 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchOverflow: Measuring Overflow in Large Language Models via Plain-Text Prompts
Jan 13, 2026We investigate a failure mode of large language models (LLMs) in which plain-text prompts elicit excessive outputs, a phenomenon we term Overflow. Unlike jailbreaks or prompt injection, Overflow arises under ordinary interaction settings and can lead to elevated serving cost, latency, and cross-user performance degradation, particularly when scaled across many requests. Beyond usability, the stakes are economic and environmental: unnecessary tokens increase per-request cost and energy consumption, compounding into substantial operational spend and carbon footprint at scale. Moreover, Overflow represents a practical vector for compute amplification and service degradation in shared environments. We introduce BenchOverflow, a model-agnostic benchmark of nine plain-text prompting strategies that amplify output volume without adversarial suffixes or policy circumvention. Using a standardized protocol with a fixed budget of 5000 new tokens, we evaluate nine open- and closed-source models and observe pronounced rightward shifts and heavy tails in length distributions. Cap-saturation rates (CSR@1k/3k/5k) and empirical cumulative distribution functions (ECDFs) quantify tail risk; within-prompt variance and cross-model correlations show that Overflow is broadly reproducible yet heterogeneous across families and attack vectors. A lightweight mitigation-a fixed conciseness reminder-attenuates right tails and lowers CSR for all strategies across the majority of models. Our findings position length control as a measurable reliability, cost, and sustainability concern rather than a stylistic quirk. By enabling standardized comparison of length-control robustness across models, BenchOverflow provides a practical basis for selecting deployments that minimize resource waste and operating expense, and for evaluating defenses that curb compute amplification without eroding task performance.
Deepchecks: A Library for Testing and Validating Machine Learning Models and Data
Mar 16, 2022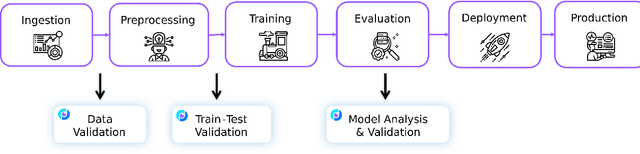
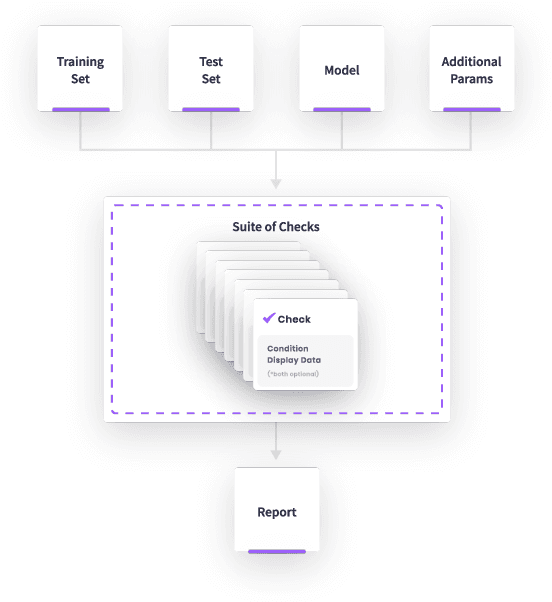
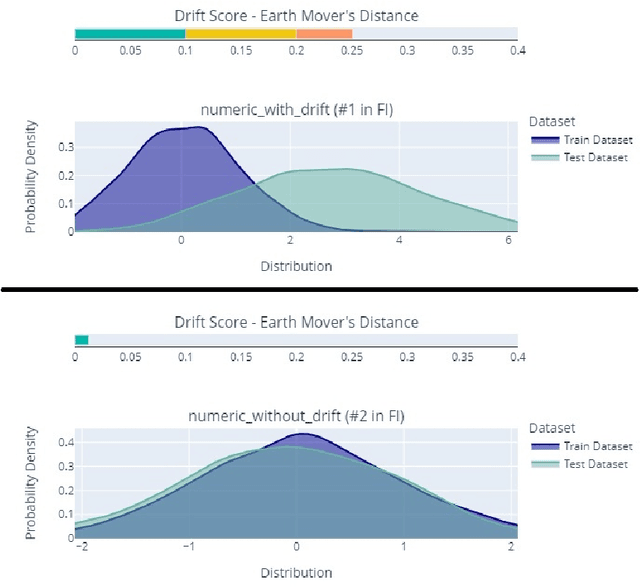
This paper presents Deepchecks, a Python library for comprehensively validating machine learning models and data. Our goal is to provide an easy-to-use library comprising of many checks related to various types of issues, such as model predictive performance, data integrity, data distribution mismatches, and more. The package is distributed under the GNU Affero General Public License (AGPL) and relies on core libraries from the scientific Python ecosystem: scikit-learn, PyTorch, NumPy, pandas, and SciPy. Source code, documentation, examples, and an extensive user guide can be found at \url{https://github.com/deepchecks/deepchecks} and \url{https://docs.deepchecks.com/}.