 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Preserving Gaussian Processes Via Discrete Euler-Lagrange Equations
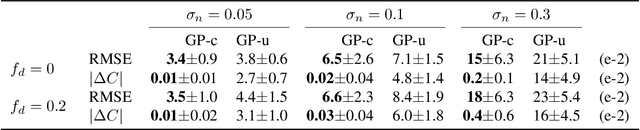
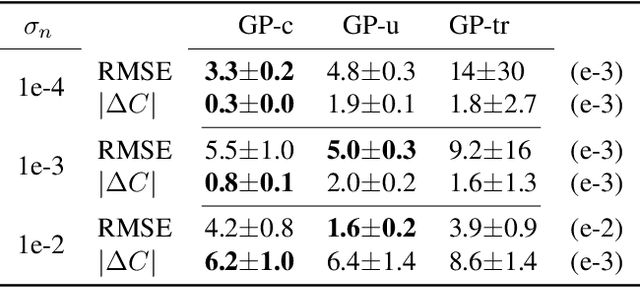
May 07, 2026In this paper, we propose Lagrangian Gaussian Processes (LGPs) for probabilistic and data-efficient learning of dynamics via discrete forced Euler-Lagrange equations. Importantly, the geometric structure of the Lagrange-d'Alembert principle, which governs the motion of dynamical systems, is preserved by construction in the absence of external forces. This allows learning physically consistent models that overcome erroneous drift in the system's energy, thereby providing stable long-term predictions. At the core of our approach lie linear operators for Gaussian process conditioning, constructed from discrete forced Euler-Lagrange equations and variational discretization schemes. Thereby and unlike prior work, the method enables learning dynamics from discrete position snapshots, i.e., without access to a system's velocities or momenta. This is particularly relevant for a large class of practical scenarios where only position measurements are available, for instance, in motion capture or visual servoing applications. We demonstrate the data-efficiency and generalization capabilities of the LGPs in various synthetic and real-world case studies, including a real-world soft robot with hysteresis. The experimental results underscore that the LGPs learn physically consistent dynamics with uncertainty quantification solely from sparse positional data and enable stable long-term predictions.
Simultaneous State Estimation and Online Model Learning in a Soft Robotic System
Feb 15, 2026Operating complex real-world systems, such as soft robots, can benefit from precise predictive control schemes that require accurate state and model knowledge. This knowledge is typically not available in practical settings and must be inferred from noisy measurements. In particular, it is challenging to simultaneously estimate unknown states and learn a model online from sequentially arriving measurements. In this paper, we show how a recently proposed gray-box system identification tool enables the estimation of a soft robot's current pose while at the same time learning a bending stiffness model. For estimation and learning, we rely solely on a nominal constant-curvature robot model and measurements of the robot's base reactions (e.g., base forces). The estimation scheme -- relying on a marginalized particle filter -- allows us to conveniently interface nominal constant-curvature equations with a Gaussian Process (GP) bending stiffness model to be learned. This, in contrast to estimation via a random walk over stiffness values, enables prediction of bending stiffness and improves overall model quality. We demonstrate, using real-world soft-robot data, that the method learns a bending stiffness model online while accurately estimating the robot's pose. Notably, reduced multi-step forward-prediction errors indicate that the learned bending-stiffness GP improves overall model quality.
Learning Dynamics from Input-Output Data with Hamiltonian Gaussian Processes
Nov 07, 2025Embedding non-restrictive prior knowledge, such as energy conservation laws, in learning-based approaches is a key motive to construct physically consistent models from limited data, relevant for, e.g., model-based control. Recent work incorporates Hamiltonian dynamics into Gaussian Process (GP) regression to obtain uncertainty-quantifying models that adhere to the underlying physical principles. However, these works rely on velocity or momentum data, which is rarely available in practice. In this paper, we consider dynamics learning with non-conservative Hamiltonian GPs, and address the more realistic problem setting of learning from input-output data. We provide a fully Bayesian scheme for estimating probability densities of unknown hidden states, of GP hyperparameters, as well as of structural hyperparameters, such as damping coefficients. Considering the computational complexity of GPs, we take advantage of a reduced-rank GP approximation and leverage its properties for computationally efficient prediction and training. The proposed method is evaluated in a nonlinear simulation case study and compared to a state-of-the-art approach that relies on momentum measurements.
