 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hitchhikers Guide to Fine-Grained Face Forgery Detection Using Common Sense Reasoning
Oct 01, 2024



Explainability in artificial intelligence is crucial for restoring trust, particularly in areas like face forgery detection, where viewers often struggle to distinguish between real and fabricated content. Vision and Large Language Models (VLLM) bridge computer vision and natural language, offering numerous applications driven by strong common-sense reasoning. Despite their success in various tasks, the potential of vision and language remains underexplored in face forgery detection, where they hold promise for enhancing explainability by leveraging the intrinsic reasoning capabilities of language to analyse fine-grained manipulation areas. As such, there is a need for a methodology that converts face forgery detection to a Visual Question Answering (VQA) task to systematically and fairly evaluate these capabilities. Previous efforts for unified benchmarks in deepfake detection have focused on the simpler binary task, overlooking evaluation protocols for fine-grained detection and text-generative models. We propose a multi-staged approach that diverges from the traditional binary decision paradigm to address this gap. In the first stage, we assess the models' performance on the binary task and their sensitivity to given instructions using several prompts. In the second stage, we delve deeper into fine-grained detection by identifying areas of manipulation in a multiple-choice VQA setting. In the third stage, we convert the fine-grained detection to an open-ended question and compare several matching strategies for the multi-label classification task. Finally, we qualitatively evaluate the fine-grained responses of the VLLMs included in the benchmark. We apply our benchmark to several popular models, providing a detailed comparison of binary, multiple-choice, and open-ended VQA evaluation across seven datasets. \url{https://nickyfot.github.io/hitchhickersguide.github.io/}
VLLMs Provide Better Context for Emotion Understanding Through Common Sense Reasoning
Apr 10, 2024



Recognising emotions in context involves identifying the apparent emotions of an individual, taking into account contextual cues from the surrounding scene. Previous approaches to this task have involved the design of explicit scene-encoding architectures or the incorporation of external scene-related information, such as captions. However, these methods often utilise limited contextual information or rely on intricate training pipelines. In this work, we leverage the groundbreaking capabilities of Vision-and-Large-Language Models (VLLMs) to enhance in-context emotion classification without introducing complexity to the training process in a two-stage approach. In the first stage, we propose prompting VLLMs to generate descriptions in natural language of the subject's apparent emotion relative to the visual context. In the second stage, the descriptions are used as contextual information and, along with the image input, are used to train a transformer-based architecture that fuses text and visual features before the final classification task. Our experimental results show that the text and image features have complementary information, and our fused architecture significantly outperforms the individual modalities without any complex training methods. We evaluate our approach on three different datasets, namely, EMOTIC, CAER-S, and BoLD, and achieve state-of-the-art or comparable accuracy across all datasets and metrics compared to much more complex approaches. The code will be made publicly available on github: https://github.com/NickyFot/EmoCommonSense.git
EmoCLIP: A Vision-Language Method for Zero-Shot Video Facial Expression Recognition
Oct 25, 2023Facial Expression Recognition (FER) is a crucial task in affective computing, but its conventional focus on the seven basic emotions limits its applicability to the complex and expanding emotional spectrum. To address the issue of new and unseen emotions present in dynamic in-the-wild FER, we propose a novel vision-language model that utilises sample-level text descriptions (i.e. captions of the context, expressions or emotional cues) as natural language supervision, aiming to enhance the learning of rich latent representations, for zero-shot classification. To test this, we evaluate using zero-shot classification of the model trained on sample-level descriptions on four popular dynamic FER datasets. Our findings show that this approach yields significant improvements when compared to baseline methods. Specifically, for zero-shot video FER, we outperform CLIP by over 10\% in terms of Weighted Average Recall and 5\% in terms of Unweighted Average Recall on several datasets. Furthermore, we evaluate the representations obtained from the network trained using sample-level descriptions on the downstream task of mental health symptom estimation, achieving performance comparable or superior to state-of-the-art methods and strong agreement with human experts. Namely, we achieve a Pearson's Correlation Coefficient of up to 0.85 on schizophrenia symptom severity estimation, which is comparable to human experts' agreement. The code is publicly available at: https://github.com/NickyFot/EmoCLIP.
