 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParseval Networks: Improving Robustness to Adversarial Examples
May 02, 2017
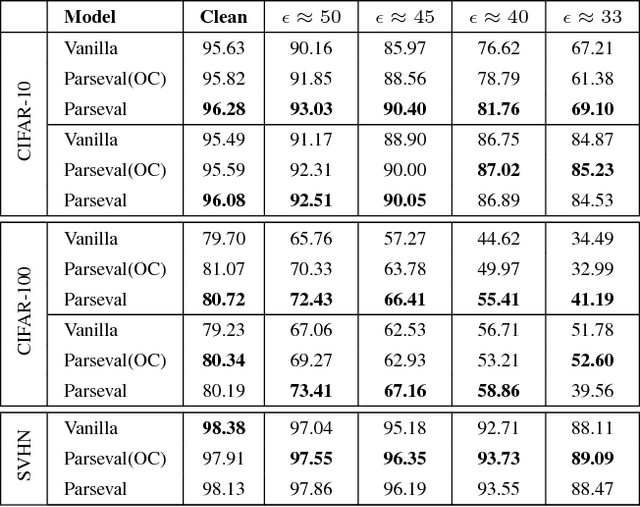
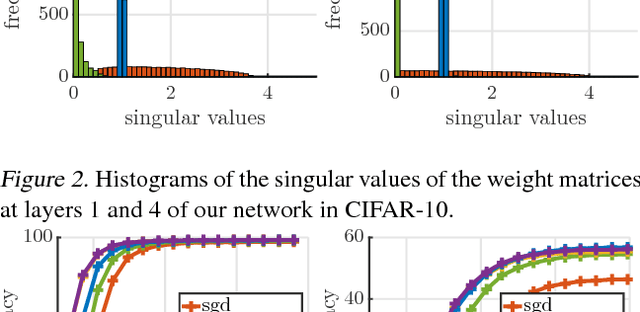
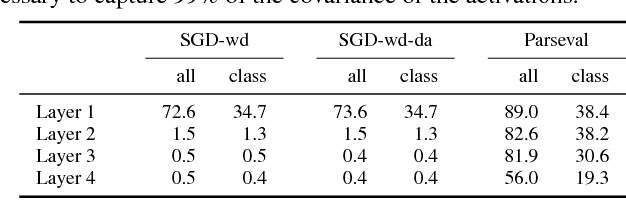
We introduce Parseval networks, a form of deep neural networks in which the Lipschitz constant of linear, convolutional and aggregation layers is constrained to be smaller than 1. Parseval networks are empirically and theoretically motivated by an analysis of the robustness of the predictions made by deep neural networks when their input is subject to an adversarial perturbation. The most important feature of Parseval networks is to maintain weight matrices of linear and convolutional layers to be (approximately) Parseval tight frames, which are extensions of orthogonal matrices to non-square matrices. We describe how these constraints can be maintained efficiently during SGD. We show that Parseval networks match the state-of-the-art in terms of accuracy on CIFAR-10/100 and Street View House Numbers (SVHN) while being more robust than their vanilla counterpart against adversarial examples. Incidentally, Parseval networks also tend to train faster and make a better usage of the full capacity of the networks.
Improving Neural Language Models with a Continuous Cache
Dec 13, 2016

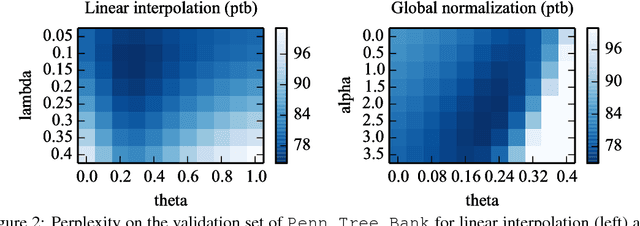

We propose an extension to neural network language models to adapt their prediction to the recent history. Our model is a simplified version of memory augmented networks, which stores past hidden activations as memory and accesses them through a dot product with the current hidden activation. This mechanism is very efficient and scales to very large memory sizes. We also draw a link between the use of external memory in neural network and cache models used with count based language models. We demonstrate on several language model datasets that our approach performs significantly better than recent memory augmented networks.
