 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the effect of Mental Models in User Interaction with an Adaptive Dialog Agent
Aug 26, 2024



Mental models play an important role in whether user interaction with intelligent systems, such as dialog systems is successful or not. Adaptive dialog systems present the opportunity to align a dialog agent's behavior with heterogeneous user expectations. However, there has been little research into what mental models users form when interacting with a task-oriented dialog system, how these models affect users' interactions, or what role system adaptation can play in this process, making it challenging to avoid damage to human-AI partnership. In this work, we collect a new publicly available dataset for exploring user mental models about information seeking dialog systems. We demonstrate that users have a variety of conflicting mental models about such systems, the validity of which directly impacts the success of their interactions and perceived usability of system. Furthermore, we show that adapting a dialog agent's behavior to better align with users' mental models, even when done implicitly, can improve perceived usability, dialog efficiency, and success. To this end, we argue that implicit adaptation can be a valid strategy for task-oriented dialog systems, so long as developers first have a solid understanding of users' mental models.
Explaining Vision-Language Similarities in Dual Encoders with Feature-Pair Attributions
Aug 26, 2024



Dual encoder architectures like CLIP models map two types of inputs into a shared embedding space and learn similarities between them. However, it is not understood how such models compare two inputs. Here, we address this research gap with two contributions. First, we derive a method to attribute predictions of any differentiable dual encoder onto feature-pair interactions between its inputs. Second, we apply our method to CLIP-type models and show that they learn fine-grained correspondences between parts of captions and regions in images. They match objects across input modes and also account for mismatches. However, this visual-linguistic grounding ability heavily varies between object classes, depends on the training data distribution, and largely improves after in-domain training. Using our method we can identify knowledge gaps about specific object classes in individual models and can monitor their improvement upon fine-tuning.
Improving noisy student training for low-resource languages in End-to-End ASR using CycleGAN and inter-domain losses
Jul 26, 2024



Training a semi-supervised end-to-end speech recognition system using noisy student training has significantly improved performance. However, this approach requires a substantial amount of paired speech-text and unlabeled speech, which is costly for low-resource languages. Therefore, this paper considers a more extreme case of semi-supervised end-to-end automatic speech recognition where there are limited paired speech-text, unlabeled speech (less than five hours), and abundant external text. Firstly, we observe improved performance by training the model using our previous work on semi-supervised learning "CycleGAN and inter-domain losses" solely with external text. Secondly, we enhance "CycleGAN and inter-domain losses" by incorporating automatic hyperparameter tuning, calling it "enhanced CycleGAN inter-domain losses." Thirdly, we integrate it into the noisy student training approach pipeline for low-resource scenarios. Our experimental results, conducted on six non-English languages from Voxforge and Common Voice, show a 20% word error rate reduction compared to the baseline teacher model and a 10% word error rate reduction compared to the baseline best student model, highlighting the significant improvements achieved through our proposed method.
Probing the Feasibility of Multilingual Speaker Anonymization
Jul 03, 2024



In speaker anonymization, speech recordings are modified in a way that the identity of the speaker remains hidden. While this technology could help to protect the privacy of individuals around the globe, current research restricts this by focusing almost exclusively on English data. In this study, we extend a state-of-the-art anonymization system to nine languages by transforming language-dependent components to their multilingual counterparts. Experiments testing the robustness of the anonymized speech against privacy attacks and speech deterioration show an overall success of this system for all languages. The results suggest that speaker embeddings trained on English data can be applied across languages, and that the anonymization performance for a language is mainly affected by the quality of the speech synthesis component used for it.
Controlling Emotion in Text-to-Speech with Natural Language Prompts
Jun 11, 2024