Repulsive Ensembles for Bayesian Inference in Physics-informed Neural Networks
May 22, 2025Physics-informed neural networks (PINNs) have proven an effective tool for solving differential equations, in particular when considering non-standard or ill-posed settings. When inferring solutions and parameters of the differential equation from data, uncertainty estimates are preferable to point estimates, as they give an idea about the accuracy of the solution. In this work, we consider the inverse problem and employ repulsive ensembles of PINNs (RE-PINN) for obtaining such estimates. The repulsion is implemented by adding a particular repulsive term to the loss function, which has the property that the ensemble predictions correspond to the true Bayesian posterior in the limit of infinite ensemble members. Where possible, we compare the ensemble predictions to Monte Carlo baselines. Whereas the standard ensemble tends to collapse to maximum-a-posteriori solutions, the repulsive ensemble produces significantly more accurate uncertainty estimates and exhibits higher sample diversity.
Probabilistic matching of real and generated data statistics in generative adversarial networks
Jun 19, 2023



Generative adversarial networks constitute a powerful approach to generative modeling. While generated samples often are indistinguishable from real data, there is no guarantee that they will follow the true data distribution. In this work, we propose a method to ensure that the distributions of certain generated data statistics coincide with the respective distributions of the real data. In order to achieve this, we add a Kullback-Leibler term to the generator loss function: the KL divergence is taken between the true distributions as represented by a conditional energy-based model, and the corresponding generated distributions obtained from minibatch values at each iteration. We evaluate the method on a synthetic dataset and two real-world datasets and demonstrate improved performance of our method.
Invertible Kernel PCA with Random Fourier Features
Mar 09, 2023



Kernel principal component analysis (kPCA) is a widely studied method to construct a low-dimensional data representation after a nonlinear transformation. The prevailing method to reconstruct the original input signal from kPCA -- an important task for denoising -- requires us to solve a supervised learning problem. In this paper, we present an alternative method where the reconstruction follows naturally from the compression step. We first approximate the kernel with random Fourier features. Then, we exploit the fact that the nonlinear transformation is invertible in a certain subdomain. Hence, the name \emph{invertible kernel PCA (ikPCA)}. We experiment with different data modalities and show that ikPCA performs similarly to kPCA with supervised reconstruction on denoising tasks, making it a strong alternative.
Physics-informed neural networks with unknown measurement noise
Nov 28, 2022Physics-informed neural networks (PINNs) constitute a flexible approach to both finding solutions and identifying parameters of partial differential equations. Most works on the topic assume noiseless data, or data contaminated by weak Gaussian noise. We show that the standard PINN framework breaks down in case of non-Gaussian noise. We give a way of resolving this fundamental issue and we propose to jointly train an energy-based model (EBM) to learn the correct noise distribution. We illustrate the improved performance of our approach using multiple examples.
Incorporating Sum Constraints into Multitask Gaussian Processes
Feb 03, 2022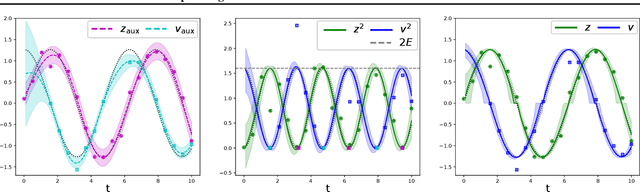
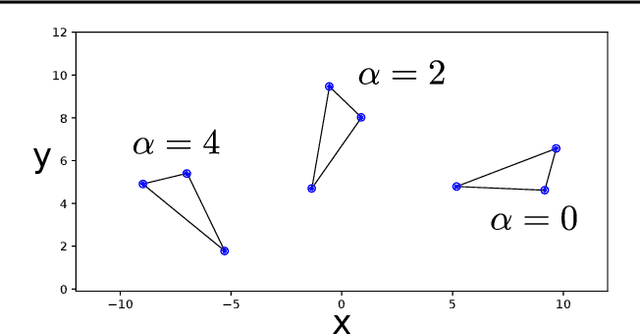
Machine learning models can be improved by adapting them to respect existing background knowledge. In this paper we consider multitask Gaussian processes, with background knowledge in the form of constraints that require a specific sum of the outputs to be constant. This is achieved by conditioning the prior distribution on the constraint fulfillment. The approach allows for both linear and nonlinear constraints. We demonstrate that the constraints are fulfilled with high precision and that the construction can improve the overall prediction accuracy as compared to the standard Gaussian process.
