 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Sketch: Fast and Scalable Polynomial Kernel Approximation
May 13, 2025Approximation of non-linear kernels using random feature maps has become a powerful technique for scaling kernel methods to large datasets. We propose \textit{Tensor Sketch}, an efficient random feature map for approximating polynomial kernels. Given $n$ training samples in $\R^d$ Tensor Sketch computes low-dimensional embeddings in $\R^D$ in time $\BO{n(d+D \log{D})}$ making it well-suited for high-dimensional and large-scale settings. We provide theoretical guarantees on the approximation error, ensuring the fidelity of the resulting kernel function estimates. We also discuss extensions and highlight applications where Tensor Sketch serves as a central computational tool.
Scalable Density-based Clustering with Random Projections
Feb 24, 2024We present sDBSCAN, a scalable density-based clustering algorithm in high dimensions with cosine distance. Utilizing the neighborhood-preserving property of random projections, sDBSCAN can quickly identify core points and their neighborhoods, the primary hurdle of density-based clustering. Theoretically, sDBSCAN outputs a clustering structure similar to DBSCAN under mild conditions with high probability. To further facilitate sDBSCAN, we present sOPTICS, a scalable OPTICS for interactive exploration of the intrinsic clustering structure. We also extend sDBSCAN and sOPTICS to L2, L1, $\chi^2$, and Jensen-Shannon distances via random kernel features. Empirically, sDBSCAN is significantly faster and provides higher accuracy than many other clustering algorithms on real-world million-point data sets. On these data sets, sDBSCAN and sOPTICS run in a few minutes, while the scikit-learn's counterparts demand several hours or cannot run due to memory constraints.
Falconn++: A Locality-sensitive Filtering Approach for Approximate Nearest Neighbor Search
Jun 03, 2022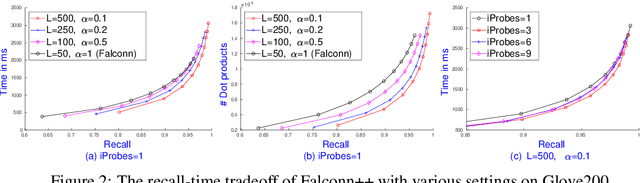

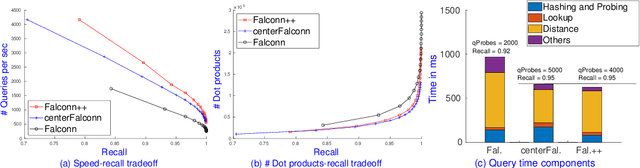
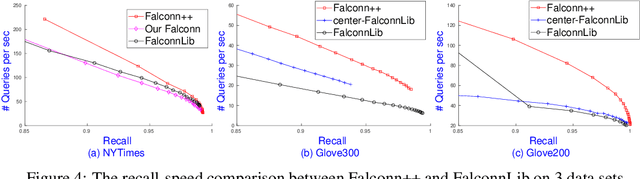
We present Falconn++, a novel locality-sensitive filtering (LSF) approach for approximate nearest neighbor search on angular distance. Falconn++ can filter out potential far away points in any hash bucket before querying, which results in higher quality candidates compared to other hashing-based solutions. Theoretically, Falconn++ asymptotically achieves lower query time complexity than Falconn, an optimal locality-sensitive hashing scheme on angular distance. Empirically, Falconn++ achieves a higher recall-speed tradeoff than Falconn on many real-world data sets. Falconn++ is also competitive against HNSW, an efficient representative of graph-based solutions on high search recall regimes.
An Efficient Hashing-based Ensemble Method for Collaborative Outlier Detection
Jan 18, 2022In collaborative outlier detection, multiple participants exchange their local detectors trained on decentralized devices without exchanging their own data. A key problem of collaborative outlier detection is efficiently aggregating multiple local detectors to form a global detector without breaching the privacy of participants' data and degrading the detection accuracy. We study locality-sensitive hashing-based ensemble methods to detect collaborative outliers since they are mergeable and compatible with differentially private mechanisms. Our proposed LSH iTables is simple and outperforms recent ensemble competitors on centralized and decentralized scenarios over many real-world data sets.