 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Neural Network Compression and Pruning Using Hard Clustering and L1 Regularization
Jun 14, 2018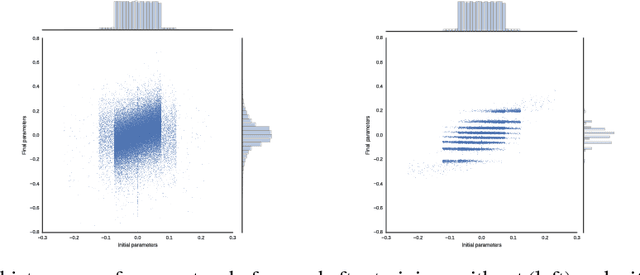
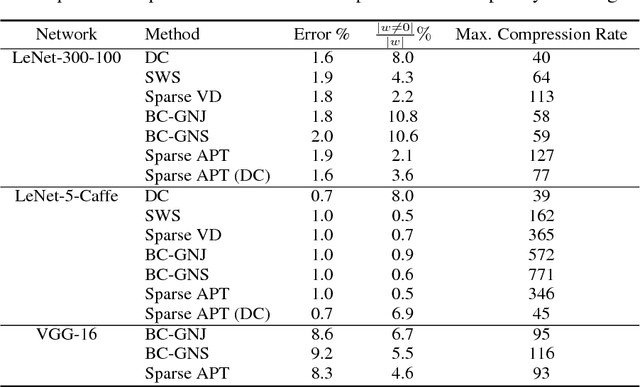
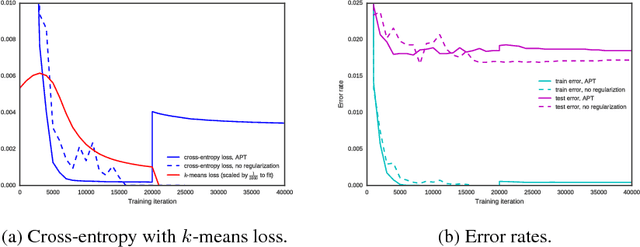
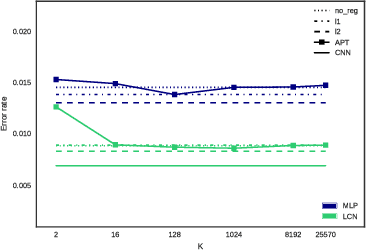
We propose a simple and easy to implement neural network compression algorithm that achieves results competitive with more complicated state-of-the-art methods. The key idea is to modify the original optimization problem by adding K independent Gaussian priors (corresponding to the k-means objective) over the network parameters to achieve parameter quantization, as well as an L1 penalty to achieve pruning. Unlike many existing quantization-based methods, our method uses hard clustering assignments of network parameters, which adds minimal change or overhead to standard network training. We also demonstrate experimentally that tying neural network parameters provides less gain in generalization performance than changing network architecture and connectivity patterns entirely.
Bethe Learning of Conditional Random Fields via MAP Decoding
Mar 04, 2015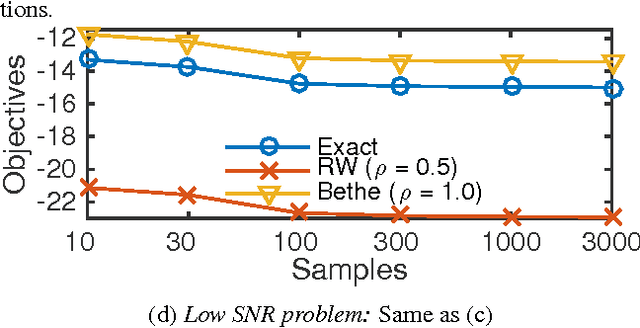

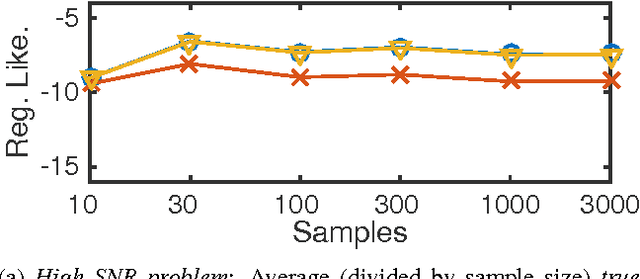
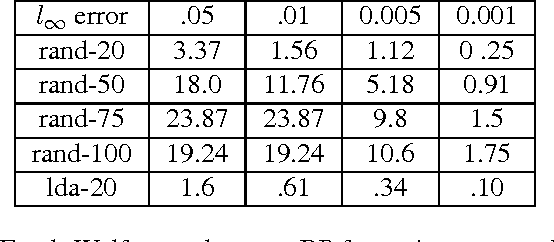
Many machine learning tasks can be formulated in terms of predicting structured outputs. In frameworks such as the structured support vector machine (SVM-Struct) and the structured perceptron, discriminative functions are learned by iteratively applying efficient maximum a posteriori (MAP) decoding. However, maximum likelihood estimation (MLE) of probabilistic models over these same structured spaces requires computing partition functions, which is generally intractable. This paper presents a method for learning discrete exponential family models using the Bethe approximation to the MLE. Remarkably, this problem also reduces to iterative (MAP) decoding. This connection emerges by combining the Bethe approximation with a Frank-Wolfe (FW) algorithm on a convex dual objective which circumvents the intractable partition function. The result is a new single loop algorithm MLE-Struct, which is substantially more efficient than previous double-loop methods for approximate maximum likelihood estimation. Our algorithm outperforms existing methods in experiments involving image segmentation, matching problems from vision, and a new dataset of university roommate assignments.
