 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Characterizations of Local Entropy and Heat Regularization in Deep Learning
Jan 29, 2019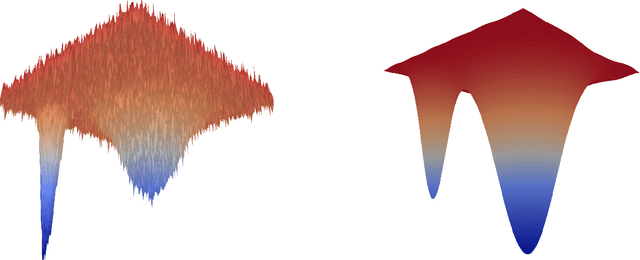
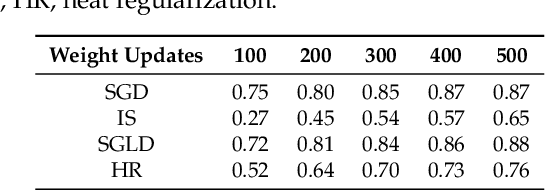
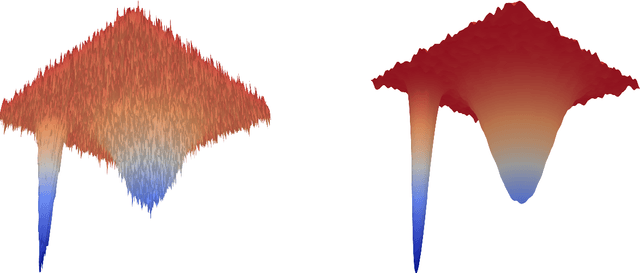
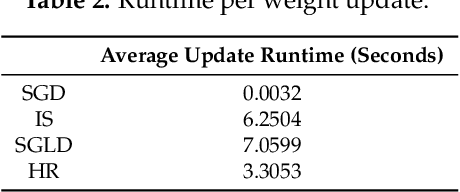
The aim of this paper is to provide new theoretical and computational understanding on two loss regularizations employed in deep learning, known as local entropy and heat regularization. For both regularized losses we introduce variational characterizations that naturally suggest a two-step scheme for their optimization, based on the iterative shift of a probability density and the calculation of a best Gaussian approximation in Kullback-Leibler divergence. Under this unified light, the optimization schemes for local entropy and heat regularized loss differ only over which argument of the Kullback-Leibler divergence is used to find the best Gaussian approximation. Local entropy corresponds to minimizing over the second argument, and the solution is given by moment matching. This allows to replace traditional back-propagation calculation of gradients by sampling algorithms, opening an avenue for gradient-free, parallelizable training of neural networks.
Variational limits of k-NN graph based functionals on data clouds
May 21, 2018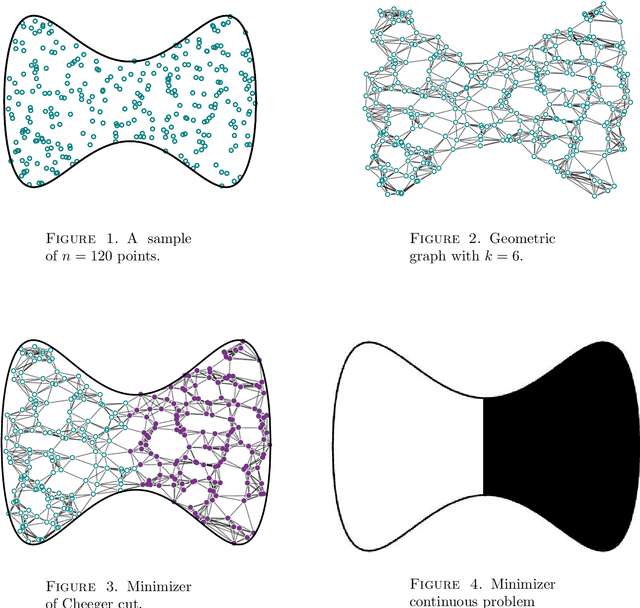

This paper studies the large sample asymptotics of data analysis procedures based on the optimization of functionals defined on $k$-NN graphs on point clouds. The paper is framed in the context of minimization of balanced cut functionals, but our techniques, ideas and results can be adapted to other functionals of relevance. We rigorously show that provided the number of neighbors in the graph $k:=k_n$ scales with the number of points in the cloud as $n \gg k_n \gg \log(n)$, then with probability one, the solution to the graph cut optimization problem converges towards the solution of an analogue variational problem at the continuum level.
