 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly-Attentive Decoder for Multi-modal Neural Machine Translation
Feb 04, 2017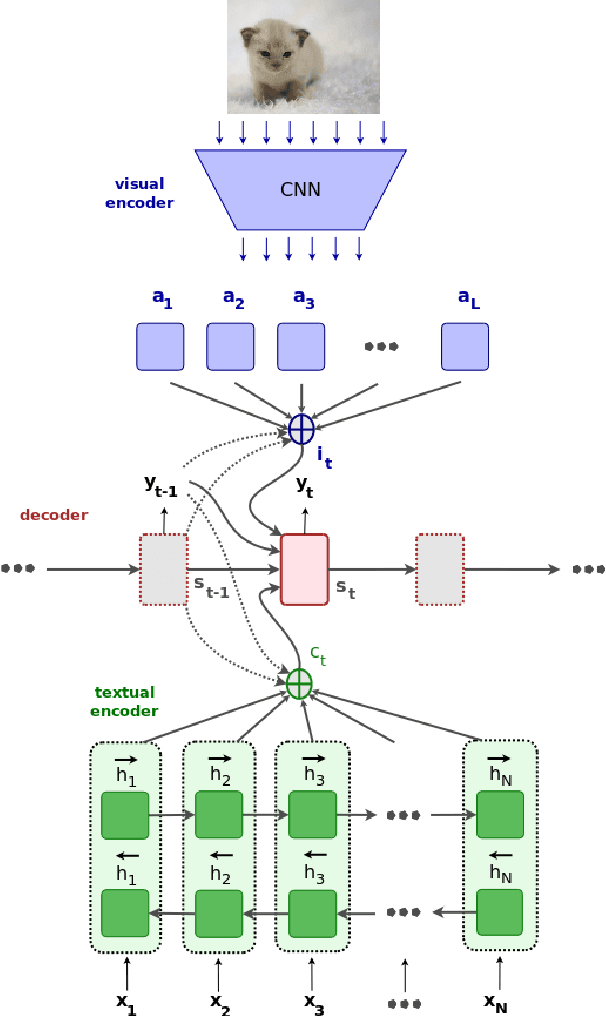
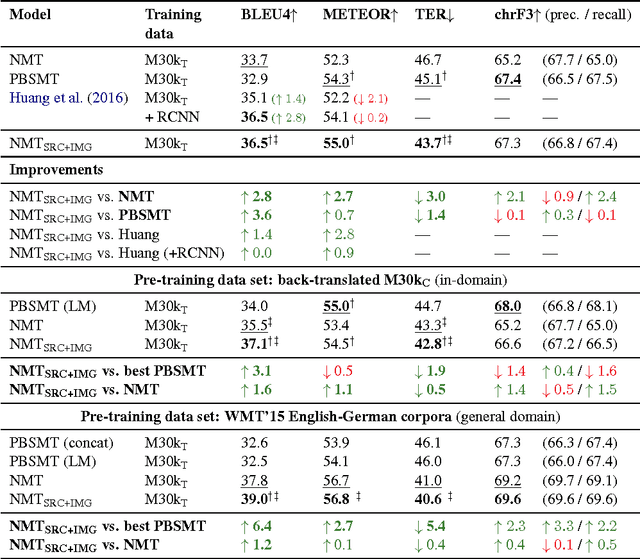
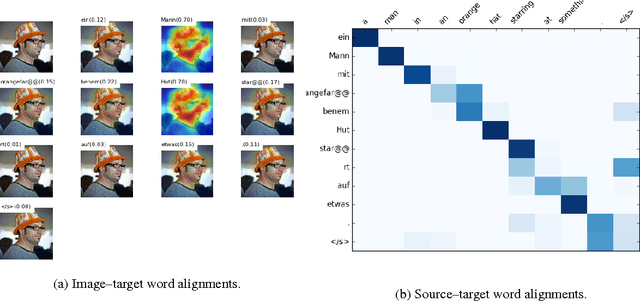
We introduce a Multi-modal Neural Machine Translation model in which a doubly-attentive decoder naturally incorporates spatial visual features obtained using pre-trained convolutional neural networks, bridging the gap between image description and translation. Our decoder learns to attend to source-language words and parts of an image independently by means of two separate attention mechanisms as it generates words in the target language. We find that our model can efficiently exploit not just back-translated in-domain multi-modal data but also large general-domain text-only MT corpora. We also report state-of-the-art results on the Multi30k data set.
