 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Integrated Variational Autoencoders for Robust and Interpretable Generative Modeling
Feb 25, 2021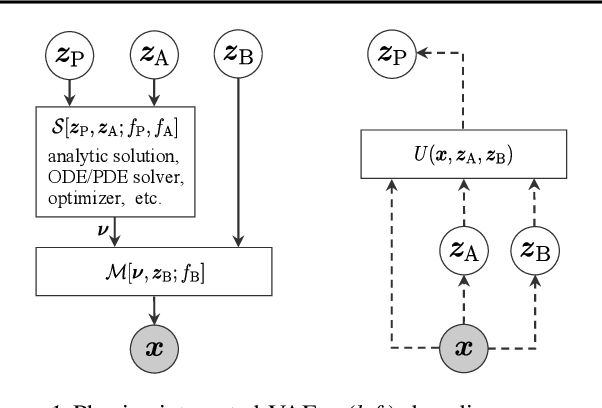
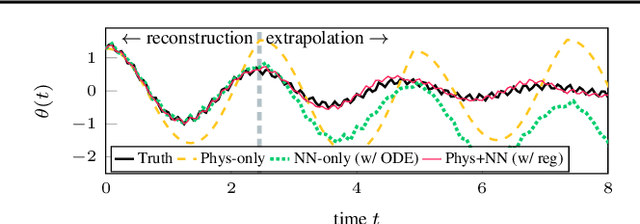

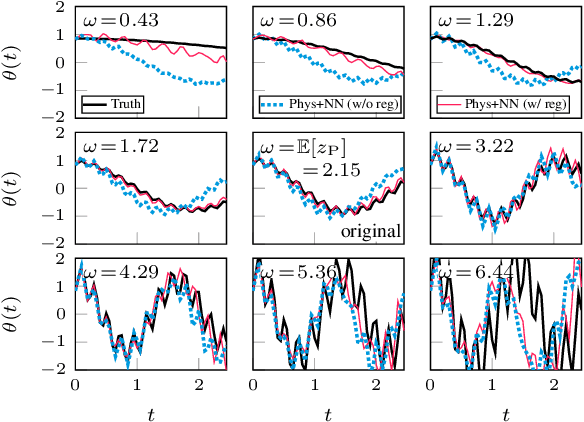
Integrating physics models within machine learning holds considerable promise toward learning robust models with improved interpretability and abilities to extrapolate. In this work, we focus on the integration of incomplete physics models into deep generative models, variational autoencoders (VAEs) in particular. A key technical challenge is to strike a balance between the incomplete physics model and the learned components (i.e., neural nets) of the complete model, in order to ensure that the physics part is used in a meaningful manner. To this end, we propose a VAE architecture in which a part of the latent space is grounded by physics. We couple it with a set of regularizers that control the effect of the learned components and preserve the semantics of the physics-based latent variables as intended. We not only demonstrate generative performance improvements over a set of synthetic and real-world datasets, but we also show that we learn robust models that can consistently extrapolate beyond the training distribution in a meaningful manner. Moreover, we show that we can control the generative process in an interpretable manner.
Discriminant Dynamic Mode Decomposition for Labeled Spatio-Temporal Data Collections
Feb 19, 2021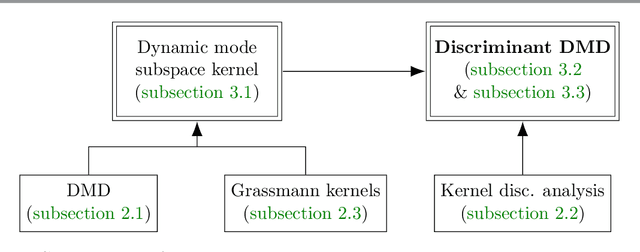
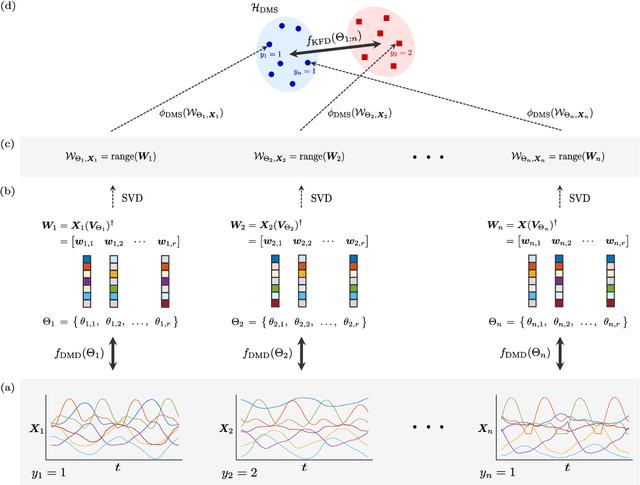
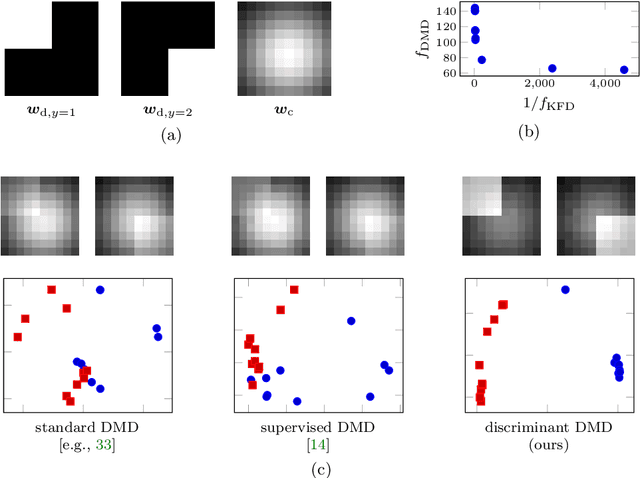
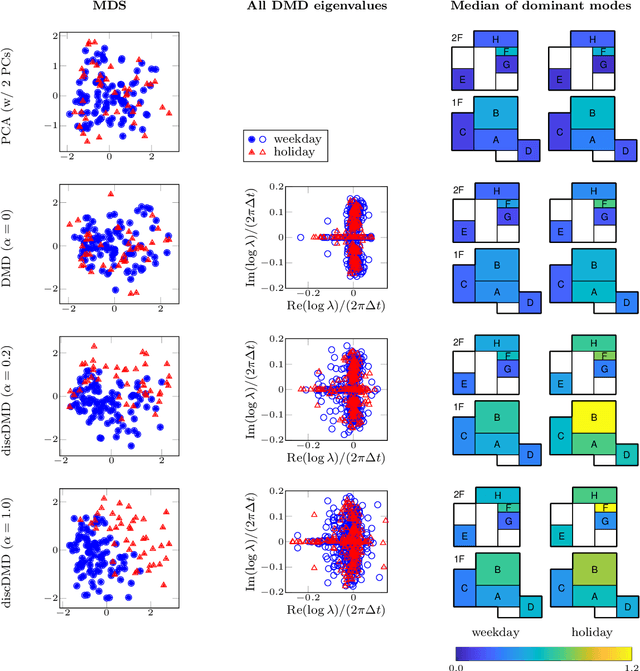