Error estimates for spectral convergence of the graph Laplacian on random geometric graphs towards the Laplace--Beltrami operator
Jan 30, 2018We study the convergence of the graph Laplacian of a random geometric graph generated by an i.i.d. sample from a $m$-dimensional submanifold $M$ in $R^d$ as the sample size $n$ increases and the neighborhood size $h$ tends to zero. We show that eigenvalues and eigenvectors of the graph Laplacian converge with a rate of $O\Big(\big(\frac{\log n}{n}\big)^\frac{1}{2m}\Big)$ to the eigenvalues and eigenfunctions of the weighted Laplace-Beltrami operator of $M$. No information on the submanifold $M$ is needed in the construction of the graph or the "out-of-sample extension" of the eigenvectors. Of independent interest is a generalization of the rate of convergence of empirical measures on submanifolds in $R^d$ in infinity transportation distance.
On the Consistency of Graph-based Bayesian Learning and the Scalability of Sampling Algorithms
Oct 20, 2017

A popular approach to semi-supervised learning proceeds by endowing the input data with a graph structure in order to extract geometric information and incorporate it into a Bayesian framework. We introduce new theory that gives appropriate scalings of graph parameters that provably lead to a well-defined limiting posterior as the size of the unlabeled data set grows. Furthermore, we show that these consistency results have profound algorithmic implications. When consistency holds, carefully designed graph-based Markov chain Monte Carlo algorithms are proved to have a uniform spectral gap, independent of the number of unlabeled inputs. Several numerical experiments corroborate both the statistical consistency and the algorithmic scalability established by the theory.
Continuum Limit of Posteriors in Graph Bayesian Inverse Problems
Jun 22, 2017We consider the problem of recovering a function input of a differential equation formulated on an unknown domain $M$. We assume to have access to a discrete domain $M_n=\{x_1, \dots, x_n\} \subset M$, and to noisy measurements of the output solution at $p\le n$ of those points. We introduce a graph-based Bayesian inverse problem, and show that the graph-posterior measures over functions in $M_n$ converge, in the large $n$ limit, to a posterior over functions in $M$ that solves a Bayesian inverse problem with known domain. The proofs rely on the variational formulation of the Bayesian update, and on a new topology for the study of convergence of measures over functions on point clouds to a measure over functions on the continuum. Our framework, techniques, and results may serve to lay the foundations of robust uncertainty quantification of graph-based tasks in machine learning. The ideas are presented in the concrete setting of recovering the initial condition of the heat equation on an unknown manifold.
Gromov-Hausdorff limit of Wasserstein spaces on point clouds
Apr 13, 2017We consider a point cloud $X_n := \{ x_1, \dots, x_n \}$ uniformly distributed on the flat torus $\mathbb{T}^d : = \mathbb{R}^d / \mathbb{Z}^d $, and construct a geometric graph on the cloud by connecting points that are within distance $\epsilon$ of each other. We let $\mathcal{P}(X_n)$ be the space of probability measures on $X_n$ and endow it with a discrete Wasserstein distance $W_n$ as introduced independently by Maas and Zhou et al. for general finite Markov chains. We show that as long as $\epsilon= \epsilon_n$ decays towards zero slower than an explicit rate depending on the level of uniformity of $X_n$, then the space $(\mathcal{P}(X_n), W_n)$ converges in the Gromov-Hausdorff sense towards the space of probability measures on $\mathbb{T}^d$ endowed with the Wasserstein distance.
