 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalization of Different Swedish Dialects Spoken in Finland
Dec 09, 2020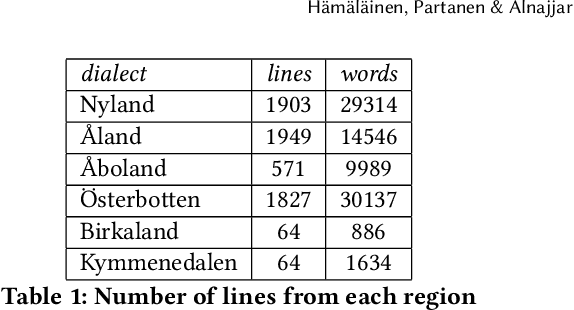

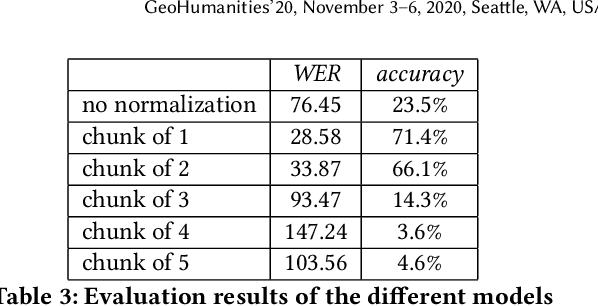
Our study presents a dialect normalization method for different Finland Swedish dialects covering six regions. We tested 5 different models, and the best model improved the word error rate from 76.45 to 28.58. Contrary to results reported in earlier research on Finnish dialects, we found that training the model with one word at a time gave best results. We believe this is due to the size of the training data available for the model. Our models are accessible as a Python package. The study provides important information about the adaptability of these methods in different contexts, and gives important baselines for further study.
Ve'rdd. Narrowing the Gap between Paper Dictionaries, Low-Resource NLP and Community Involvement
Dec 04, 2020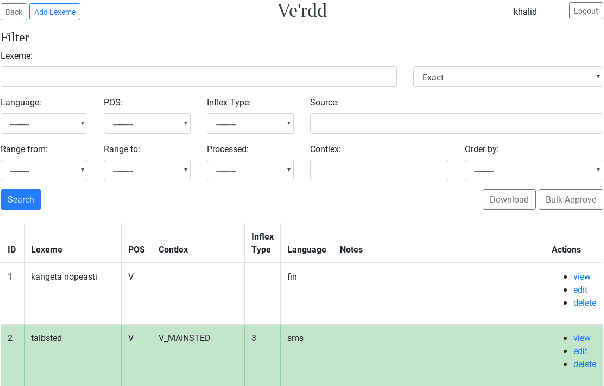
We present an open-source online dictionary editing system, Ve'rdd, that offers a chance to re-evaluate and edit grassroots dictionaries that have been exposed to multiple amateur editors. The idea is to incorporate community activities into a state-of-the-art finite-state language description of a seriously endangered minority language, Skolt Sami. Problems involve getting the community to take part in things above the pencil-and-paper level. At times, it seems that the native speakers and the dictionary oriented are lacking technical understanding to utilize the infrastructures which might make their work more meaningful in the future, i.e. multiple reuse of all of their input. Therefore, our system integrates with the existing tools and infrastructures for Uralic language masking the technical complexities behind a user-friendly UI.