Multilingual Multi-modal Embeddings for Natural Language Processing
Feb 03, 2017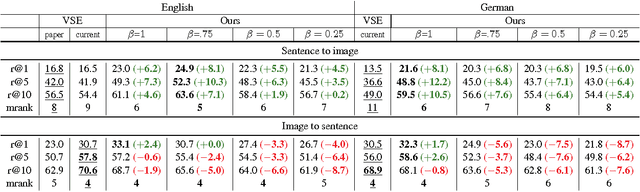

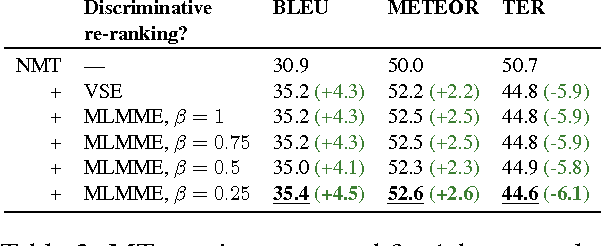
We propose a novel discriminative model that learns embeddings from multilingual and multi-modal data, meaning that our model can take advantage of images and descriptions in multiple languages to improve embedding quality. To that end, we introduce a modification of a pairwise contrastive estimation optimisation function as our training objective. We evaluate our embeddings on an image-sentence ranking (ISR), a semantic textual similarity (STS), and a neural machine translation (NMT) task. We find that the additional multilingual signals lead to improvements on both the ISR and STS tasks, and the discriminative cost can also be used in re-ranking $n$-best lists produced by NMT models, yielding strong improvements.
Incorporating Global Visual Features into Attention-Based Neural Machine Translation
Jan 23, 2017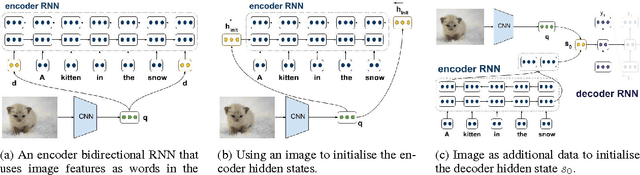
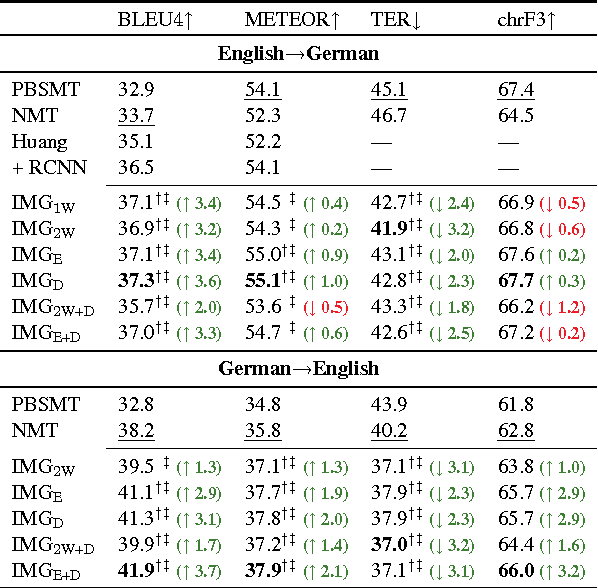
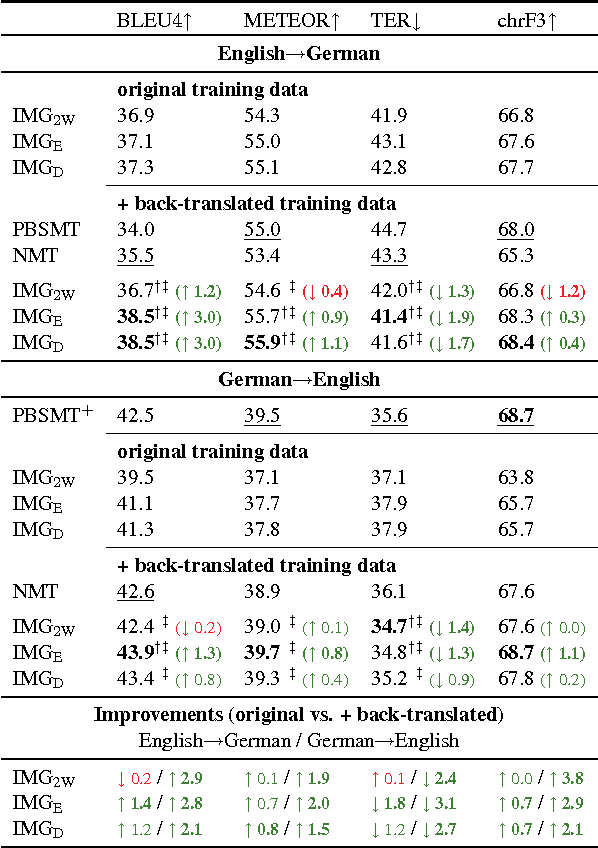

We introduce multi-modal, attention-based neural machine translation (NMT) models which incorporate visual features into different parts of both the encoder and the decoder. We utilise global image features extracted using a pre-trained convolutional neural network and incorporate them (i) as words in the source sentence, (ii) to initialise the encoder hidden state, and (iii) as additional data to initialise the decoder hidden state. In our experiments, we evaluate how these different strategies to incorporate global image features compare and which ones perform best. We also study the impact that adding synthetic multi-modal, multilingual data brings and find that the additional data have a positive impact on multi-modal models. We report new state-of-the-art results and our best models also significantly improve on a comparable phrase-based Statistical MT (PBSMT) model trained on the Multi30k data set according to all metrics evaluated. To the best of our knowledge, it is the first time a purely neural model significantly improves over a PBSMT model on all metrics evaluated on this data set.