 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuNNE-2022 Shared Task: Recognizing Nested Named Entities
May 23, 2022
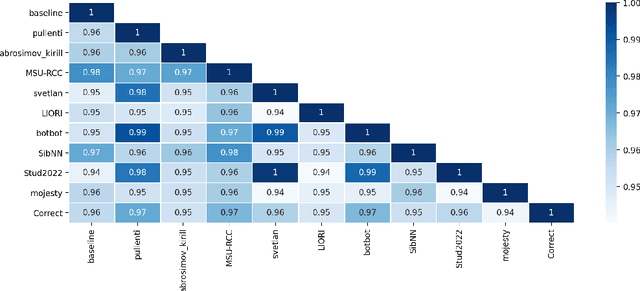
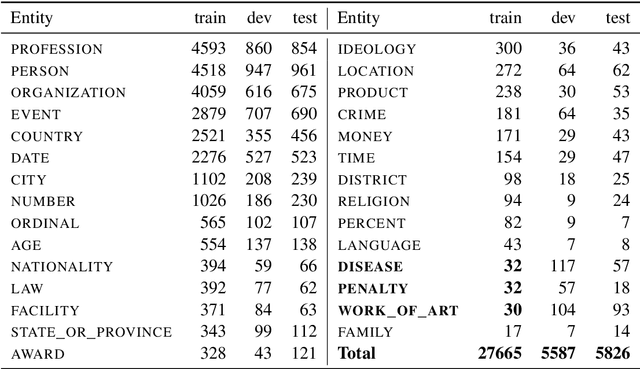
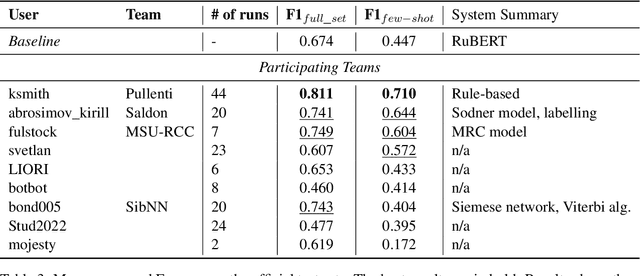
The RuNNE Shared Task approaches the problem of nested named entity recognition. The annotation schema is designed in such a way, that an entity may partially overlap or even be nested into another entity. This way, the named entity "The Yermolova Theatre" of type "organization" houses another entity "Yermolova" of type "person". We adopt the Russian NEREL dataset for the RuNNE Shared Task. NEREL comprises news texts written in the Russian language and collected from the Wikinews portal. The annotation schema includes 29 entity types. The nestedness of named entities in NEREL reaches up to six levels. The RuNNE Shared Task explores two setups. (i) In the general setup all entities occur more or less with the same frequency. (ii) In the few-shot setup the majority of entity types occur often in the training set. However, some of the entity types are have lower frequency, being thus challenging to recognize. In the test set the frequency of all entity types is even. This paper reports on the results of the RuNNE Shared Task. Overall the shared task has received 156 submissions from nine teams. Half of the submissions outperform a straightforward BERT-based baseline in both setups. This paper overviews the shared task setup and discusses the submitted systems, discovering meaning insights for the problem of nested NER. The links to the evaluation platform and the data from the shared task are available in our github repository: https://github.com/dialogue-evaluation/RuNNE.
