 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automated CTC Detection, Segmentation and Classification for Multi-Channel IF Imaging
Oct 03, 2024



Liquid biopsies (eg., blood draws) offer a less invasive and non-localized alternative to tissue biopsies for monitoring the progression of metastatic breast cancer (mBCa). Immunofluoresence (IF) microscopy is a tool to image and analyze millions of blood cells in a patient sample. By detecting and genetically sequencing circulating tumor cells (CTCs) in the blood, personalized treatment plans are achievable for various cancer subtypes. However, CTCs are rare (about 1 in 2M), making manual CTC detection very difficult. In addition, clinicians rely on quantitative cellular biomarkers to manually classify CTCs. This requires prior tasks of cell detection, segmentation and feature extraction. To assist clinicians, we have developed a fully automated machine learning-based production-level pipeline to efficiently detect, segment and classify CTCs in multi-channel IF images. We achieve over 99% sensitivity and 97% specificity on 9,533 cells from 15 mBCa patients. Our pipeline has been successfully deployed on real mBCa patients, reducing a patient average of 14M detected cells to only 335 CTC candidates for manual review.
Appearance invariance in convolutional networks with neighborhood similarity
Jul 03, 2017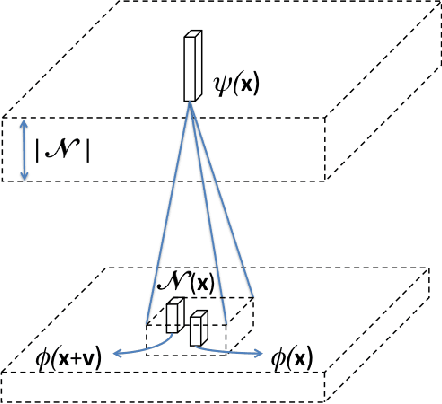
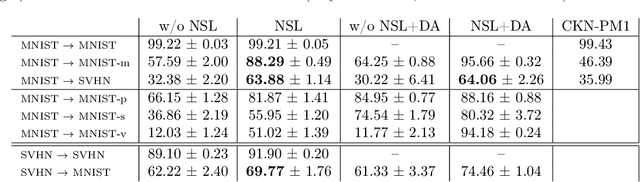
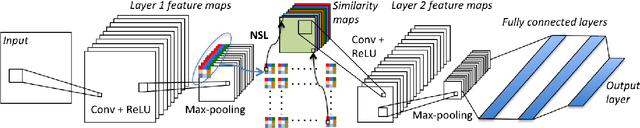
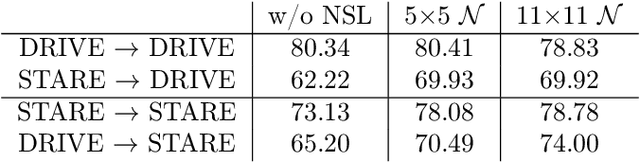
We present a neighborhood similarity layer (NSL) which induces appearance invariance in a network when used in conjunction with convolutional layers. We are motivated by the observation that, even though convolutional networks have low generalization error, their generalization capability does not extend to samples which are not represented by the training data. For instance, while novel appearances of learned concepts pose no problem for the human visual system, feedforward convolutional networks are generally not successful in such situations. Motivated by the Gestalt principle of grouping with respect to similarity, the proposed NSL transforms its input feature map using the feature vectors at each pixel as a frame of reference, i.e. center of attention, for its surrounding neighborhood. This transformation is spatially varying, hence not a convolution. It is differentiable; therefore, networks including the proposed layer can be trained in an end-to-end manner. We analyze the invariance of NSL to significant changes in appearance that are not represented in the training data. We also demonstrate its advantages for digit recognition, semantic labeling and cell detection problems.
SSHMT: Semi-supervised Hierarchical Merge Tree for Electron Microscopy Image Segmentation
Aug 14, 2016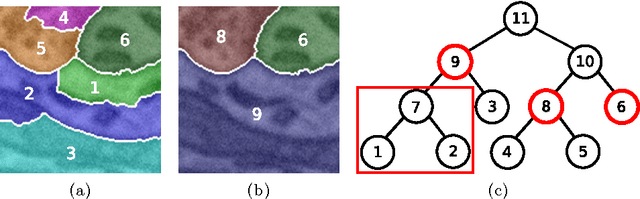
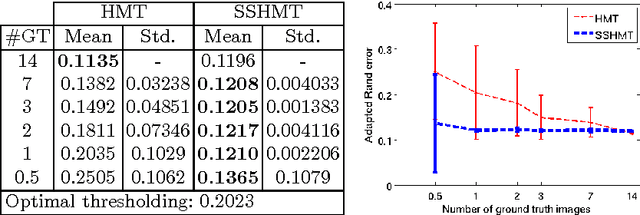


Region-based methods have proven necessary for improving segmentation accuracy of neuronal structures in electron microscopy (EM) images. Most region-based segmentation methods use a scoring function to determine region merging. Such functions are usually learned with supervised algorithms that demand considerable ground truth data, which are costly to collect. We propose a semi-supervised approach that reduces this demand. Based on a merge tree structure, we develop a differentiable unsupervised loss term that enforces consistent predictions from the learned function. We then propose a Bayesian model that combines the supervised and the unsupervised information for probabilistic learning. The experimental results on three EM data sets demonstrate that by using a subset of only 3% to 7% of the entire ground truth data, our approach consistently performs close to the state-of-the-art supervised method with the full labeled data set, and significantly outperforms the supervised method with the same labeled subset.
* Accepted by ECCV 2016