Episodic Exploration for Deep Deterministic Policies: An Application to StarCraft Micromanagement Tasks
Nov 26, 2016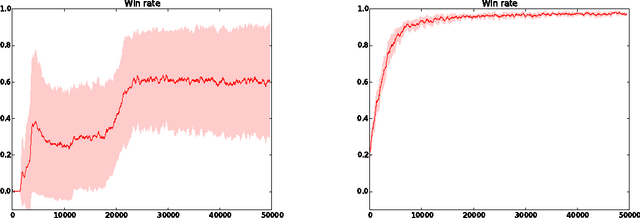
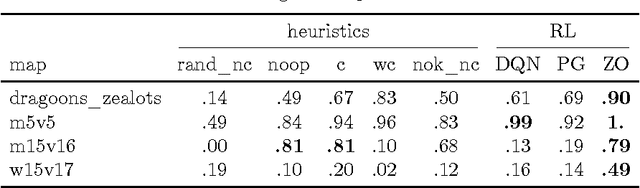

We consider scenarios from the real-time strategy game StarCraft as new benchmarks for reinforcement learning algorithms. We propose micromanagement tasks, which present the problem of the short-term, low-level control of army members during a battle. From a reinforcement learning point of view, these scenarios are challenging because the state-action space is very large, and because there is no obvious feature representation for the state-action evaluation function. We describe our approach to tackle the micromanagement scenarios with deep neural network controllers from raw state features given by the game engine. In addition, we present a heuristic reinforcement learning algorithm which combines direct exploration in the policy space and backpropagation. This algorithm allows for the collection of traces for learning using deterministic policies, which appears much more efficient than, for example, {\epsilon}-greedy exploration. Experiments show that with this algorithm, we successfully learn non-trivial strategies for scenarios with armies of up to 15 agents, where both Q-learning and REINFORCE struggle.
TorchCraft: a Library for Machine Learning Research on Real-Time Strategy Games
Nov 03, 2016
We present TorchCraft, a library that enables deep learning research on Real-Time Strategy (RTS) games such as StarCraft: Brood War, by making it easier to control these games from a machine learning framework, here Torch. This white paper argues for using RTS games as a benchmark for AI research, and describes the design and components of TorchCraft.
Large-scale Simple Question Answering with Memory Networks
Jun 05, 2015
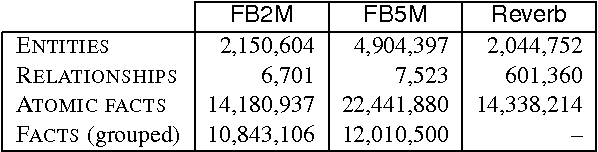

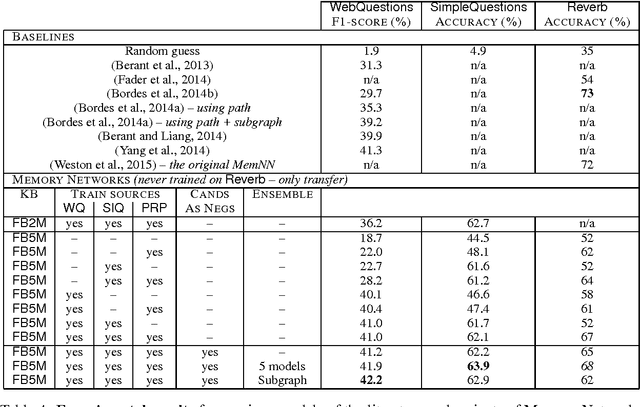
Training large-scale question answering systems is complicated because training sources usually cover a small portion of the range of possible questions. This paper studies the impact of multitask and transfer learning for simple question answering; a setting for which the reasoning required to answer is quite easy, as long as one can retrieve the correct evidence given a question, which can be difficult in large-scale conditions. To this end, we introduce a new dataset of 100k questions that we use in conjunction with existing benchmarks. We conduct our study within the framework of Memory Networks (Weston et al., 2015) because this perspective allows us to eventually scale up to more complex reasoning, and show that Memory Networks can be successfully trained to achieve excellent performance.