Taxonomy Enrichment with Text and Graph Vector Representations
Jan 21, 2022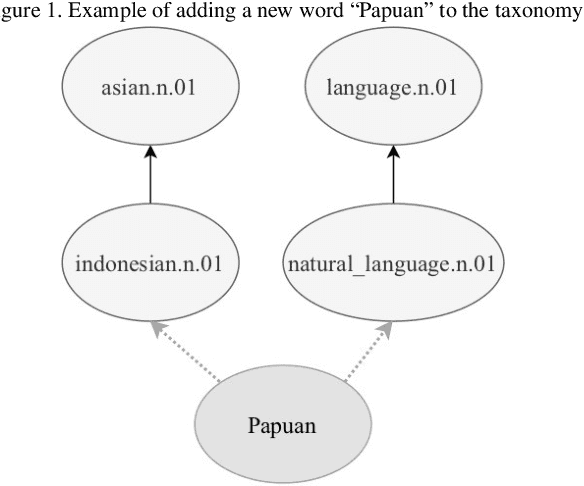
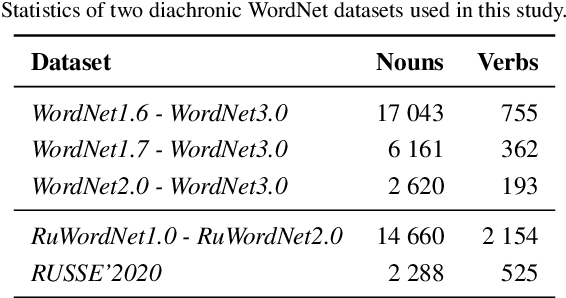
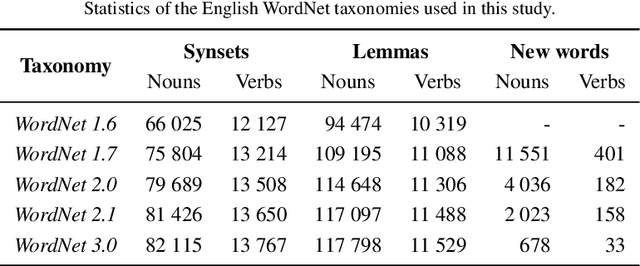
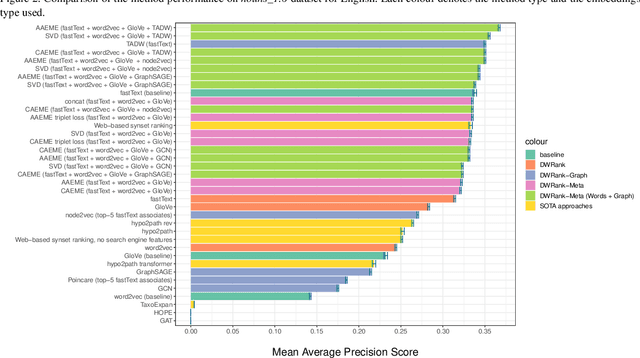
Knowledge graphs such as DBpedia, Freebase or Wikidata always contain a taxonomic backbone that allows the arrangement and structuring of various concepts in accordance with the hypo-hypernym ("class-subclass") relationship. With the rapid growth of lexical resources for specific domains, the problem of automatic extension of the existing knowledge bases with new words is becoming more and more widespread. In this paper, we address the problem of taxonomy enrichment which aims at adding new words to the existing taxonomy. We present a new method that allows achieving high results on this task with little effort. It uses the resources which exist for the majority of languages, making the method universal. We extend our method by incorporating deep representations of graph structures like node2vec, Poincar\'e embeddings, GCN etc. that have recently demonstrated promising results on various NLP tasks. Furthermore, combining these representations with word embeddings allows us to beat the state of the art. We conduct a comprehensive study of the existing approaches to taxonomy enrichment based on word and graph vector representations and their fusion approaches. We also explore the ways of using deep learning architectures to extend the taxonomic backbones of knowledge graphs. We create a number of datasets for taxonomy extension for English and Russian. We achieve state-of-the-art results across different datasets and provide an in-depth error analysis of mistakes.
