 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitectural Backdoors for Within-Batch Data Stealing and Model Inference Manipulation
May 23, 2025



For nearly a decade the academic community has investigated backdoors in neural networks, primarily focusing on classification tasks where adversaries manipulate the model prediction. While demonstrably malicious, the immediate real-world impact of such prediction-altering attacks has remained unclear. In this paper we introduce a novel and significantly more potent class of backdoors that builds upon recent advancements in architectural backdoors. We demonstrate how these backdoors can be specifically engineered to exploit batched inference, a common technique for hardware utilization, enabling large-scale user data manipulation and theft. By targeting the batching process, these architectural backdoors facilitate information leakage between concurrent user requests and allow attackers to fully control model responses directed at other users within the same batch. In other words, an attacker who can change the model architecture can set and steal model inputs and outputs of other users within the same batch. We show that such attacks are not only feasible but also alarmingly effective, can be readily injected into prevalent model architectures, and represent a truly malicious threat to user privacy and system integrity. Critically, to counteract this new class of vulnerabilities, we propose a deterministic mitigation strategy that provides formal guarantees against this new attack vector, unlike prior work that relied on Large Language Models to find the backdoors. Our mitigation strategy employs a novel Information Flow Control mechanism that analyzes the model graph and proves non-interference between different user inputs within the same batch. Using our mitigation strategy we perform a large scale analysis of models hosted through Hugging Face and find over 200 models that introduce (unintended) information leakage between batch entries due to the use of dynamic quantization.
RoFL: Attestable Robustness for Secure Federated Learning
Jul 19, 2021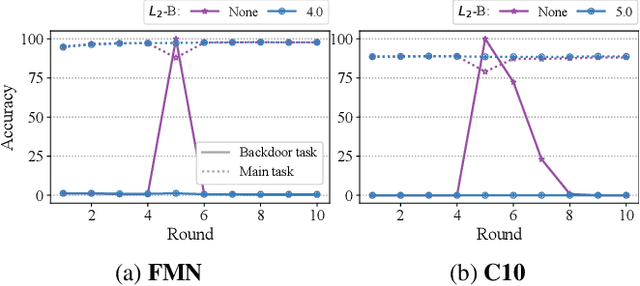
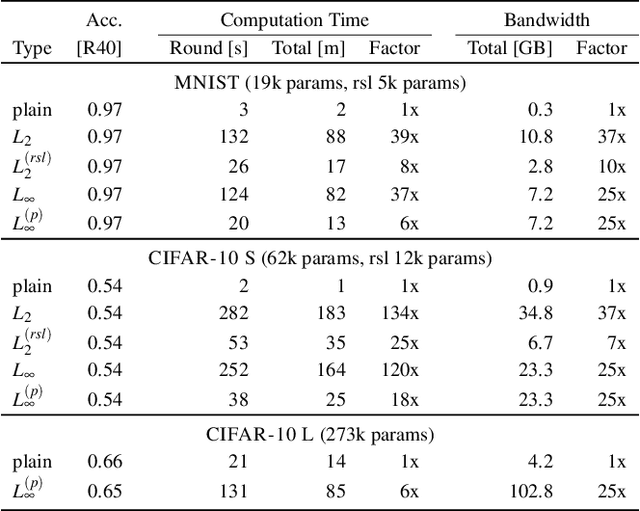
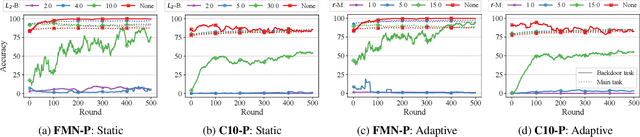
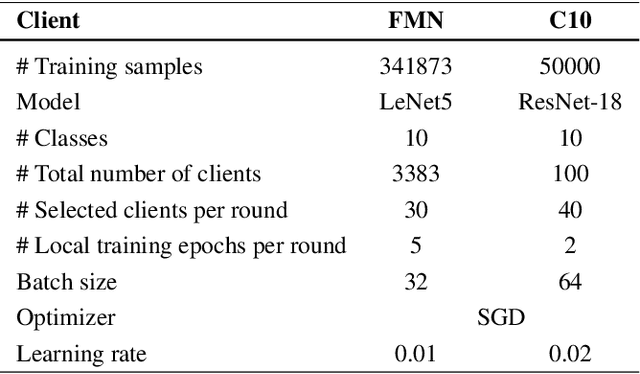
Federated Learning is an emerging decentralized machine learning paradigm that allows a large number of clients to train a joint model without the need to share their private data. Participants instead only share ephemeral updates necessary to train the model. To ensure the confidentiality of the client updates, Federated Learning systems employ secure aggregation; clients encrypt their gradient updates, and only the aggregated model is revealed to the server. Achieving this level of data protection, however, presents new challenges to the robustness of Federated Learning, i.e., the ability to tolerate failures and attacks. Unfortunately, in this setting, a malicious client can now easily exert influence on the model behavior without being detected. As Federated Learning is being deployed in practice in a range of sensitive applications, its robustness is growing in importance. In this paper, we take a step towards understanding and improving the robustness of secure Federated Learning. We start this paper with a systematic study that evaluates and analyzes existing attack vectors and discusses potential defenses and assesses their effectiveness. We then present RoFL, a secure Federated Learning system that improves robustness against malicious clients through input checks on the encrypted model updates. RoFL extends Federated Learning's secure aggregation protocol to allow expressing a variety of properties and constraints on model updates using zero-knowledge proofs. To enable RoFL to scale to typical Federated Learning settings, we introduce several ML and cryptographic optimizations specific to Federated Learning. We implement and evaluate a prototype of RoFL and show that realistic ML models can be trained in a reasonable time while improving robustness.