Combining Two And Three-Way Embeddings Models for Link Prediction in Knowledge Bases
Jun 02, 2015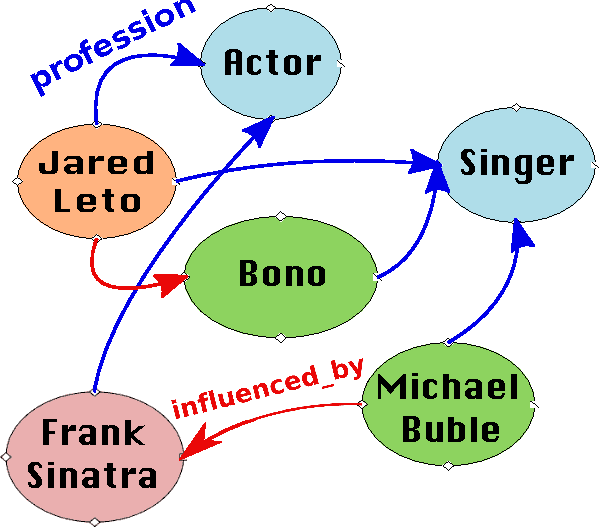
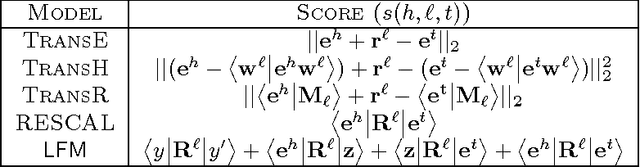

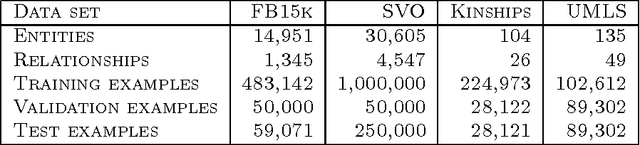
This paper tackles the problem of endogenous link prediction for Knowledge Base completion. Knowledge Bases can be represented as directed graphs whose nodes correspond to entities and edges to relationships. Previous attempts either consist of powerful systems with high capacity to model complex connectivity patterns, which unfortunately usually end up overfitting on rare relationships, or in approaches that trade capacity for simplicity in order to fairly model all relationships, frequent or not. In this paper, we propose Tatec a happy medium obtained by complementing a high-capacity model with a simpler one, both pre-trained separately and then combined. We present several variants of this model with different kinds of regularization and combination strategies and show that this approach outperforms existing methods on different types of relationships by achieving state-of-the-art results on four benchmarks of the literature.