NEREL: A Russian Dataset with Nested Named Entities, Relations and Events
Sep 03, 2021
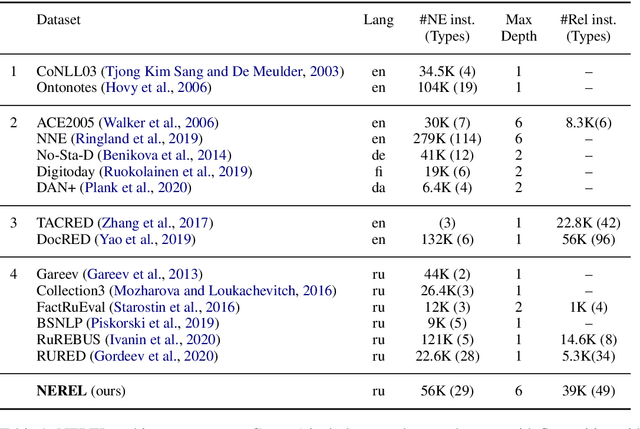
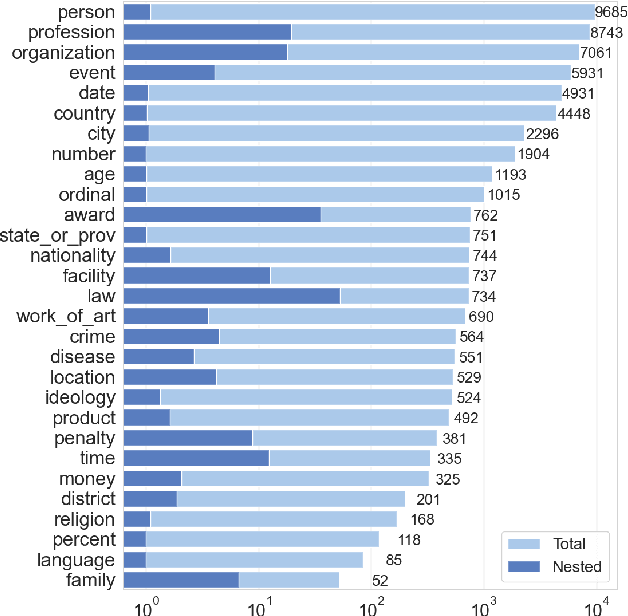
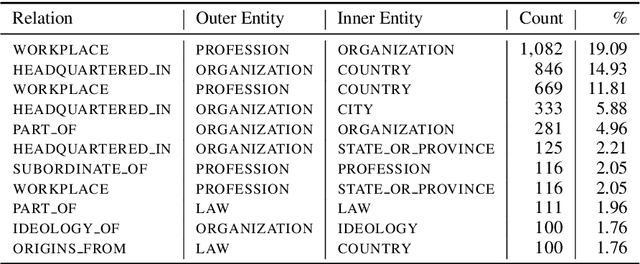
In this paper, we present NEREL, a Russian dataset for named entity recognition and relation extraction. NEREL is significantly larger than existing Russian datasets: to date it contains 56K annotated named entities and 39K annotated relations. Its important difference from previous datasets is annotation of nested named entities, as well as relations within nested entities and at the discourse level. NEREL can facilitate development of novel models that can extract relations between nested named entities, as well as relations on both sentence and document levels. NEREL also contains the annotation of events involving named entities and their roles in the events. The NEREL collection is available via https://github.com/nerel-ds/NEREL.
Transfer Learning for Improving Results on Russian Sentiment Datasets
Jul 06, 2021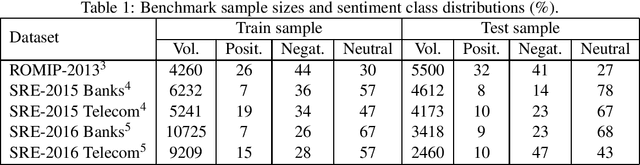
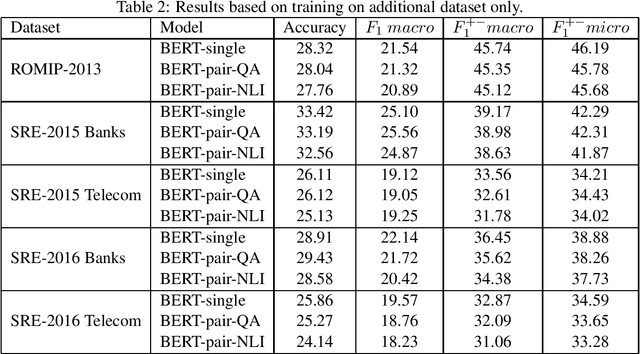
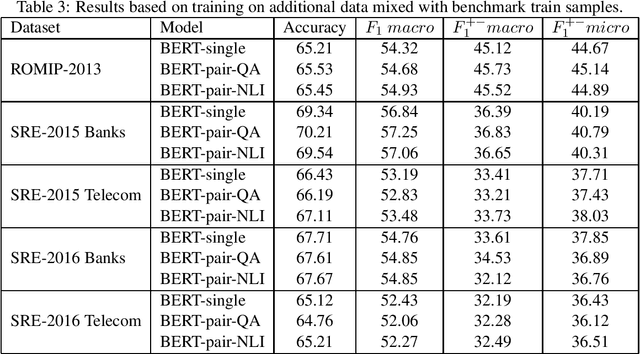
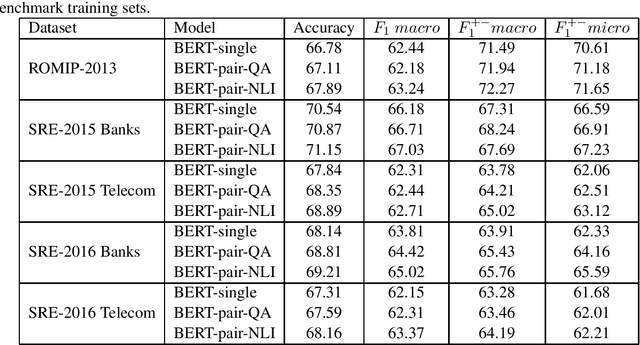
In this study, we test transfer learning approach on Russian sentiment benchmark datasets using additional train sample created with distant supervision technique. We compare several variants of combining additional data with benchmark train samples. The best results were achieved using three-step approach of sequential training on general, thematic and original train samples. For most datasets, the results were improved by more than 3% to the current state-of-the-art methods. The BERT-NLI model treating sentiment classification problem as a natural language inference task reached the human level of sentiment analysis on one of the datasets.
