 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Ranked List Truncation for Reranking Pipelines via LLM-generated Reference-Documents
Apr 10, 2026Large Language Models (LLM) have been widely used in reranking. Computational overhead and large context lengths remain a challenging issue for LLM rerankers. Efficient reranking usually involves selecting a subset of the ranked list from the first stage, known as ranked list truncation (RLT). The truncated list is processed further by a reranker. For LLM rerankers, the ranked list is often partitioned and processed sequentially in batches to reduce the context length. Both these steps involve hyperparameters and topic-agnostic heuristics. Recently, LLMs have been shown to be effective for relevance judgment. Equivalently, we propose that LLMs can be used to generate reference documents that can act as a pivot between relevant and non-relevant documents in a ranked list. We propose methods to use these generated reference documents for RLT as well as for efficient listwise reranking. While reranking, we process the ranked list in either parallel batches of non-overlapping windows or overlapping windows with adaptive strides, improving the existing fixed stride setup. The generated reference documents are also shown to improve existing efficient listwise reranking frameworks. Experiments on TREC Deep Learning benchmarks show that our approach outperforms existing RLT-based approaches. In-domain and out-of-domain benchmarks demonstrate that our proposed methods accelerate LLM-based listwise reranking by up to 66\% compared to existing approaches. This work not only establishes a practical paradigm for efficient LLM-based reranking but also provides insight into the capability of LLMs to generate semantically controlled documents using relevance signals.
Modeling Ranking Properties with In-Context Learning
May 23, 2025While standard IR models are mainly designed to optimize relevance, real-world search often needs to balance additional objectives such as diversity and fairness. These objectives depend on inter-document interactions and are commonly addressed using post-hoc heuristics or supervised learning methods, which require task-specific training for each ranking scenario and dataset. In this work, we propose an in-context learning (ICL) approach that eliminates the need for such training. Instead, our method relies on a small number of example rankings that demonstrate the desired trade-offs between objectives for past queries similar to the current input. We evaluate our approach on four IR test collections to investigate multiple auxiliary objectives: group fairness (TREC Fairness), polarity diversity (Touch\'e), and topical diversity (TREC Deep Learning 2019/2020). We empirically validate that our method enables control over ranking behavior through demonstration engineering, allowing nuanced behavioral adjustments without explicit optimization.
Few-shot Pairwise Rank Prompting: An Effective Non-Parametric Retrieval Model
Sep 27, 2024A supervised ranking model, despite its advantage of being effective, usually involves complex processing - typically multiple stages of task-specific pre-training and fine-tuning. This has motivated researchers to explore simpler pipelines leveraging large language models (LLMs) that are capable of working in a zero-shot manner. However, since zero-shot inference does not make use of a training set of pairs of queries and their relevant documents, its performance is mostly worse than that of supervised models, which are trained on such example pairs. Motivated by the existing findings that training examples generally improve zero-shot performance, in our work, we explore if this also applies to ranking models. More specifically, given a query and a pair of documents, the preference prediction task is improved by augmenting examples of preferences for similar queries from a training set. Our proposed pairwise few-shot ranker demonstrates consistent improvements over the zero-shot baseline on both in-domain (TREC DL) and out-domain (BEIR subset) retrieval benchmarks. Our method also achieves a close performance to that of a supervised model without requiring any complex training pipeline.
Medical Information Retrieval and Interpretation: A Question-Answer based Interaction Model
Jan 24, 2021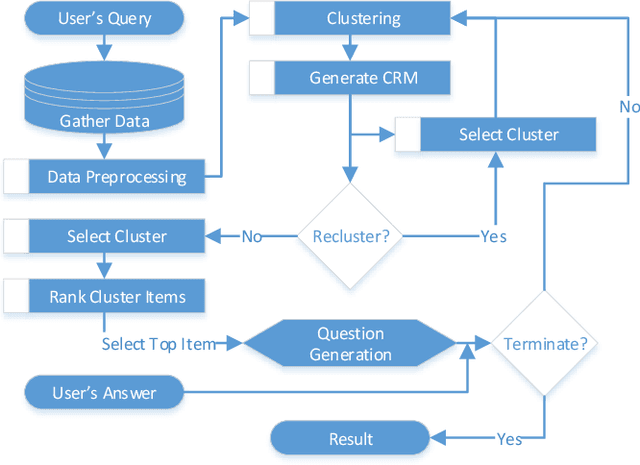
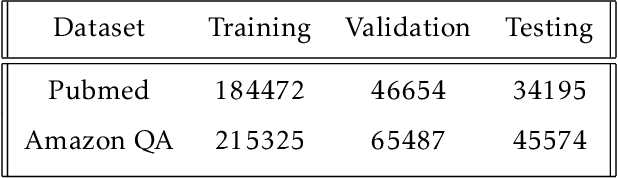
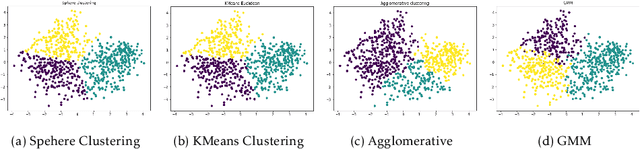
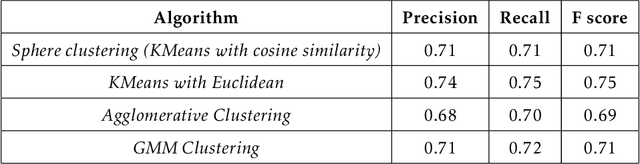
The Internet has become a very powerful platform where diverse medical information are expressed daily. Recently, a huge growth is seen in searches like symptoms, diseases, medicines, and many other health related queries around the globe. The search engines typically populate the result by using the single query provided by the user and hence reaching to the final result may require a lot of manual filtering from the user's end. Current search engines and recommendation systems still lack real time interactions that may provide more precise result generation. This paper proposes an intelligent and interactive system tied up with the vast medical big data repository on the web and illustrates its potential in finding medical information.
