 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Protocol: Security Analysis of the Model Context Protocol Specification and Prompt Injection Vulnerabilities in Tool-Integrated LLM Agents
Jan 24, 2026The Model Context Protocol (MCP) has emerged as a de facto standard for integrating Large Language Models with external tools, yet no formal security analysis of the protocol specification exists. We present the first rigorous security analysis of MCP's architectural design, identifying three fundamental protocol-level vulnerabilities: (1) absence of capability attestation allowing servers to claim arbitrary permissions, (2) bidirectional sampling without origin authentication enabling server-side prompt injection, and (3) implicit trust propagation in multi-server configurations. We implement \textsc{MCPBench}, a novel framework bridging existing agent security benchmarks to MCP-compliant infrastructure, enabling direct measurement of protocol-specific attack surfaces. Through controlled experiments on 847 attack scenarios across five MCP server implementations, we demonstrate that MCP's architectural choices amplify attack success rates by 23--41\% compared to equivalent non-MCP integrations. We propose \textsc{MCPSec}, a backward-compatible protocol extension adding capability attestation and message authentication, reducing attack success rates from 52.8\% to 12.4\% with median latency overhead of 8.3ms per message. Our findings establish that MCP's security weaknesses are architectural rather than implementation-specific, requiring protocol-level remediation.
Investigating the Vulnerability of LLM-as-a-Judge Architectures to Prompt-Injection Attacks
May 19, 2025Large Language Models (LLMs) are increasingly employed as evaluators (LLM-as-a-Judge) for assessing the quality of machine-generated text. This paradigm offers scalability and cost-effectiveness compared to human annotation. However, the reliability and security of such systems, particularly their robustness against adversarial manipulations, remain critical concerns. This paper investigates the vulnerability of LLM-as-a-Judge architectures to prompt-injection attacks, where malicious inputs are designed to compromise the judge's decision-making process. We formalize two primary attack strategies: Comparative Undermining Attack (CUA), which directly targets the final decision output, and Justification Manipulation Attack (JMA), which aims to alter the model's generated reasoning. Using the Greedy Coordinate Gradient (GCG) optimization method, we craft adversarial suffixes appended to one of the responses being compared. Experiments conducted on the MT-Bench Human Judgments dataset with open-source instruction-tuned LLMs (Qwen2.5-3B-Instruct and Falcon3-3B-Instruct) demonstrate significant susceptibility. The CUA achieves an Attack Success Rate (ASR) exceeding 30\%, while JMA also shows notable effectiveness. These findings highlight substantial vulnerabilities in current LLM-as-a-Judge systems, underscoring the need for robust defense mechanisms and further research into adversarial evaluation and trustworthiness in LLM-based assessment frameworks.
Adversarial Attacks on LLM-as-a-Judge Systems: Insights from Prompt Injections
Apr 25, 2025LLM as judge systems used to assess text quality code correctness and argument strength are vulnerable to prompt injection attacks. We introduce a framework that separates content author attacks from system prompt attacks and evaluate five models Gemma 3.27B Gemma 3.4B Llama 3.2 3B GPT 4 and Claude 3 Opus on four tasks with various defenses using fifty prompts per condition. Attacks achieved up to seventy three point eight percent success smaller models proved more vulnerable and transferability ranged from fifty point five to sixty two point six percent. Our results contrast with Universal Prompt Injection and AdvPrompter We recommend multi model committees and comparative scoring and release all code and datasets
Prompt Injection Attacks in Defended Systems
Jun 20, 2024Large language models play a crucial role in modern natural language processing technologies. However, their extensive use also introduces potential security risks, such as the possibility of black-box attacks. These attacks can embed hidden malicious features into the model, leading to adverse consequences during its deployment. This paper investigates methods for black-box attacks on large language models with a three-tiered defense mechanism. It analyzes the challenges and significance of these attacks, highlighting their potential implications for language processing system security. Existing attack and defense methods are examined, evaluating their effectiveness and applicability across various scenarios. Special attention is given to the detection algorithm for black-box attacks, identifying hazardous vulnerabilities in language models and retrieving sensitive information. This research presents a methodology for vulnerability detection and the development of defensive strategies against black-box attacks on large language models.