Studying Taxonomy Enrichment on Diachronic WordNet Versions
Nov 23, 2020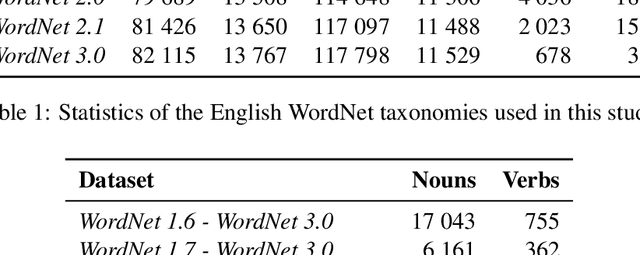
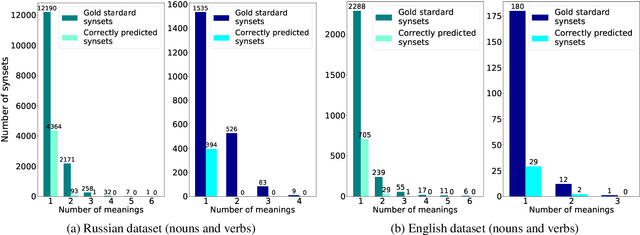
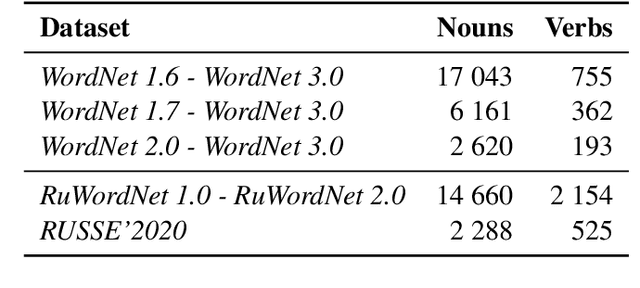
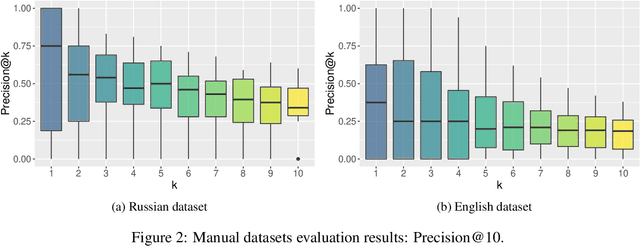
Ontologies, taxonomies, and thesauri are used in many NLP tasks. However, most studies are focused on the creation of these lexical resources rather than the maintenance of the existing ones. Thus, we address the problem of taxonomy enrichment. We explore the possibilities of taxonomy extension in a resource-poor setting and present methods which are applicable to a large number of languages. We create novel English and Russian datasets for training and evaluating taxonomy enrichment models and describe a technique of creating such datasets for other languages.