Automated Prediction of Medieval Arabic Diacritics
Oct 11, 2020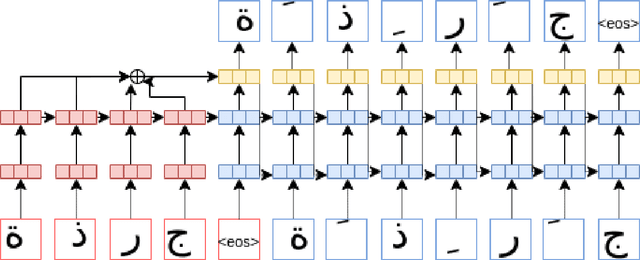

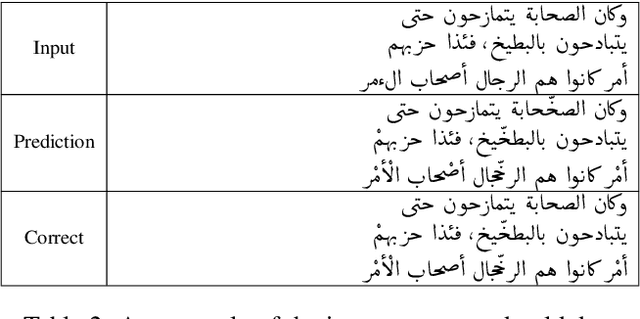
This study uses a character level neural machine translation approach trained on a long short-term memory-based bi-directional recurrent neural network architecture for diacritization of Medieval Arabic. The results improve from the online tool used as a baseline. A diacritization model have been published openly through an easy to use Python package available on PyPi and Zenodo. We have found that context size should be considered when optimizing a feasible prediction model.
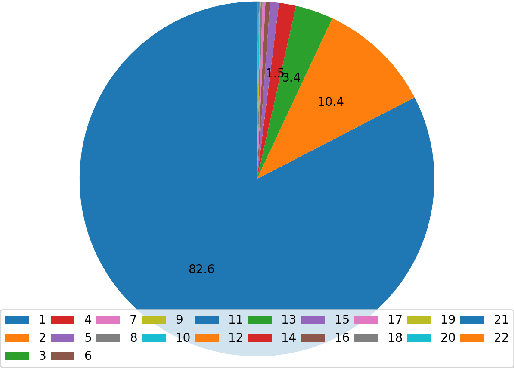
Automatic Dialect Adaptation in Finnish and its Effect on Perceived Creativity
Sep 06, 2020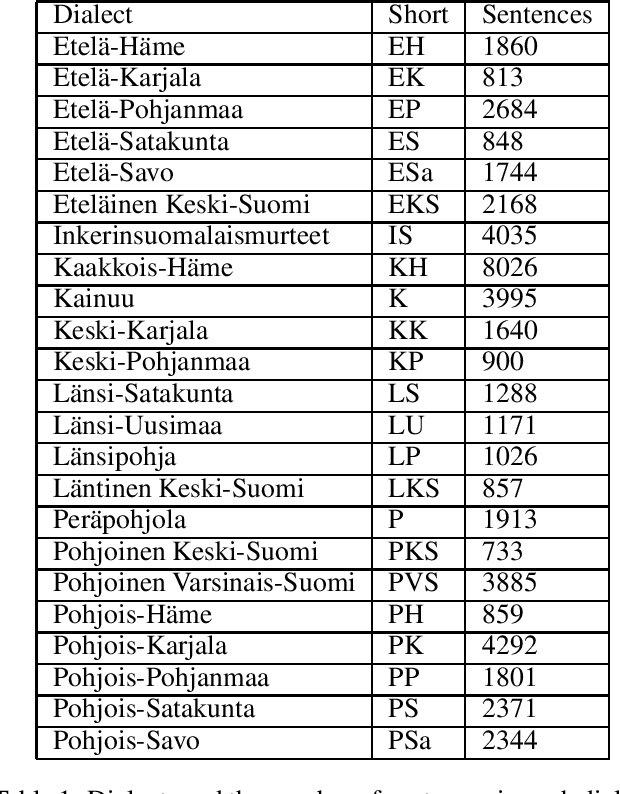

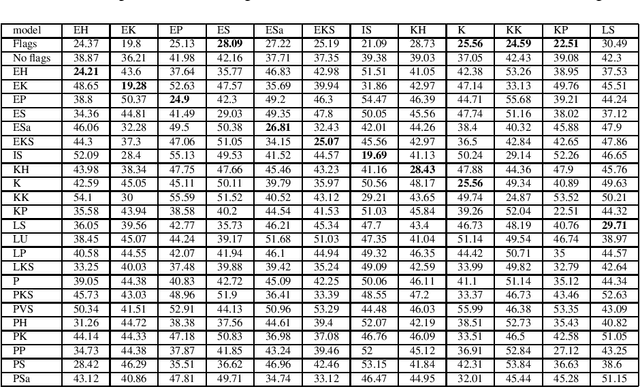
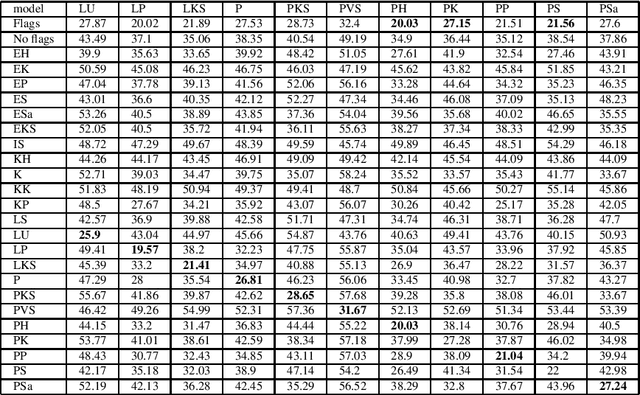
We present a novel approach for adapting text written in standard Finnish to different dialects. We experiment with character level NMT models both by using a multi-dialectal and transfer learning approaches. The models are tested with over 20 different dialects. The results seem to