 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Did Your Model Learn That? Label-free Influence for Self-supervised Learning
Dec 22, 2024Self-supervised learning (SSL) has revolutionized learning from large-scale unlabeled datasets, yet the intrinsic relationship between pretraining data and the learned representations remains poorly understood. Traditional supervised learning benefits from gradient-based data attribution tools like influence functions that measure the contribution of an individual data point to model predictions. However, existing definitions of influence rely on labels, making them unsuitable for SSL settings. We address this gap by introducing Influence-SSL, a novel and label-free approach for defining influence functions tailored to SSL. Our method harnesses the stability of learned representations against data augmentations to identify training examples that help explain model predictions. We provide both theoretical foundations and empirical evidence to show the utility of Influence-SSL in analyzing pre-trained SSL models. Our analysis reveals notable differences in how SSL models respond to influential data compared to supervised models. Finally, we validate the effectiveness of Influence-SSL through applications in duplicate detection, outlier identification and fairness analysis. Code is available at: \url{https://github.com/cryptonymous9/Influence-SSL}.
Mixing Natural and Synthetic Images for Robust Self-Supervised Representations
Jun 18, 2024



This paper introduces DiffMix, a new self-supervised learning (SSL) pre-training framework that combines real and synthetic images. Unlike traditional SSL methods that predominantly use real images, DiffMix uses a variant of Stable Diffusion to replace an augmented instance of a real image, facilitating the learning of cross real-synthetic image representations. The key insight is that while SSL methods trained solely on synthetic images underperform compared to those trained on real images, a blended training approach using both real and synthetic images leads to more robust and adaptable representations. Experiments demonstrate that DiffMix enhances the SSL methods SimCLR, BarlowTwins, and DINO, across various robustness datasets and domain transfer tasks. DiffMix boosts SimCLR's accuracy on ImageNet-1K by 4.56\%. These results challenge the notion that high-quality real images are crucial for SSL pre-training by showing that lower quality synthetic images can also produce strong representations. DiffMix also reduces the need for image augmentations in SSL, offering new optimization strategies.
Parameter Efficient Fine-tuning of Self-supervised ViTs without Catastrophic Forgetting
Apr 26, 2024Artificial neural networks often suffer from catastrophic forgetting, where learning new concepts leads to a complete loss of previously acquired knowledge. We observe that this issue is particularly magnified in vision transformers (ViTs), where post-pre-training and fine-tuning on new tasks can significantly degrade the model's original general abilities. For instance, a DINO ViT-Base/16 pre-trained on ImageNet-1k loses over 70% accuracy on ImageNet-1k after just 10 iterations of fine-tuning on CIFAR-100. Overcoming this stability-plasticity dilemma is crucial for enabling ViTs to continuously learn and adapt to new domains while preserving their initial knowledge. In this work, we study two new parameter-efficient fine-tuning strategies: (1)~Block Expansion, and (2) Low-rank adaptation (LoRA). Our experiments reveal that using either Block Expansion or LoRA on self-supervised pre-trained ViTs surpass fully fine-tuned ViTs in new domains while offering significantly greater parameter efficiency. Notably, we find that Block Expansion experiences only a minimal performance drop in the pre-training domain, thereby effectively mitigating catastrophic forgetting in pre-trained ViTs.
STint: Self-supervised Temporal Interpolation for Geospatial Data
Aug 31, 2023



Supervised and unsupervised techniques have demonstrated the potential for temporal interpolation of video data. Nevertheless, most prevailing temporal interpolation techniques hinge on optical flow, which encodes the motion of pixels between video frames. On the other hand, geospatial data exhibits lower temporal resolution while encompassing a spectrum of movements and deformations that challenge several assumptions inherent to optical flow. In this work, we propose an unsupervised temporal interpolation technique, which does not rely on ground truth data or require any motion information like optical flow, thus offering a promising alternative for better generalization across geospatial domains. Specifically, we introduce a self-supervised technique of dual cycle consistency. Our proposed technique incorporates multiple cycle consistency losses, which result from interpolating two frames between consecutive input frames through a series of stages. This dual cycle consistent constraint causes the model to produce intermediate frames in a self-supervised manner. To the best of our knowledge, this is the first attempt at unsupervised temporal interpolation without the explicit use of optical flow. Our experimental evaluations across diverse geospatial datasets show that STint significantly outperforms existing state-of-the-art methods for unsupervised temporal interpolation.
