 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Constraints to Feature Importances
Oct 13, 2021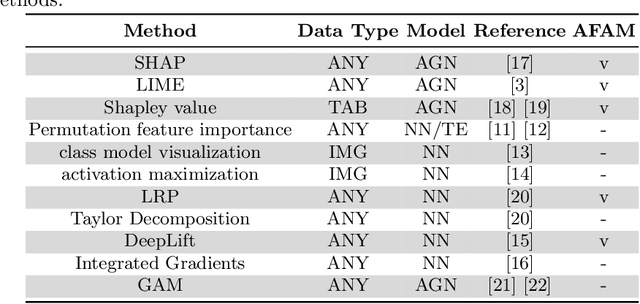
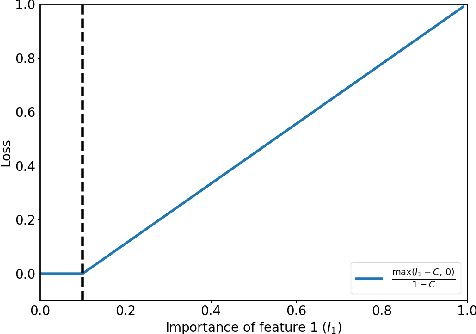

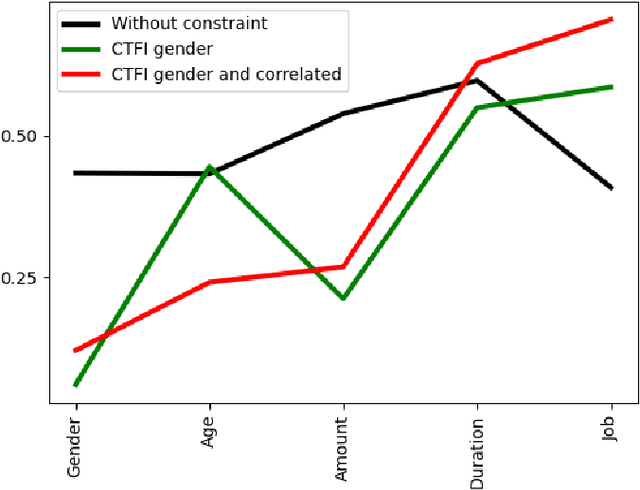
In recent years, Artificial Intelligence (AI) algorithms have been proven to outperform traditional statistical methods in terms of predictivity, especially when a large amount of data was available. Nevertheless, the "black box" nature of AI models is often a limit for a reliable application in high-stakes fields like diagnostic techniques, autonomous guide, etc. Recent works have shown that an adequate level of interpretability could enforce the more general concept of model trustworthiness. The basic idea of this paper is to exploit the human prior knowledge of the features' importance for a specific task, in order to coherently aid the phase of the model's fitting. This sort of "weighted" AI is obtained by extending the empirical loss with a regularization term encouraging the importance of the features to follow predetermined constraints. This procedure relies on local methods for the feature importance computation, e.g. LRP, LIME, etc. that are the link between the model weights to be optimized and the user-defined constraints on feature importance. In the fairness area, promising experimental results have been obtained for the Adult dataset. Many other possible applications of this model agnostic theoretical framework are described.
Clustering-Based Interpretation of Deep ReLU Network
Oct 13, 2021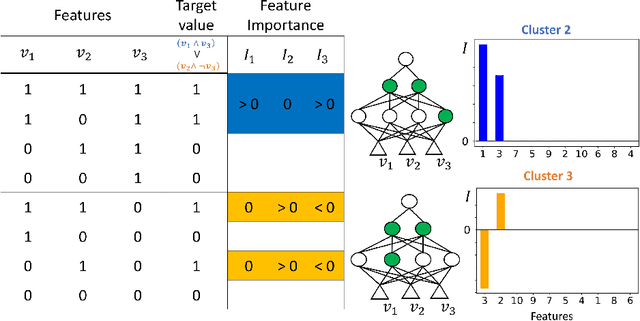

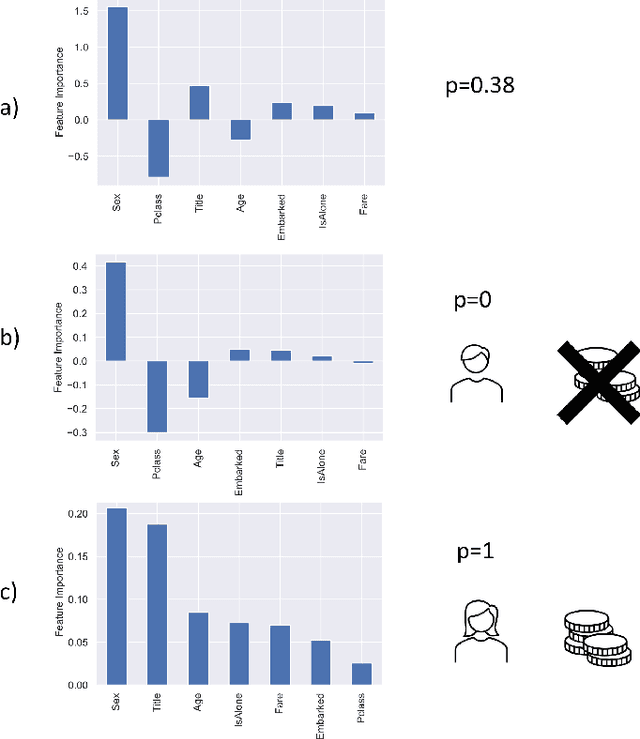
Amongst others, the adoption of Rectified Linear Units (ReLUs) is regarded as one of the ingredients of the success of deep learning. ReLU activation has been shown to mitigate the vanishing gradient issue, to encourage sparsity in the learned parameters, and to allow for efficient backpropagation. In this paper, we recognize that the non-linear behavior of the ReLU function gives rise to a natural clustering when the pattern of active neurons is considered. This observation helps to deepen the learning mechanism of the network; in fact, we demonstrate that, within each cluster, the network can be fully represented as an affine map. The consequence is that we are able to recover an explanation, in the form of feature importance, for the predictions done by the network to the instances belonging to the cluster. Therefore, the methodology we propose is able to increase the level of interpretability of a fully connected feedforward ReLU neural network, downstream from the fitting phase of the model, without altering the structure of the network. A simulation study and the empirical application to the Titanic dataset, show the capability of the method to bridge the gap between the algorithm optimization and the human understandability of the black box deep ReLU networks.