Learning from Label Relationships in Human Affect
Jul 12, 2022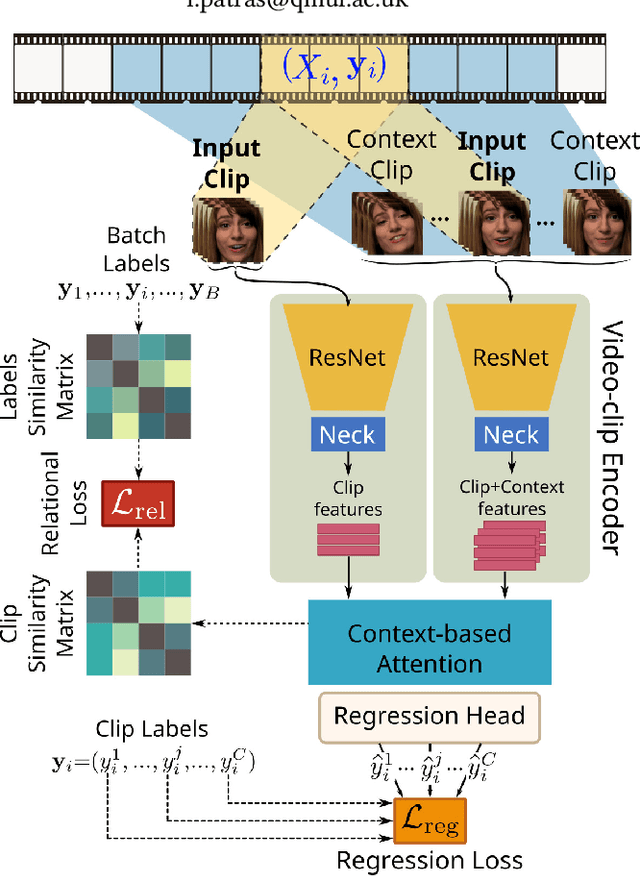
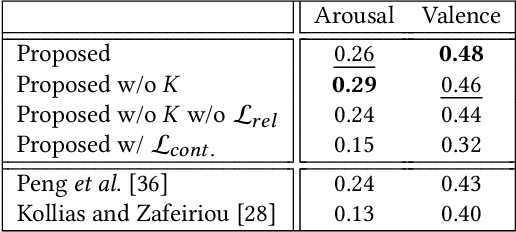
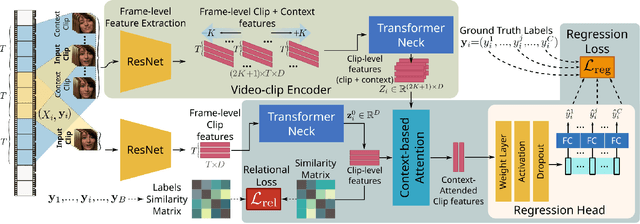
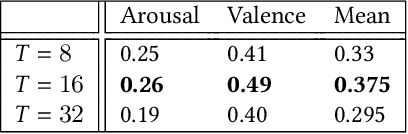
Human affect and mental state estimation in an automated manner, face a number of difficulties, including learning from labels with poor or no temporal resolution, learning from few datasets with little data (often due to confidentiality constraints) and, (very) long, in-the-wild videos. For these reasons, deep learning methodologies tend to overfit, that is, arrive at latent representations with poor generalisation performance on the final regression task. To overcome this, in this work, we introduce two complementary contributions. First, we introduce a novel relational loss for multilabel regression and ordinal problems that regularises learning and leads to better generalisation. The proposed loss uses label vector inter-relational information to learn better latent representations by aligning batch label distances to the distances in the latent feature space. Second, we utilise a two-stage attention architecture that estimates a target for each clip by using features from the neighbouring clips as temporal context. We evaluate the proposed methodology on both continuous affect and schizophrenia severity estimation problems, as there are methodological and contextual parallels between the two. Experimental results demonstrate that the proposed methodology outperforms all baselines. In the domain of schizophrenia, the proposed methodology outperforms previous state-of-the-art by a large margin, achieving a PCC of up to 78% performance close to that of human experts (85%) and much higher than previous works (uplift of up to 40%). In the case of affect recognition, we outperform previous vision-based methods in terms of CCC on both the OMG and the AMIGOS datasets. Specifically for AMIGOS, we outperform previous SoTA CCC for both arousal and valence by 9% and 13% respectively, and in the OMG dataset we outperform previous vision works by up to 5% for both arousal and valence.