Learning deep autoregressive models for hierarchical data
May 06, 2021
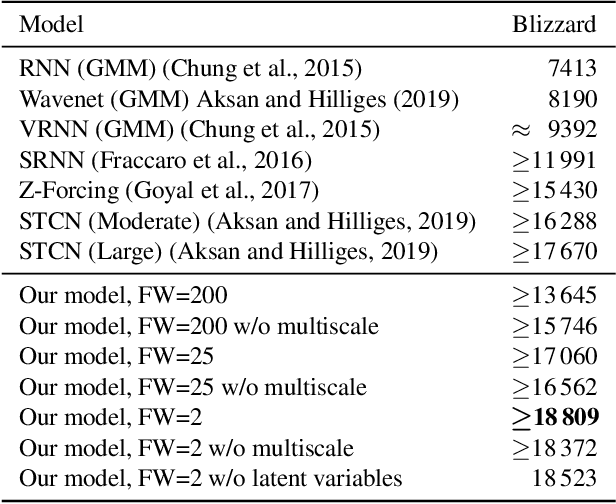
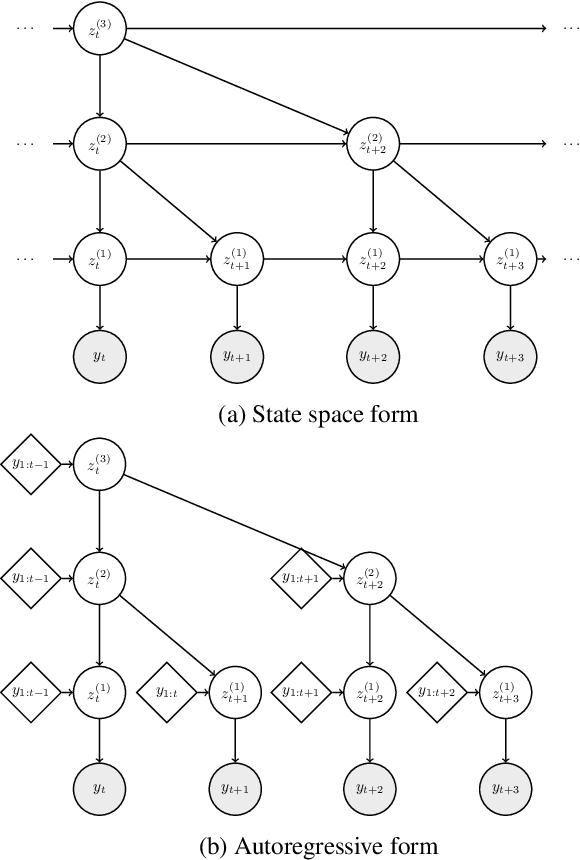
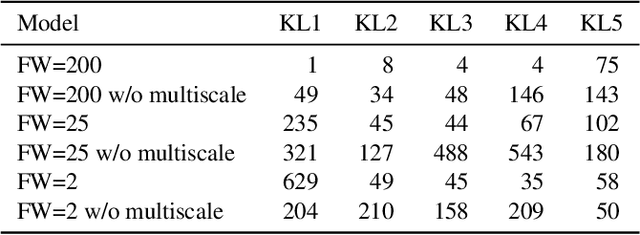
We propose a model for hierarchical structured data as an extension to the stochastic temporal convolutional network. The proposed model combines an autoregressive model with a hierarchical variational autoencoder and downsampling to achieve superior computational complexity. We evaluate the proposed model on two different types of sequential data: speech and handwritten text. The results are promising with the proposed model achieving state-of-the-art performance.