A new analytical approach to consistency and overfitting in regularized empirical risk minimization
Jul 01, 2016
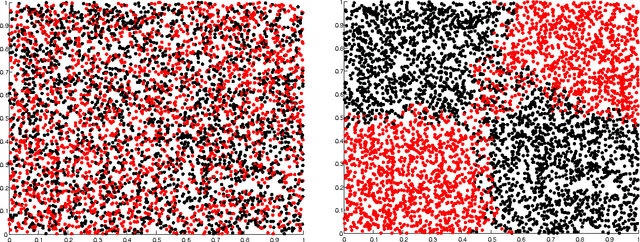
This work considers the problem of binary classification: given training data $x_1, \dots, x_n$ from a certain population, together with associated labels $y_1,\dots, y_n \in \left\{0,1 \right\}$, determine the best label for an element $x$ not among the training data. More specifically, this work considers a variant of the regularized empirical risk functional which is defined intrinsically to the observed data and does not depend on the underlying population. Tools from modern analysis are used to obtain a concise proof of asymptotic consistency as regularization parameters are taken to zero at rates related to the size of the sample. These analytical tools give a new framework for understanding overfitting and underfitting, and rigorously connect the notion of overfitting with a loss of compactness.
Consistency of Cheeger and Ratio Graph Cuts
Nov 24, 2014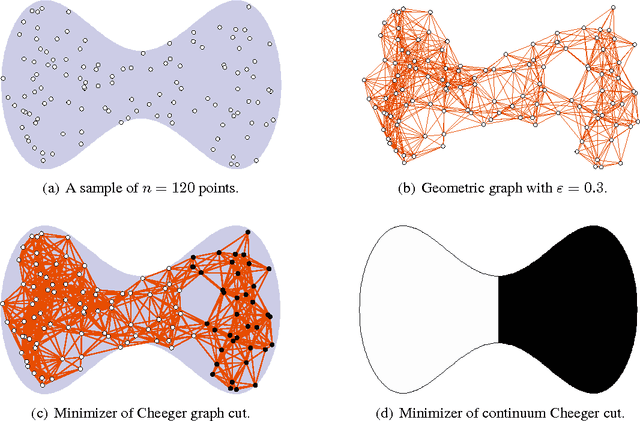
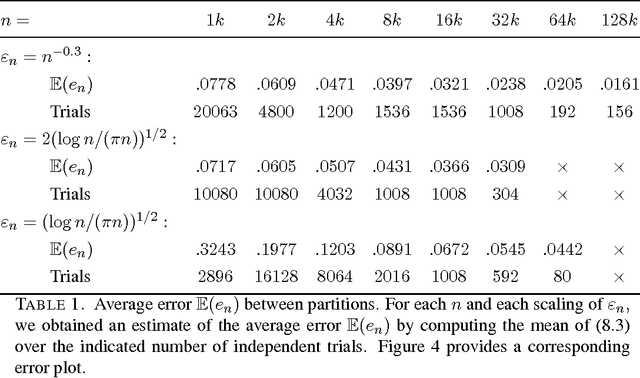
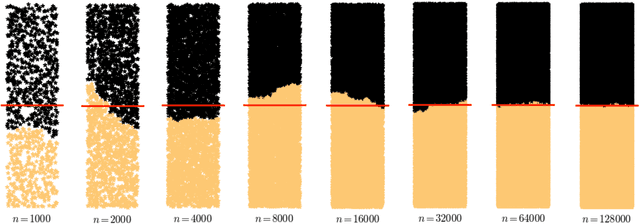
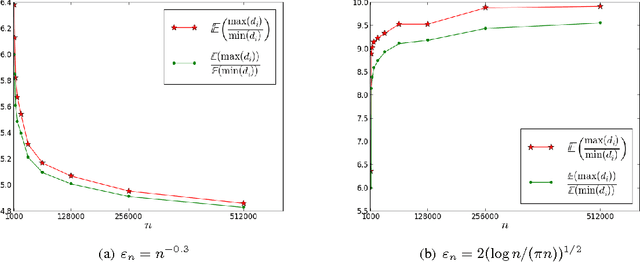
This paper establishes the consistency of a family of graph-cut-based algorithms for clustering of data clouds. We consider point clouds obtained as samples of a ground-truth measure. We investigate approaches to clustering based on minimizing objective functionals defined on proximity graphs of the given sample. Our focus is on functionals based on graph cuts like the Cheeger and ratio cuts. We show that minimizers of the these cuts converge as the sample size increases to a minimizer of a corresponding continuum cut (which partitions the ground truth measure). Moreover, we obtain sharp conditions on how the connectivity radius can be scaled with respect to the number of sample points for the consistency to hold. We provide results for two-way and for multiway cuts. Furthermore we provide numerical experiments that illustrate the results and explore the optimality of scaling in dimension two.