 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking gradient weights' influence over saliency map estimation
Jul 12, 2022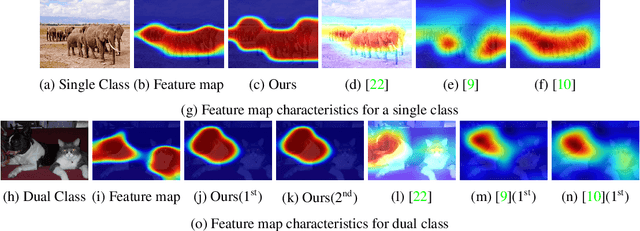

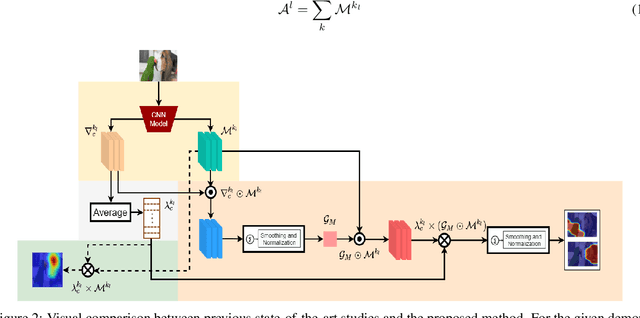

Class activation map (CAM) helps to formulate saliency maps that aid in interpreting the deep neural network's prediction. Gradient-based methods are generally faster than other branches of vision interpretability and independent of human guidance. The performance of CAM-like studies depends on the governing model's layer response, and the influences of the gradients. Typical gradient-oriented CAM studies rely on weighted aggregation for saliency map estimation by projecting the gradient maps into single weight values, which may lead to over generalized saliency map. To address this issue, we use a global guidance map to rectify the weighted aggregation operation during saliency estimation, where resultant interpretations are comparatively clean er and instance-specific. We obtain the global guidance map by performing elementwise multiplication between the feature maps and their corresponding gradient maps. To validate our study, we compare the proposed study with eight different saliency visualizers. In addition, we use seven commonly used evaluation metrics for quantitative comparison. The proposed scheme achieves significant improvement over the test images from the ImageNet, MS-COCO 14, and PASCAL VOC 2012 datasets.
Denoising single images by feature ensemble revisited
Jul 11, 2022
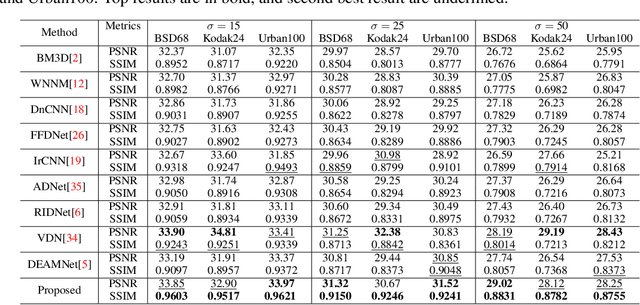
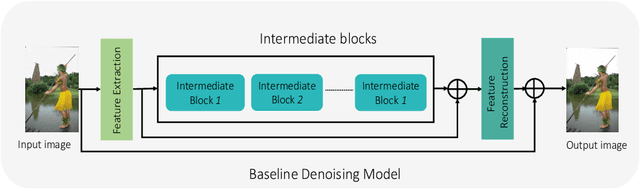

Image denoising is still a challenging issue in many computer vision sub-domains. Recent studies show that significant improvements are made possible in a supervised setting. However, few challenges, such as spatial fidelity and cartoon-like smoothing remain unresolved or decisively overlooked. Our study proposes a simple yet efficient architecture for the denoising problem that addresses the aforementioned issues. The proposed architecture revisits the concept of modular concatenation instead of long and deeper cascaded connections, to recover a cleaner approximation of the given image. We find that different modules can capture versatile representations, and concatenated representation creates a richer subspace for low-level image restoration. The proposed architecture's number of parameters remains smaller than the number for most of the previous networks and still achieves significant improvements over the current state-of-the-art networks.
Semi-supervised atmospheric component learning in low-light image problem
Apr 15, 2022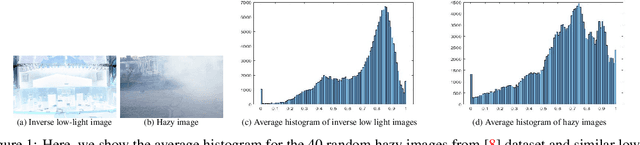
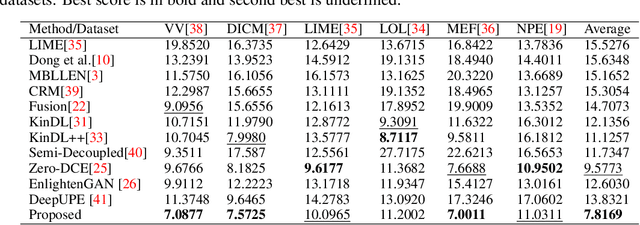

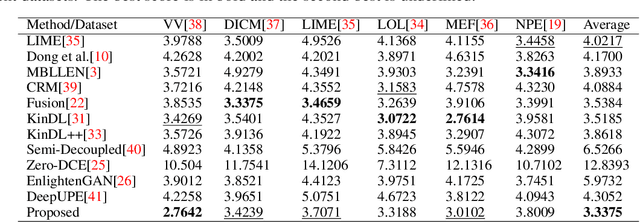
Ambient lighting conditions play a crucial role in determining the perceptual quality of images from photographic devices. In general, inadequate transmission light and undesired atmospheric conditions jointly degrade the image quality. If we know the desired ambient factors associated with the given low-light image, we can recover the enhanced image easily \cite{b1}. Typical deep networks perform enhancement mappings without investigating the light distribution and color formulation properties. This leads to a lack of image instance-adaptive performance in practice. On the other hand, physical model-driven schemes suffer from the need for inherent decompositions and multiple objective minimizations. Moreover, the above approaches are rarely data efficient or free of postprediction tuning. Influenced by the above issues, this study presents a semisupervised training method using no-reference image quality metrics for low-light image restoration. We incorporate the classical haze distribution model \cite{b2} to explore the physical properties of the given image in order to learn the effect of atmospheric components and minimize a single objective for restoration. We validate the performance of our network for six widely used low-light datasets. The experiments show that the proposed study achieves state-of-the-art or comparable performance.