 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Federated Learning on Distributed Remote Sensing Archives
Apr 13, 2026Remote sensing archives are inherently distributed: Earth observation missions such as Sentinel-1, Sentinel-2, and Sentinel-3 have collectively accumulated more than 5 petabytes of imagery, stored and processed across many geographically dispersed platforms. Training machine learning models on such data in a centralized fashion is impractical due to data volume, sovereignty constraints, and geographic distribution. Federated learning (FL) addresses this by keeping data local and exchanging only model updates. A central challenge for remote sensing is the non-IID nature of Earth observation data: label distributions vary strongly by geographic region, degrading the convergence of standard FL algorithms. In this paper, we conduct a systematic empirical study of three FL strategies -- FedAvg, FedProx, and bulk synchronous parallel (BSP) -- applied to multi-label remote sensing image classification under controlled non-IID label-skew conditions. We evaluate three convolutional neural network (CNN) architectures of increasing depth (LeNet, AlexNet, and ResNet-34) and analyze the joint effect of algorithm choice, model capacity, client fraction, client count, batch size, and communication cost. Experiments on the UC Merced multi-label dataset show that FedProx outperforms FedAvg for deeper architectures under data heterogeneity, that BSP approaches centralized accuracy at the cost of high sequential communication, and that LeNet provides the best accuracy-communication trade-off for the dataset scale considered.
How Vulnerable Are Automatic Fake News Detection Methods to Adversarial Attacks?
Jul 16, 2021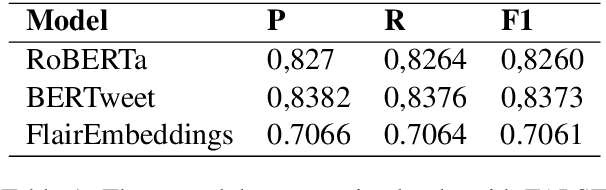
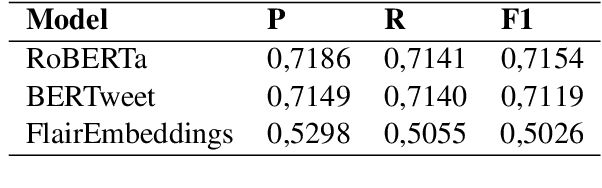
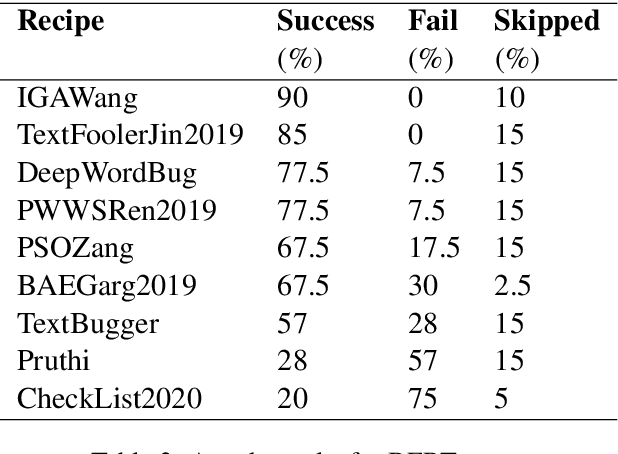
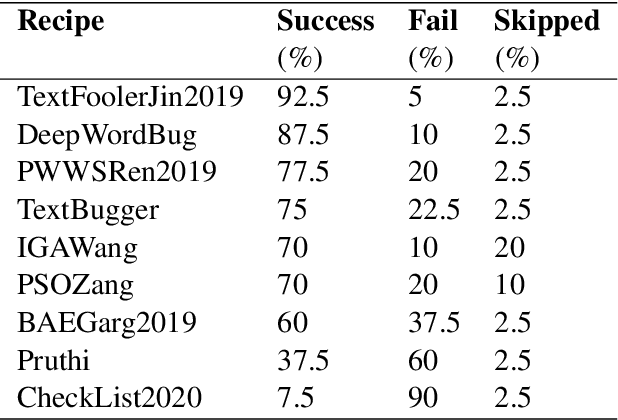
As the spread of false information on the internet has increased dramatically in recent years, more and more attention is being paid to automated fake news detection. Some fake news detection methods are already quite successful. Nevertheless, there are still many vulnerabilities in the detection algorithms. The reason for this is that fake news publishers can structure and formulate their texts in such a way that a detection algorithm does not expose this text as fake news. This paper shows that it is possible to automatically attack state-of-the-art models that have been trained to detect Fake News, making these vulnerable. For this purpose, corresponding models were first trained based on a dataset. Then, using Text-Attack, an attempt was made to manipulate the trained models in such a way that previously correctly identified fake news was classified as true news. The results show that it is possible to automatically bypass Fake News detection mechanisms, leading to implications concerning existing policy initiatives.