Open Question Answering with Weakly Supervised Embedding Models
Apr 16, 2014
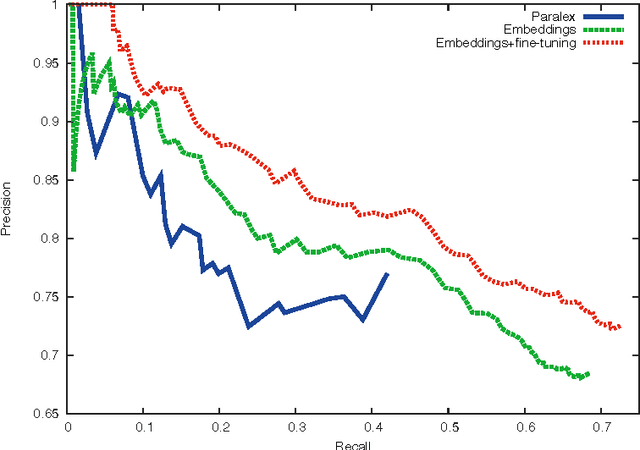

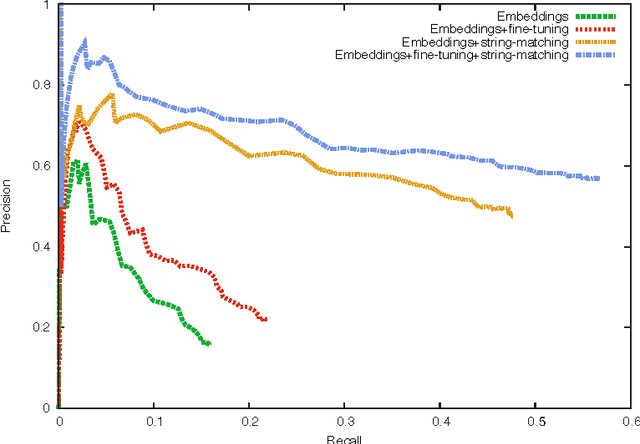
Building computers able to answer questions on any subject is a long standing goal of artificial intelligence. Promising progress has recently been achieved by methods that learn to map questions to logical forms or database queries. Such approaches can be effective but at the cost of either large amounts of human-labeled data or by defining lexicons and grammars tailored by practitioners. In this paper, we instead take the radical approach of learning to map questions to vectorial feature representations. By mapping answers into the same space one can query any knowledge base independent of its schema, without requiring any grammar or lexicon. Our method is trained with a new optimization procedure combining stochastic gradient descent followed by a fine-tuning step using the weak supervision provided by blending automatically and collaboratively generated resources. We empirically demonstrate that our model can capture meaningful signals from its noisy supervision leading to major improvements over paralex, the only existing method able to be trained on similar weakly labeled data.
Connecting Language and Knowledge Bases with Embedding Models for Relation Extraction
Jul 30, 2013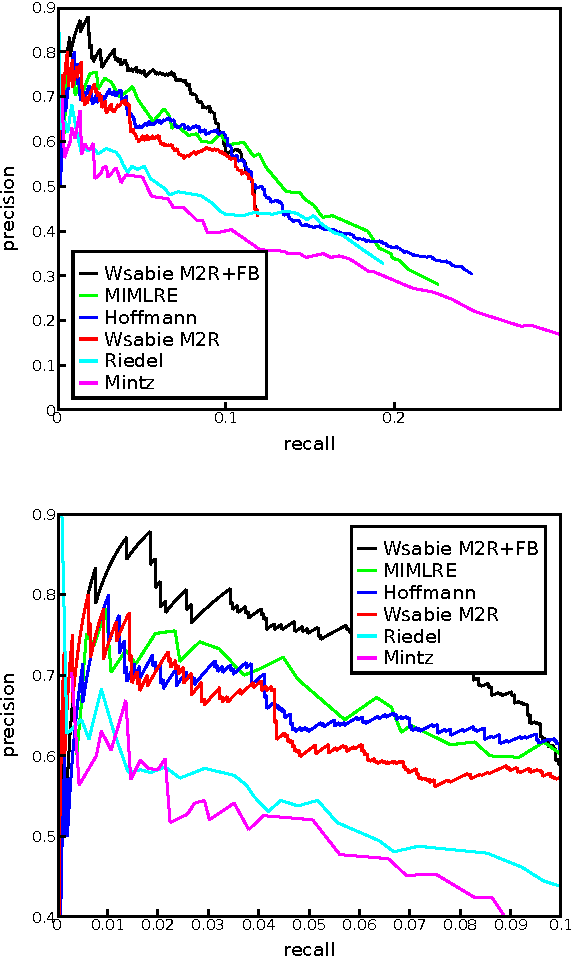
This paper proposes a novel approach for relation extraction from free text which is trained to jointly use information from the text and from existing knowledge. Our model is based on two scoring functions that operate by learning low-dimensional embeddings of words and of entities and relationships from a knowledge base. We empirically show on New York Times articles aligned with Freebase relations that our approach is able to efficiently use the extra information provided by a large subset of Freebase data (4M entities, 23k relationships) to improve over existing methods that rely on text features alone.