Deep State Space Models for Nonlinear System Identification
Mar 31, 2020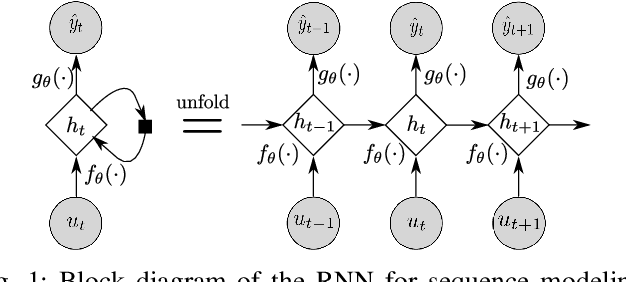
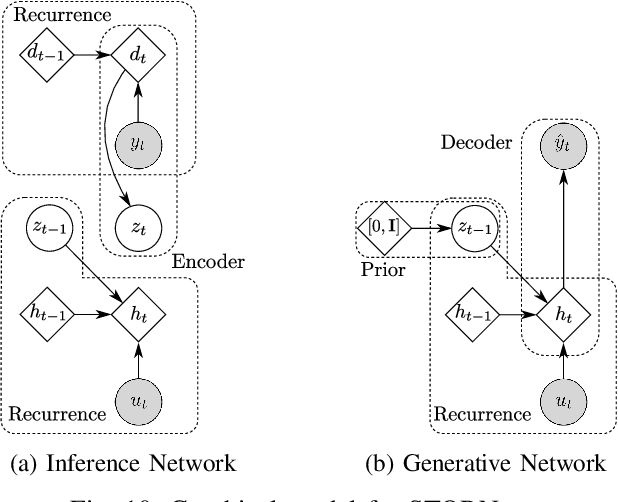
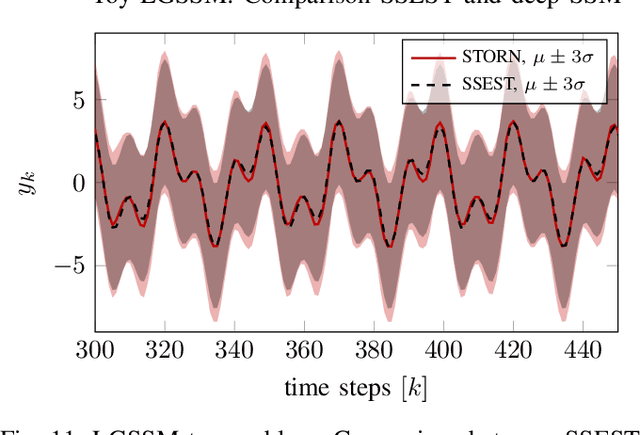
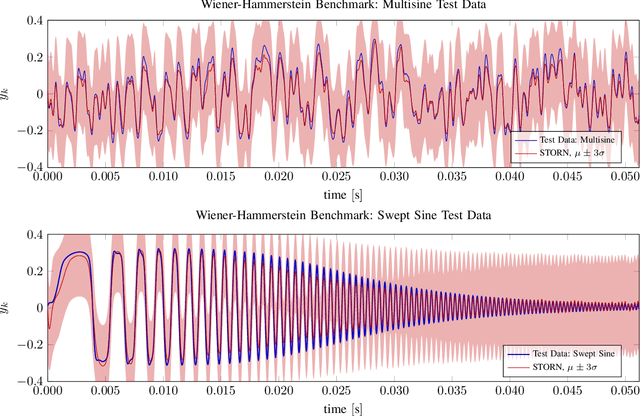
An actively evolving model class for generative temporal models developed in the deep learning community are deep state space models (SSMs) which have a close connection to classic SSMs. In this work six new deep SSMs are implemented and evaluated for the identification of established nonlinear dynamic system benchmarks. The models and their parameter learning algorithms are elaborated rigorously. The usage of deep SSMs as a black-box identification model can describe a wide range of dynamics due to the flexibility of deep neural networks. Additionally, the uncertainty of the system is modelled and therefore one obtains a much richer representation and a whole class of systems to describe the underlying dynamics.