favor transfer learning, although not strongly over the multi-dialectal approach. We study the influence dialectal adaptation has on perceived creativity of computer generated poetry. Our results suggest that the more the dialect deviates from the standard Finnish, the lower scores people tend to give on an existing evaluation metric. However, on a word association test, people associate creativity and originality more with dialect and fluency more with standard Finnish.
Uralic Language Identification (ULI) 2020 shared task dataset and the Wanca 2017 corpus
Aug 27, 2020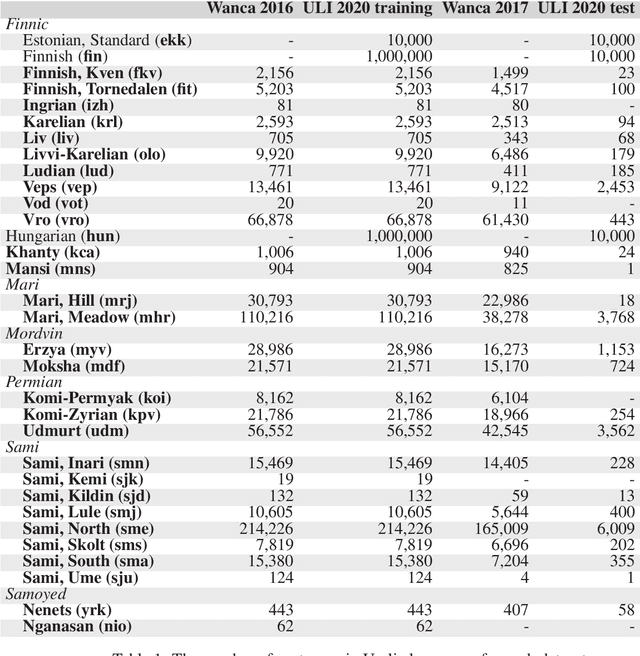

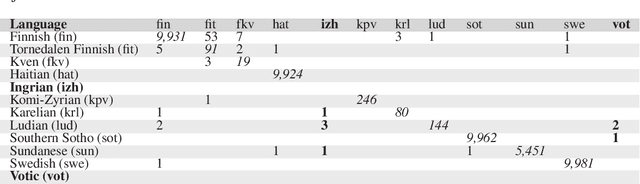
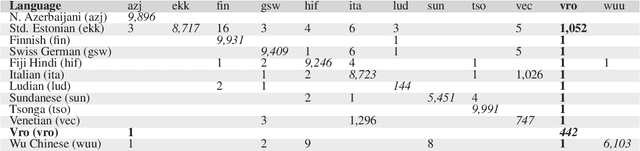
This article introduces the Wanca 2017 corpus of texts crawled from the internet from which the sentences in rare Uralic languages for the use of the Uralic Language Identification (ULI) 2020 shared task were collected. We describe the ULI dataset and how it was constructed using the Wanca 2017 corpus and texts in different languages from the Leipzig corpora collection. We also provide baseline language identification experiments conducted using the ULI 2020 dataset.