Effectiveness of the Recent Advances in Capsule Networks
Oct 11, 2022


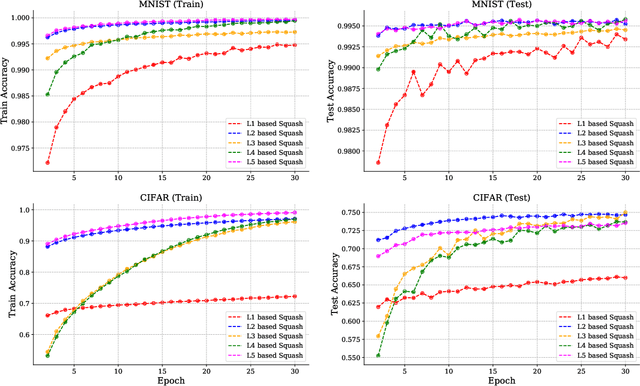
Convolutional neural networks (CNNs) have revolutionized the field of deep neural networks. However, recent research has shown that CNNs fail to generalize under various conditions and hence the idea of capsules was introduced in 2011, though the real surge of research started from 2017. In this paper, we present an overview of the recent advances in capsule architecture and routing mechanisms. In addition, we find that the relative focus in recent literature is on modifying routing procedure or architecture as a whole but the study of other finer components, specifically, squash function is wanting. Thus, we also present some new insights regarding the effect of squash functions in performance of the capsule networks. Finally, we conclude by discussing and proposing possible opportunities in the field of capsule networks.
HDRVideo-GAN: Deep Generative HDR Video Reconstruction
Nov 03, 2021


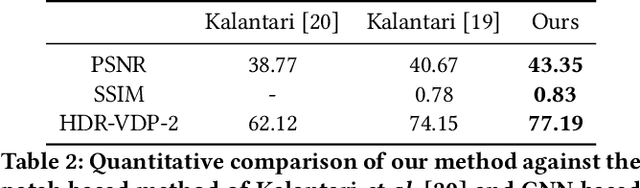
High dynamic range (HDR) videos provide a more visually realistic experience than the standard low dynamic range (LDR) videos. Despite having significant progress in HDR imaging, it is still a challenging task to capture high-quality HDR video with a conventional off-the-shelf camera. Existing approaches rely entirely on using dense optical flow between the neighboring LDR sequences to reconstruct an HDR frame. However, they lead to inconsistencies in color and exposure over time when applied to alternating exposures with noisy frames. In this paper, we propose an end-to-end GAN-based framework for HDR video reconstruction from LDR sequences with alternating exposures. We first extract clean LDR frames from noisy LDR video with alternating exposures with a denoising network trained in a self-supervised setting. Using optical flow, we then align the neighboring alternating-exposure frames to a reference frame and then reconstruct high-quality HDR frames in a complete adversarial setting. To further improve the robustness and quality of generated frames, we incorporate temporal stability-based regularization term along with content and style-based losses in the cost function during the training procedure. Experimental results demonstrate that our framework achieves state-of-the-art performance and generates superior quality HDR frames of a video over the existing methods.