In recent years, prompting has quickly become one of the standard ways of steering the outputs of generative machine learning models, due to its intuitive use of natural language. In this work, we propose a system conditioned on embeddings derived from an emotionally rich text that serves as prompt. Thereby, a joint representation of speaker and prompt embeddings is integrated at several points within a transformer-based architecture. Our approach is trained on merged emotional speech and text datasets and varies prompts in each training iteration to increase the generalization capabilities of the model. Objective and subjective evaluation results demonstrate the ability of the conditioned synthesis system to accurately transfer the emotions present in a prompt to speech. At the same time, precise tractability of speaker identities as well as overall high speech quality and intelligibility are maintained.
Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Jun 10, 2024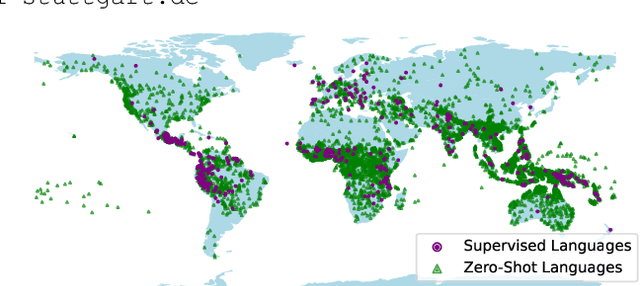
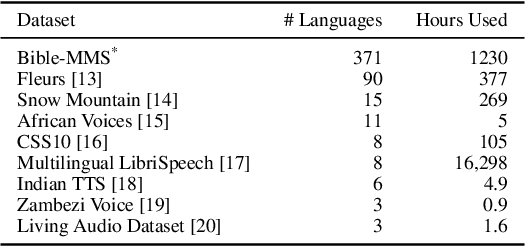
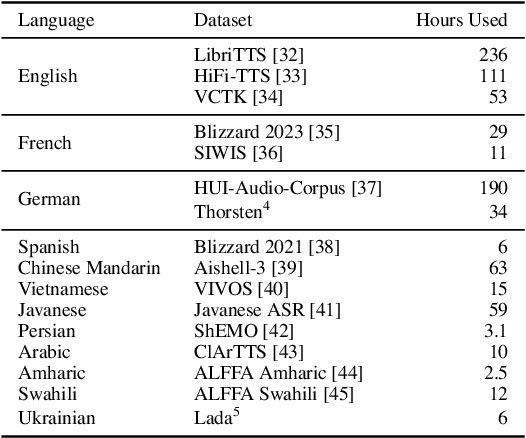
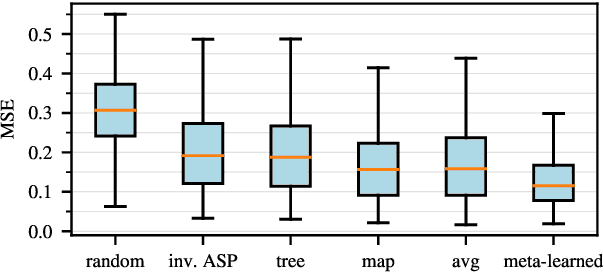
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
Prompting-based Synthetic Data Generation for Few-Shot Question Answering
May 15, 2024Although language models (LMs) have boosted the performance of Question Answering, they still need plenty of data. Data annotation, in contrast, is a time-consuming process. This especially applies to Question Answering, where possibly large documents have to be parsed and annotated with questions and their corresponding answers. Furthermore, Question Answering models often only work well for the domain they were trained on. Since annotation is costly, we argue that domain-agnostic knowledge from LMs, such as linguistic understanding, is sufficient to create a well-curated dataset. With this motivation, we show that using large language models can improve Question Answering performance on various datasets in the few-shot setting compared to state-of-the-art approaches. For this, we perform data generation leveraging the Prompting framework, suggesting that language models contain valuable task-agnostic knowledge that can be used beyond the common pre-training/fine-tuning scheme. As a result, we consistently outperform previous approaches on few-shot Question Answering.
Teaching a Multilingual Large Language Model to Understand Multilingual Speech via Multi-Instructional Training
Apr 16, 2024Recent advancements in language modeling have led to the emergence of Large Language Models (LLMs) capable of various natural language processing tasks. Despite their success in text-based tasks, applying LLMs to the speech domain remains limited and challenging. This paper presents BLOOMZMMS, a novel model that integrates a multilingual LLM with a multilingual speech encoder, aiming to harness the capabilities of LLMs for speech recognition and beyond. Utilizing a multi-instructional training approach, we demonstrate the transferability of linguistic knowledge from the text to the speech modality. Our experiments, conducted on 1900 hours of transcribed data from 139 languages, establish that a multilingual speech representation can be effectively learned and aligned with a multilingual LLM. While this learned representation initially shows limitations in task generalization, we address this issue by generating synthetic targets in a multi-instructional style. Our zero-shot evaluation results confirm the robustness of our approach across multiple tasks, including speech translation and multilingual spoken language understanding, thereby opening new avenues for applying LLMs in the speech domain.
Intrinsic Subgraph Generation for Interpretable Graph based Visual Question Answering
Mar 27, 2024The large success of deep learning based methods in Visual Question Answering (VQA) has concurrently increased the demand for explainable methods. Most methods in Explainable Artificial Intelligence (XAI) focus on generating post-hoc explanations rather than taking an intrinsic approach, the latter characterizing an interpretable model. In this work, we introduce an interpretable approach for graph-based VQA and demonstrate competitive performance on the GQA dataset. This approach bridges the gap between interpretability and performance. Our model is designed to intrinsically produce a subgraph during the question-answering process as its explanation, providing insight into the decision making. To evaluate the quality of these generated subgraphs, we compare them against established post-hoc explainability methods for graph neural networks, and perform a human evaluation. Moreover, we present quantitative metrics that correlate with the evaluations of human assessors, acting as automatic metrics for the generated explanatory subgraphs. Our implementation is available at https://github.com/DigitalPhonetics/Intrinsic-Subgraph-Generation-for-VQA.
Towards a Zero-Data, Controllable, Adaptive Dialog System
Mar 26, 2024Conversational Tree Search (V\"ath et al., 2023) is a recent approach to controllable dialog systems, where domain experts shape the behavior of a Reinforcement Learning agent through a dialog tree. The agent learns to efficiently navigate this tree, while adapting to information needs, e.g., domain familiarity, of different users. However, the need for additional training data hinders deployment in new domains. To address this, we explore approaches to generate this data directly from dialog trees. We improve the original approach, and show that agents trained on synthetic data can achieve comparable dialog success to models trained on human data, both when using a commercial Large Language Model for generation, or when using a smaller open-source model, running on a single GPU. We further demonstrate the scalability of our approach by collecting and testing on two new datasets: ONBOARD, a new domain helping foreign residents moving to a new city, and the medical domain DIAGNOSE, a subset of Wikipedia articles related to scalp and head symptoms. Finally, we perform human testing, where no statistically significant differences were found in either objective or subjective measures between models trained on human and generated data.