Improving Results on Russian Sentiment Datasets
Jul 28, 2020
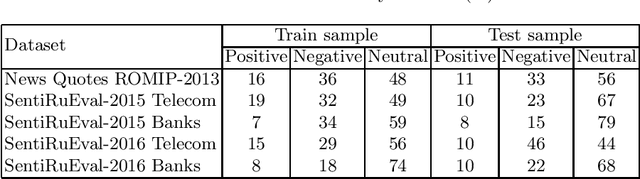
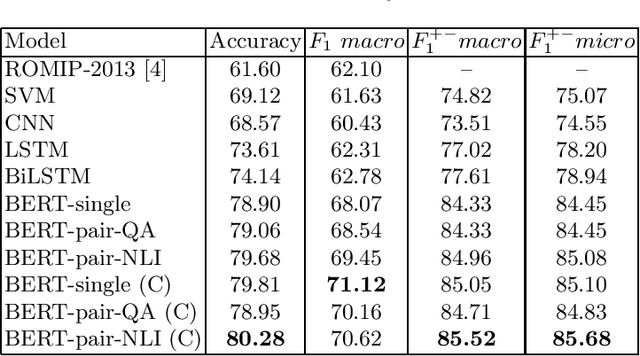
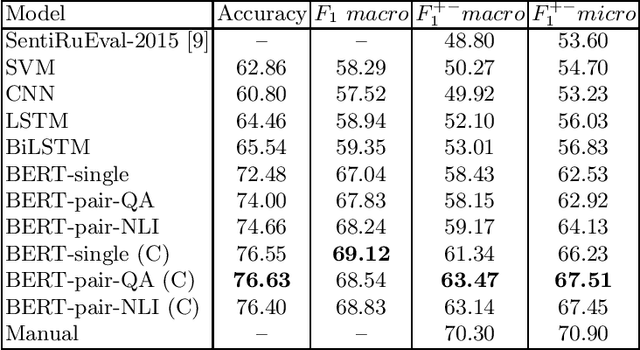
In this study, we test standard neural network architectures (CNN, LSTM, BiLSTM) and recently appeared BERT architectures on previous Russian sentiment evaluation datasets. We compare two variants of Russian BERT and show that for all sentiment tasks in this study the conversational variant of Russian BERT performs better. The best results were achieved by BERT-NLI model, which treats sentiment classification tasks as a natural language inference task. On one of the datasets, this model practically achieves the human level.
Attention-Based Neural Networks for Sentiment Attitude Extraction using Distant Supervision
Jun 30, 2020
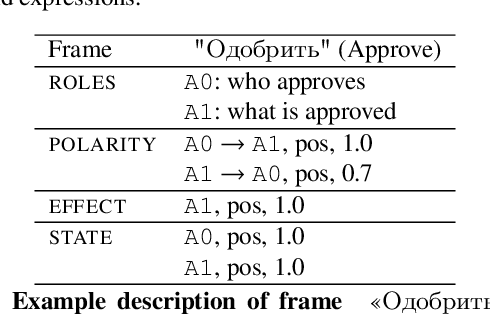

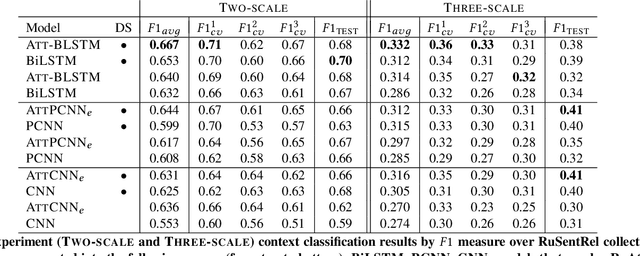
In the sentiment attitude extraction task, the aim is to identify <<attitudes>> -- sentiment relations between entities mentioned in text. In this paper, we provide a study on attention-based context encoders in the sentiment attitude extraction task. For this task, we adapt attentive context encoders of two types: (1) feature-based; (2) self-based. In our study, we utilize the corpus of Russian analytical texts RuSentRel and automatically constructed news collection RuAttitudes for enriching the training set. We consider the problem of attitude extraction as two-class (positive, negative) and three-class (positive, negative, neutral) classification tasks for whole documents. Our experiments with the RuSentRel corpus show that the three-class classification models, which employ the RuAttitudes corpus for training, result in 10% increase and extra 3% by F1, when model architectures include the attention mechanism. We also provide the analysis of attention weight distributions in dependence on the term type.