Bayesian Deep Learning Hyperparameter Search for Robust Function Mapping to Polynomials with Noise
Jun 23, 2021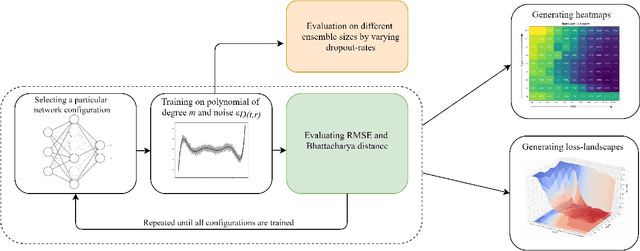
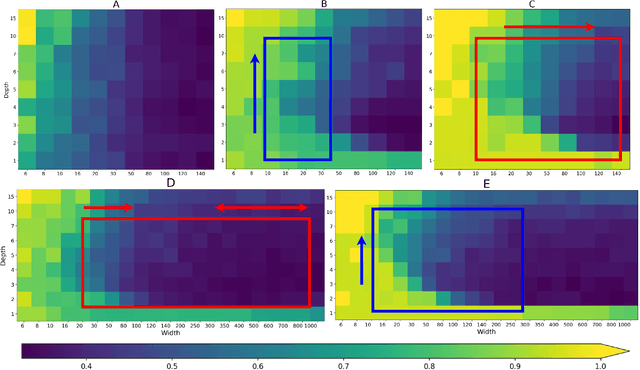
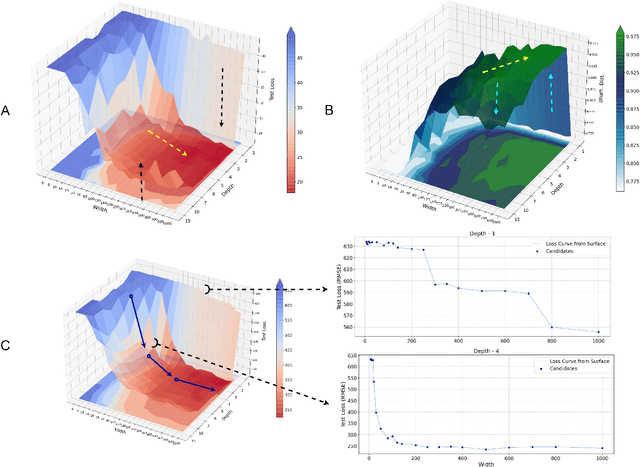
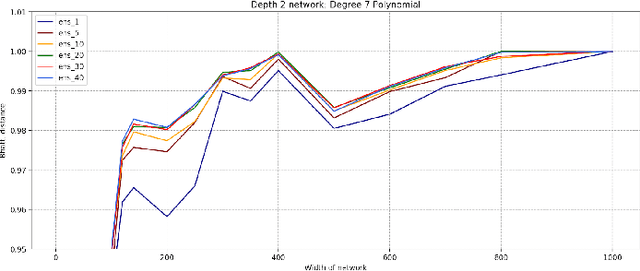
Advances in neural architecture search, as well as explainability and interpretability of connectionist architectures, have been reported in the recent literature. However, our understanding of how to design Bayesian Deep Learning (BDL) hyperparameters, specifically, the depth, width and ensemble size, for robust function mapping with uncertainty quantification, is still emerging. This paper attempts to further our understanding by mapping Bayesian connectionist representations to polynomials of different orders with varying noise types and ratios. We examine the noise-contaminated polynomials to search for the combination of hyperparameters that can extract the underlying polynomial signals while quantifying uncertainties based on the noise attributes. Specifically, we attempt to study the question that an appropriate neural architecture and ensemble configuration can be found to detect a signal of any n-th order polynomial contaminated with noise having different distributions and signal-to-noise (SNR) ratios and varying noise attributes. Our results suggest the possible existence of an optimal network depth as well as an optimal number of ensembles for prediction skills and uncertainty quantification, respectively. However, optimality is not discernible for width, even though the performance gain reduces with increasing width at high values of width. Our experiments and insights can be directional to understand theoretical properties of BDL representations and to design practical solutions.