Computational Intelligence Approach to Improve the Classification Accuracy of Brain Neoplasm in MRI Data
Jan 24, 2021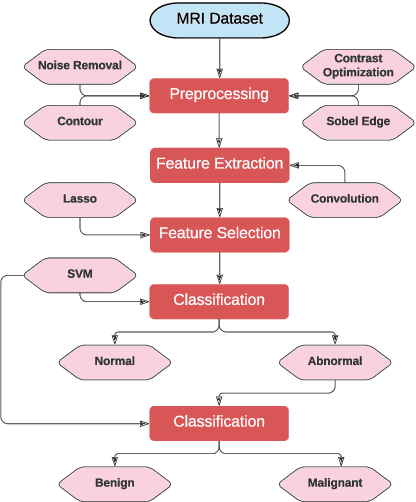
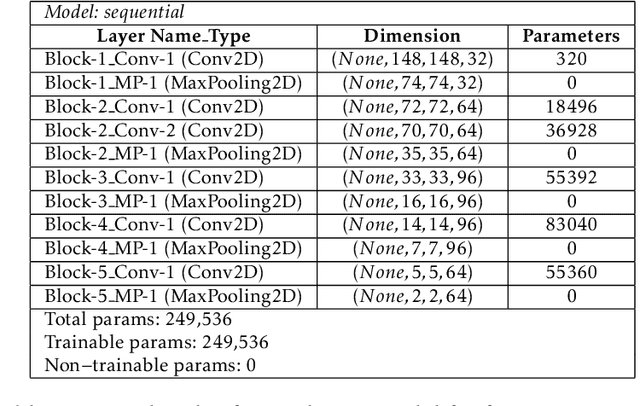
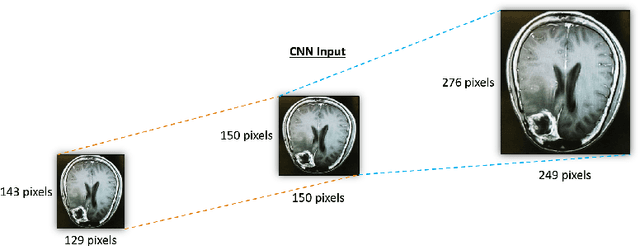
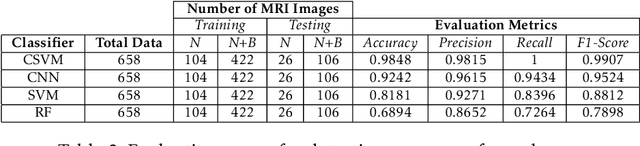
Automatic detection of brain neoplasm in Magnetic Resonance Imaging (MRI) is gaining importance in many medical diagnostic applications. This report presents two improvements for brain neoplasm detection in MRI data: an advanced preprocessing technique is proposed to improve the area of interest in MRI data and a hybrid technique using Convolutional Neural Network (CNN) for feature extraction followed by Support Vector Machine (SVM) for classification. The learning algorithm for SVM is modified with the addition of cost function to minimize false positive prediction addressing the errors in MRI data diagnosis. The proposed approach can effectively detect the presence of neoplasm and also predict whether it is cancerous (malignant) or non-cancerous (benign). To check the effectiveness of the proposed preprocessing technique, it is inspected visually and evaluated using training performance metrics. A comparison study between the proposed classification technique and the existing techniques was performed. The result showed that the proposed approach outperformed in terms of accuracy and can handle errors in classification better than the existing approaches.