* 10 pages, 9 figures. The preprint of an article published in the proceedings of the 10th International Conference on Web Intelligence, Mining and Semantics (WIMS 2020). The final authenticated publication is available online at https://doi.org/10.1145/3405962.3405985. arXiv admin note: substantial text overlap with arXiv:2006.11605
Studying Attention Models in Sentiment Attitude Extraction Task
Jun 20, 2020
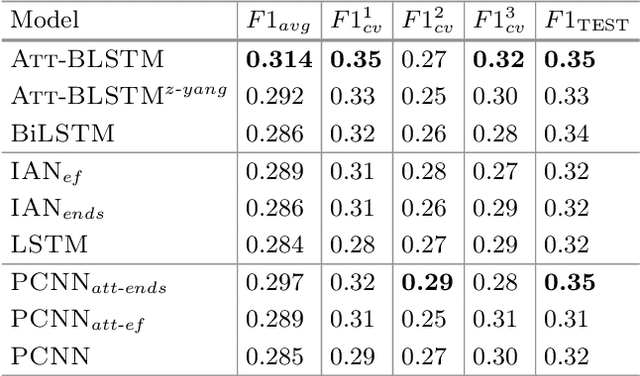
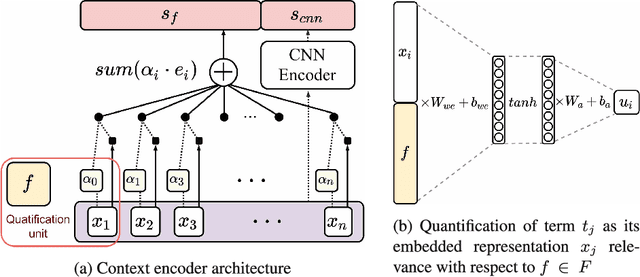
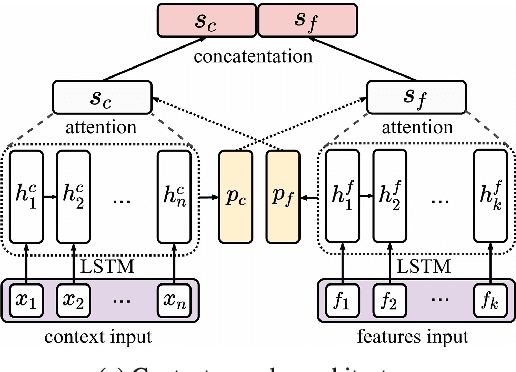
In the sentiment attitude extraction task, the aim is to identify <<attitudes>> -- sentiment relations between entities mentioned in text. In this paper, we provide a study on attention-based context encoders in the sentiment attitude extraction task. For this task, we adapt attentive context encoders of two types: (i) feature-based; (ii) self-based. Our experiments with a corpus of Russian analytical texts RuSentRel illustrate that the models trained with attentive encoders outperform ones that were trained without them and achieve 1.5-5.9% increase by F1. We also provide the analysis of attention weight distributions in dependence on the term type.
* This is a preprint of an article published in the Proceedings of the 25th International Conference on Natural Language and Information Systems. The final authenticated publication is available online at https://doi.org/10.1007/978-3-030-51310-8_15
Sentiment Frames for Attitude Extraction in Russian
Jun 19, 2020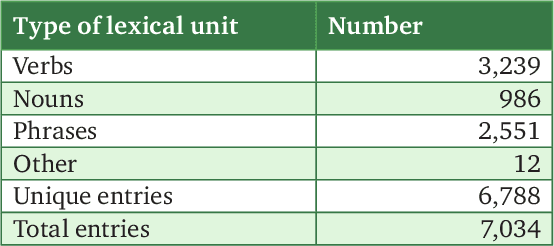
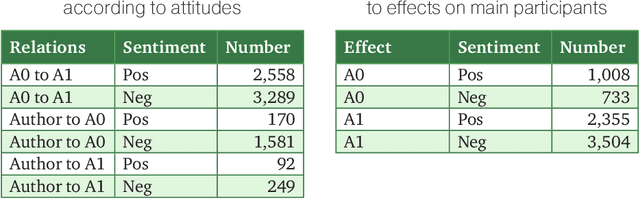

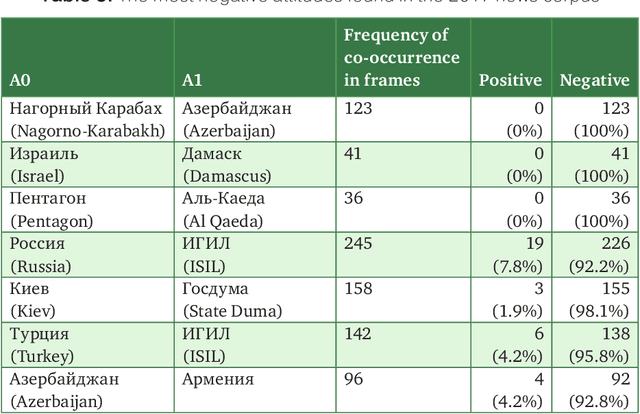
Texts can convey several types of inter-related information concerning opinions and attitudes. Such information includes the author's attitude towards mentioned entities, attitudes of the entities towards each other, positive and negative effects on the entities in the described situations. In this paper, we described the lexicon RuSentiFrames for Russian, where predicate words and expressions are collected and linked to so-called sentiment frames conveying several types of presupposed information on attitudes and effects. We applied the created frames in the task of extracting attitudes from a large news collection.