Irreflexive and Hierarchical Relations as Translations
Apr 26, 2013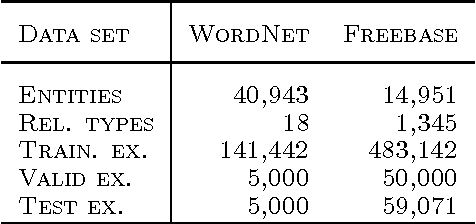
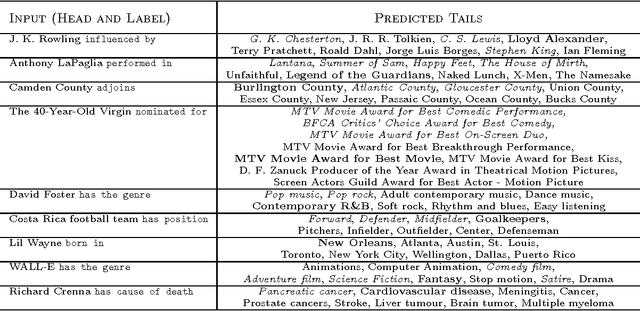
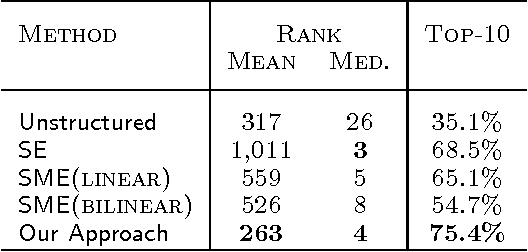
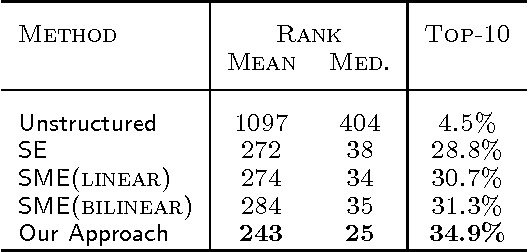
We consider the problem of embedding entities and relations of knowledge bases in low-dimensional vector spaces. Unlike most existing approaches, which are primarily efficient for modeling equivalence relations, our approach is designed to explicitly model irreflexive relations, such as hierarchies, by interpreting them as translations operating on the low-dimensional embeddings of the entities. Preliminary experiments show that, despite its simplicity and a smaller number of parameters than previous approaches, our approach achieves state-of-the-art performance according to standard evaluation protocols on data from WordNet and Freebase.
