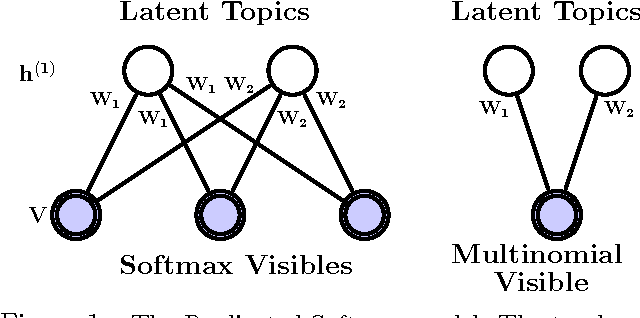
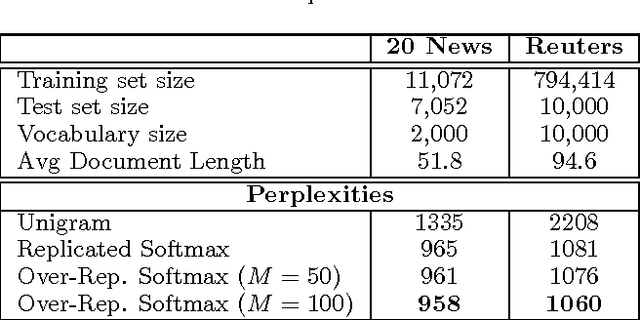
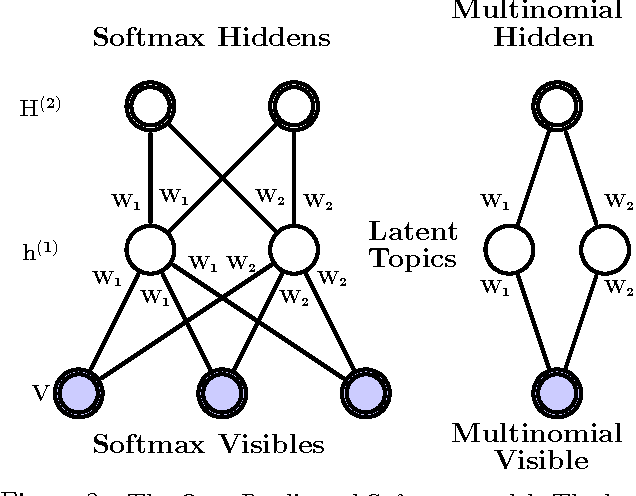
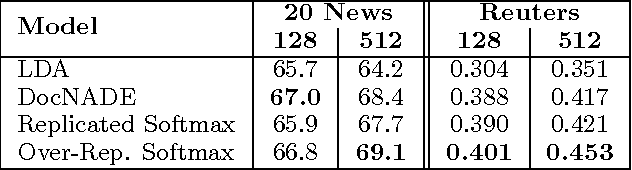
We introduce a Deep Boltzmann Machine model suitable for modeling and extracting latent semantic representations from a large unstructured collection of documents. We overcome the apparent difficulty of training a DBM with judicious parameter tying. This parameter tying enables an efficient pretraining algorithm and a state initialization scheme that aids inference. The model can be trained just as efficiently as a standard Restricted Boltzmann Machine. Our experiments show that the model assigns better log probability to unseen data than the Replicated Softmax model. Features extracted from our model outperform LDA, Replicated Softmax, and DocNADE models on document retrieval and document classification tasks.
Improving neural networks by preventing co-adaptation of feature detectors
Jul 03, 2012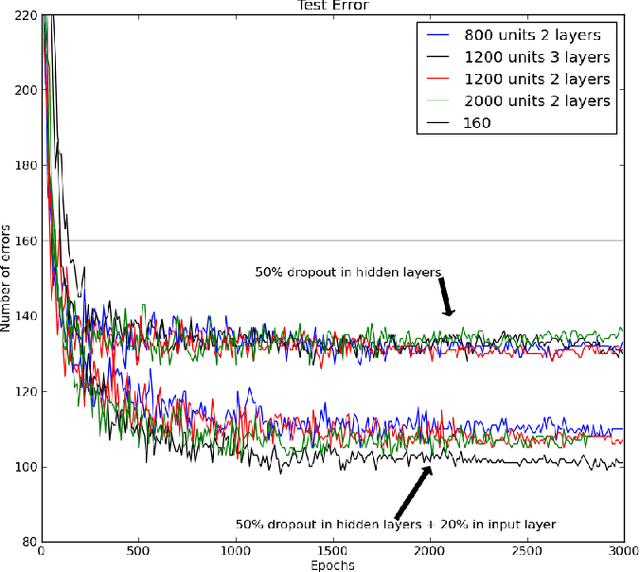
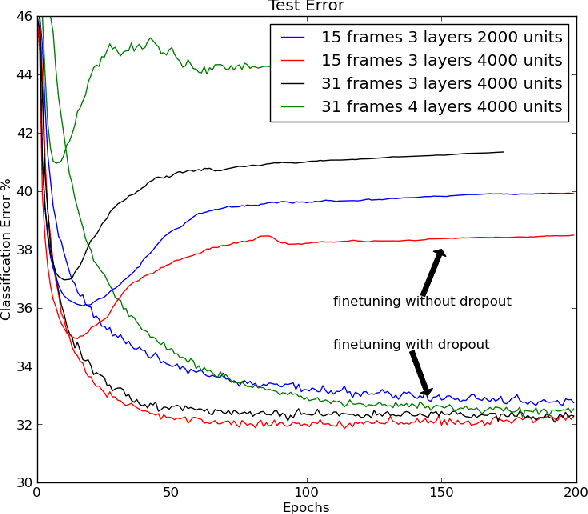


When a large feedforward neural network is trained on a small training set, it typically performs poorly on held-out test data. This "overfitting" is greatly reduced by randomly omitting half of the feature detectors on each training case. This prevents complex co-adaptations in which a feature detector is only helpful in the context of several other specific feature detectors. Instead, each neuron learns to detect a feature that is generally helpful for producing the correct answer given the combinatorially large variety of internal contexts in which it must operate. Random "dropout" gives big improvements on many benchmark tasks and sets new records for speech and object recognition.