Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalization of Different Swedish Dialects Spoken in Finland
Paper and Code
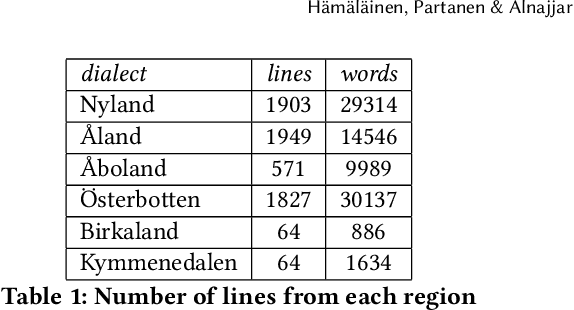
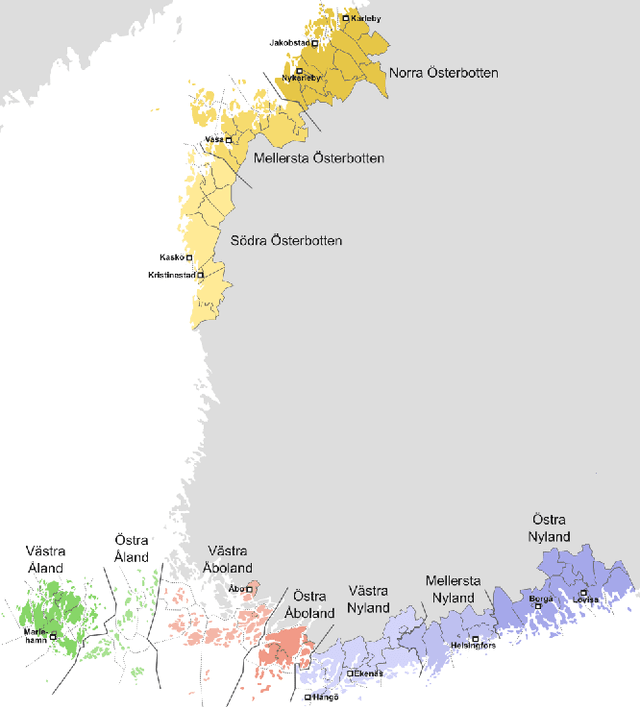

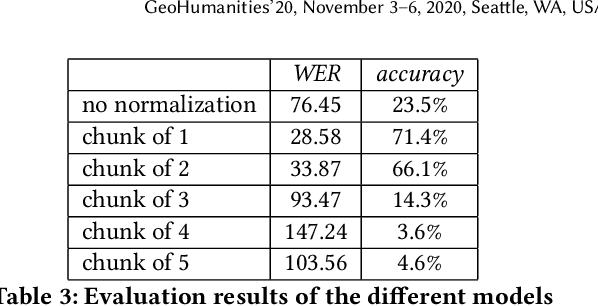
Our study presents a dialect normalization method for different Finland Swedish dialects covering six regions. We tested 5 different models, and the best model improved the word error rate from 76.45 to 28.58. Contrary to results reported in earlier research on Finnish dialects, we found that training the model with one word at a time gave best results. We believe this is due to the size of the training data available for the model. Our models are accessible as a Python package. The study provides important information about the adaptability of these methods in different contexts, and gives important baselines for further study.
* In Proceedings of the 4th ACM SIGSPATIAL Workshop on Geospatial
Humanities (GeoHumanities'20)
View paper on