An Empirical Comparison of V-fold Penalisation and Cross Validation for Model Selection in Distribution-Free Regression
Dec 08, 2012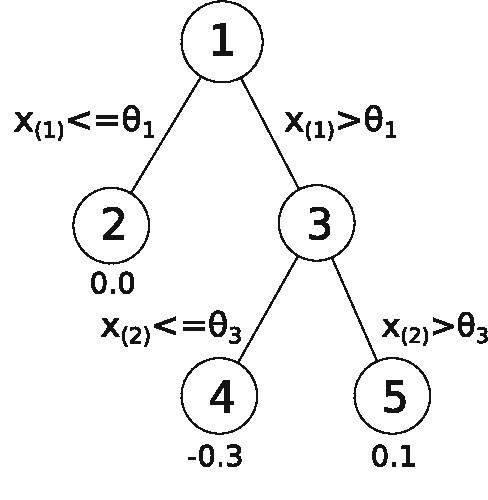
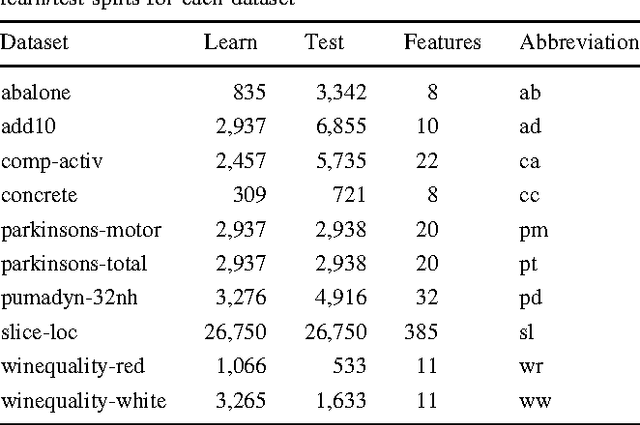
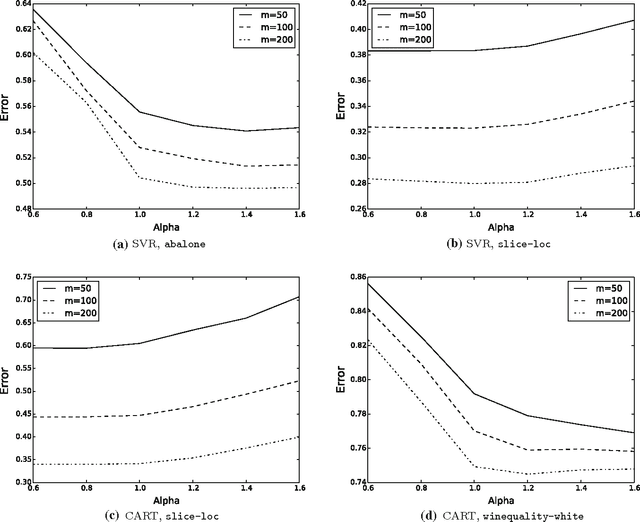
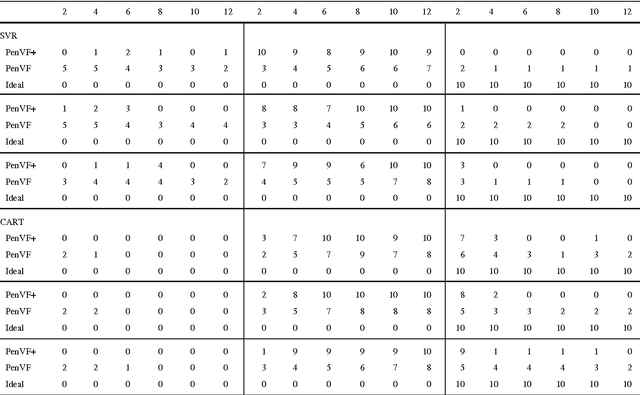
Model selection is a crucial issue in machine-learning and a wide variety of penalisation methods (with possibly data dependent complexity penalties) have recently been introduced for this purpose. However their empirical performance is generally not well documented in the literature. It is the goal of this paper to investigate to which extent such recent techniques can be successfully used for the tuning of both the regularisation and kernel parameters in support vector regression (SVR) and the complexity measure in regression trees (CART). This task is traditionally solved via V-fold cross-validation (VFCV), which gives efficient results for a reasonable computational cost. A disadvantage however of VFCV is that the procedure is known to provide an asymptotically suboptimal risk estimate as the number of examples tends to infinity. Recently, a penalisation procedure called V-fold penalisation has been proposed to improve on VFCV, supported by theoretical arguments. Here we report on an extensive set of experiments comparing V-fold penalisation and VFCV for SVR/CART calibration on several benchmark datasets. We highlight cases in which VFCV and V-fold penalisation provide poor estimates of the risk respectively and introduce a modified penalisation technique to reduce the estimation error.