Trojan Detection in Large Language Models: Insights from The Trojan Detection Challenge
Apr 21, 2024
Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, but their vulnerability to trojan or backdoor attacks poses significant security risks. This paper explores the challenges and insights gained from the Trojan Detection Competition 2023 (TDC2023), which focused on identifying and evaluating trojan attacks on LLMs. We investigate the difficulty of distinguishing between intended and unintended triggers, as well as the feasibility of reverse engineering trojans in real-world scenarios. Our comparative analysis of various trojan detection methods reveals that achieving high Recall scores is significantly more challenging than obtaining high Reverse-Engineering Attack Success Rate (REASR) scores. The top-performing methods in the competition achieved Recall scores around 0.16, comparable to a simple baseline of randomly sampling sentences from a distribution similar to the given training prefixes. This finding raises questions about the detectability and recoverability of trojans inserted into the model, given only the harmful targets. Despite the inability to fully solve the problem, the competition has led to interesting observations about the viability of trojan detection and improved techniques for optimizing LLM input prompts. The phenomenon of unintended triggers and the difficulty in distinguishing them from intended triggers highlights the need for further research into the robustness and interpretability of LLMs. The TDC2023 has provided valuable insights into the challenges and opportunities associated with trojan detection in LLMs, laying the groundwork for future research in this area to ensure their safety and reliability in real-world applications.
DN at SemEval-2023 Task 12: Low-Resource Language Text Classification via Multilingual Pretrained Language Model Fine-tuning
May 04, 2023In recent years, sentiment analysis has gained significant importance in natural language processing. However, most existing models and datasets for sentiment analysis are developed for high-resource languages, such as English and Chinese, leaving low-resource languages, particularly African languages, largely unexplored. The AfriSenti-SemEval 2023 Shared Task 12 aims to fill this gap by evaluating sentiment analysis models on low-resource African languages. In this paper, we present our solution to the shared task, where we employed different multilingual XLM-R models with classification head trained on various data, including those retrained in African dialects and fine-tuned on target languages. Our team achieved the third-best results in Subtask B, Track 16: Multilingual, demonstrating the effectiveness of our approach. While our model showed relatively good results on multilingual data, it performed poorly in some languages. Our findings highlight the importance of developing more comprehensive datasets and models for low-resource African languages to advance sentiment analysis research. We also provided the solution on the github repository.
DIALOG-22 RuATD Generated Text Detection
Jun 16, 2022
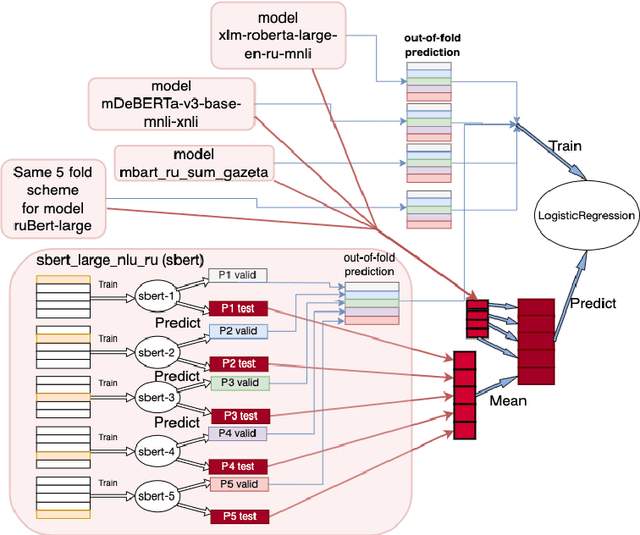


Text Generation Models (TGMs) succeed in creating text that matches human language style reasonably well. Detectors that can distinguish between TGM-generated text and human-written ones play an important role in preventing abuse of TGM. In this paper, we describe our pipeline for the two DIALOG-22 RuATD tasks: detecting generated text (binary task) and classification of which model was used to generate text (multiclass task). We achieved 1st place on the binary classification task with an accuracy score of 0.82995 on the private test set and 4th place on the multiclass classification task with an accuracy score of 0.62856 on the private test set. We proposed an ensemble method of different pre-trained models based on the attention mechanism.