Message-Passing Algorithms for Quadratic Minimization
Dec 02, 2012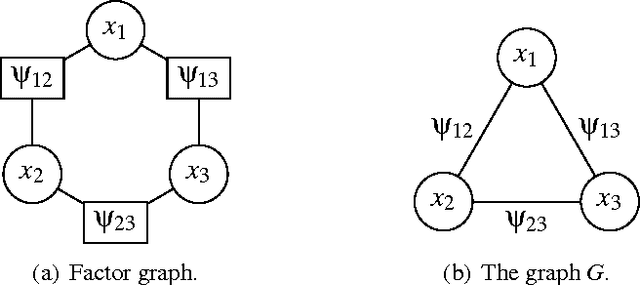
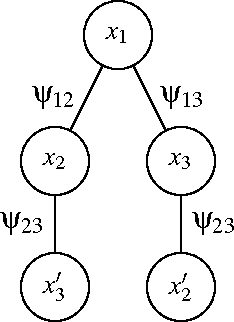
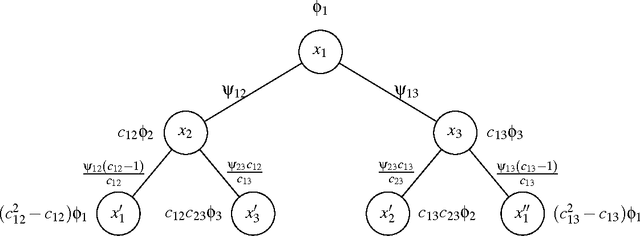
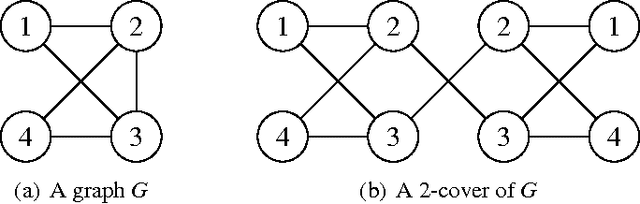
Gaussian belief propagation (GaBP) is an iterative algorithm for computing the mean of a multivariate Gaussian distribution, or equivalently, the minimum of a multivariate positive definite quadratic function. Sufficient conditions, such as walk-summability, that guarantee the convergence and correctness of GaBP are known, but GaBP may fail to converge to the correct solution given an arbitrary positive definite quadratic function. As was observed in previous work, the GaBP algorithm fails to converge if the computation trees produced by the algorithm are not positive definite. In this work, we will show that the failure modes of the GaBP algorithm can be understood via graph covers, and we prove that a parameterized generalization of the min-sum algorithm can be used to ensure that the computation trees remain positive definite whenever the input matrix is positive definite. We demonstrate that the resulting algorithm is closely related to other iterative schemes for quadratic minimization such as the Gauss-Seidel and Jacobi algorithms. Finally, we observe, empirically, that there always exists a choice of parameters such that the above generalization of the GaBP algorithm converges.
Message-Passing Algorithms: Reparameterizations and Splittings
Dec 01, 2012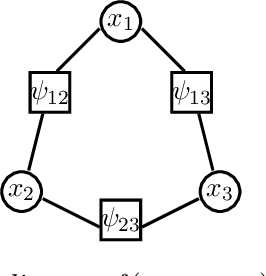
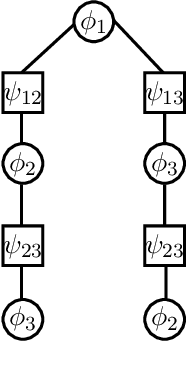
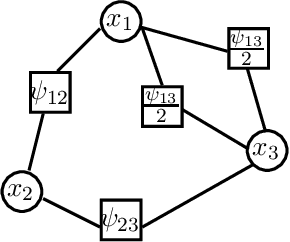
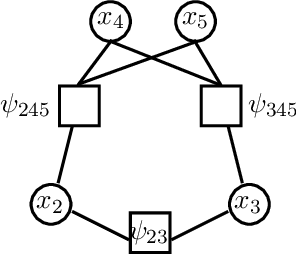
The max-product algorithm, a local message-passing scheme that attempts to compute the most probable assignment (MAP) of a given probability distribution, has been successfully employed as a method of approximate inference for applications arising in coding theory, computer vision, and machine learning. However, the max-product algorithm is not guaranteed to converge to the MAP assignment, and if it does, is not guaranteed to recover the MAP assignment. Alternative convergent message-passing schemes have been proposed to overcome these difficulties. This work provides a systematic study of such message-passing algorithms that extends the known results by exhibiting new sufficient conditions for convergence to local and/or global optima, providing a combinatorial characterization of these optima based on graph covers, and describing a new convergent and correct message-passing algorithm whose derivation unifies many of the known convergent message-passing algorithms. While convergent and correct message-passing algorithms represent a step forward in the analysis of max-product style message-passing algorithms, the conditions needed to guarantee convergence to a global optimum can be too restrictive in both theory and practice. This limitation of convergent and correct message-passing schemes is characterized by graph covers and illustrated by example.
* A complete rework and expansion of the previous versions