* 12 pages, 1 figure, 6 tables
RUSSE'2020: Findings of the First Taxonomy Enrichment Task for the Russian language
May 22, 2020
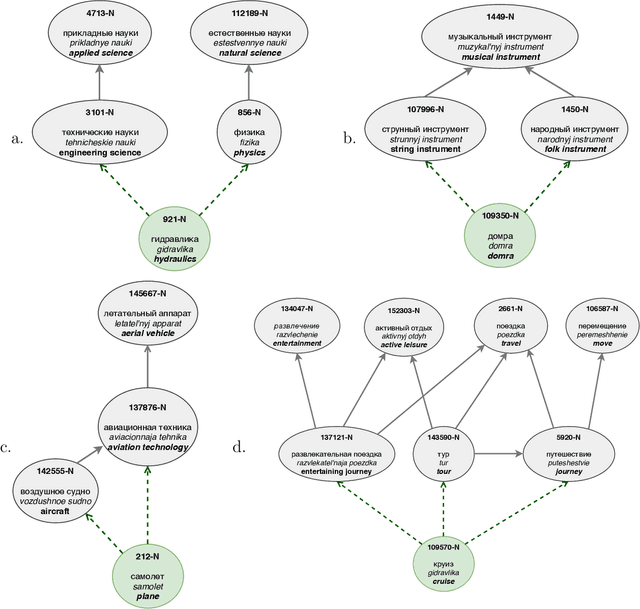
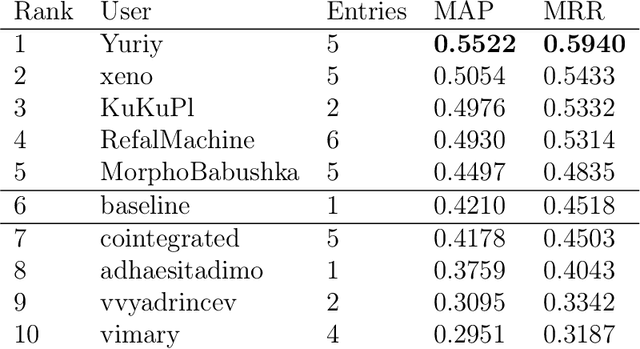
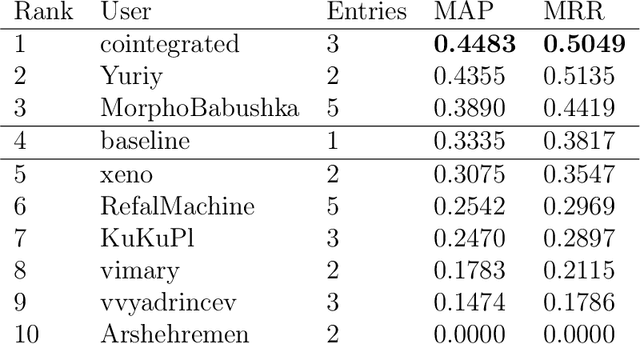
This paper describes the results of the first shared task on taxonomy enrichment for the Russian language. The participants were asked to extend an existing taxonomy with previously unseen words: for each new word their systems should provide a ranked list of possible (candidate) hypernyms. In comparison to the previous tasks for other languages, our competition has a more realistic task setting: new words were provided without definitions. Instead, we provided a textual corpus where these new terms occurred. For this evaluation campaign, we developed a new evaluation dataset based on unpublished RuWordNet data. The shared task features two tracks: "nouns" and "verbs". 16 teams participated in the task demonstrating high results with more than half of them outperforming the provided baseline.