Augmented Convolutional LSTMs for Generation of High-Resolution Climate Change Projections
Sep 23, 2020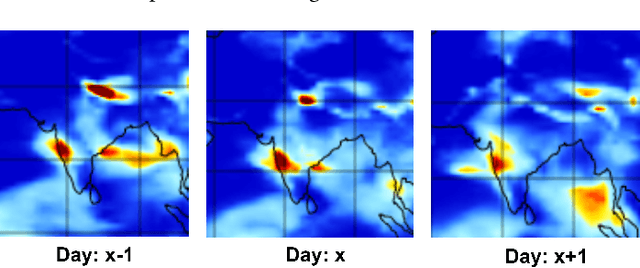
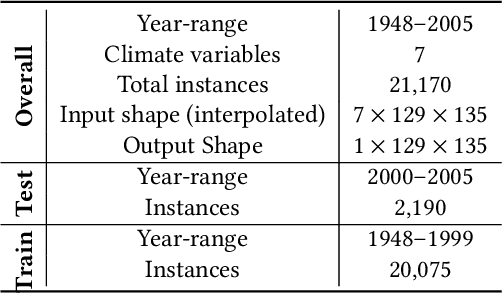
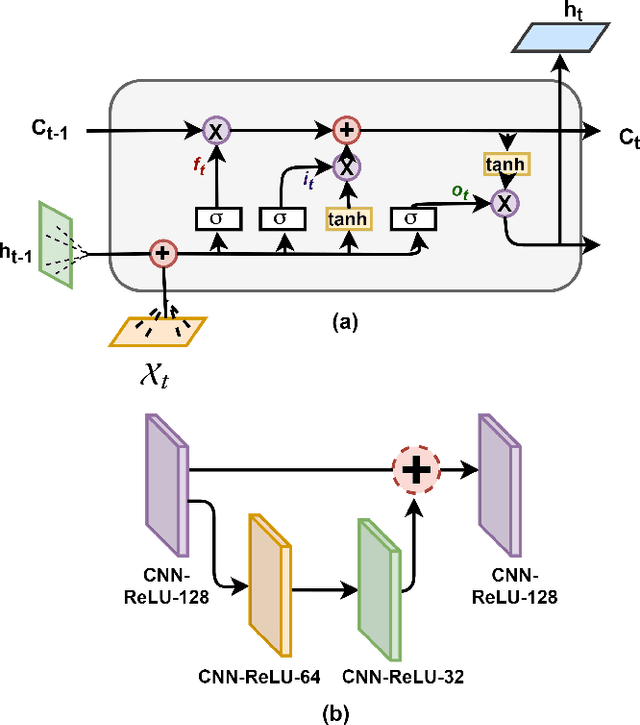
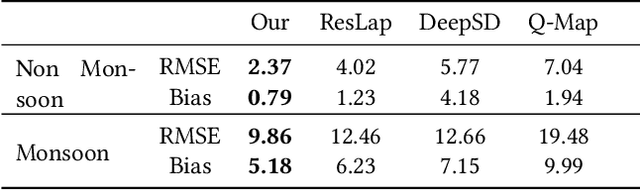
Projection of changes in extreme indices of climate variables such as temperature and precipitation are critical to assess the potential impacts of climate change on human-made and natural systems, including critical infrastructures and ecosystems. While impact assessment and adaptation planning rely on high-resolution projections (typically in the order of a few kilometers), state-of-the-art Earth System Models (ESMs) are available at spatial resolutions of few hundreds of kilometers. Current solutions to obtain high-resolution projections of ESMs include downscaling approaches that consider the information at a coarse-scale to make predictions at local scales. Complex and non-linear interdependence among local climate variables (e.g., temperature and precipitation) and large-scale predictors (e.g., pressure fields) motivate the use of neural network-based super-resolution architectures. In this work, we present auxiliary variables informed spatio-temporal neural architecture for statistical downscaling. The current study performs daily downscaling of precipitation variable from an ESM output at 1.15 degrees (~115 km) to 0.25 degrees (25 km) over the world's most climatically diversified country, India. We showcase significant improvement gain against three popular state-of-the-art baselines with a better ability to predict extreme events. To facilitate reproducible research, we make available all the codes, processed datasets, and trained models in the public domain.