Extracting coherent patterns is one of the standard approaches towards understanding spatio-temporal data. Dynamic mode decomposition (DMD) is a powerful tool for extracting coherent patterns, but the original DMD and most of its variants do not consider label information, which is often available as side information of spatio-temporal data. In this work, we propose a new method for extracting distinctive coherent patterns from labeled spatio-temporal data collections, such that they contribute to major differences in a labeled set of dynamics. We achieve such pattern extraction by incorporating discriminant analysis into DMD. To this end, we define a kernel function on subspaces spanned by sets of dynamic modes and develop an objective to take both reconstruction goodness as DMD and class-separation goodness as discriminant analysis into account. We illustrate our method using a synthetic dataset and several real-world datasets. The proposed method can be a useful tool for exploratory data analysis for understanding spatio-temporal data.
Policy learning with partial observation and mechanical constraints for multi-person modeling
Jul 07, 2020
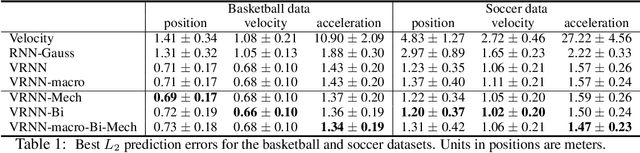
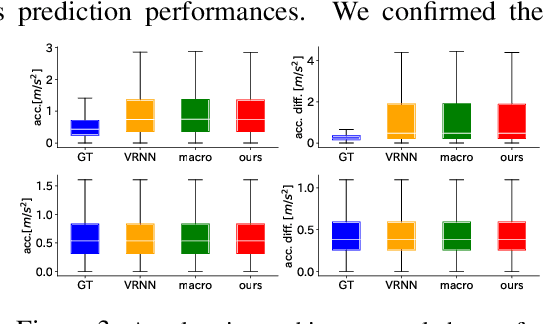
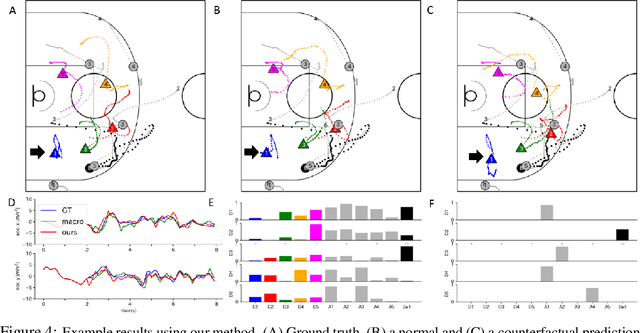
Extracting the rules of real-world biological multi-agent behaviors is a current challenge in various scientific and engineering fields. Biological agents generally have limited observation and mechanical constraints; however, most of the conventional data-driven models ignore such assumptions, resulting in lack of biological plausibility and model interpretability for behavioral analyses in biological and cognitive science. Here we propose sequential generative models with partial observation and mechanical constraints, which can visualize whose information the agents utilize and can generate biologically plausible actions. We formulate this as a decentralized multi-agent imitation learning problem, leveraging binary partial observation models with a Gumbel-Softmax reparameterization and policy models based on hierarchical variational recurrent neural networks with physical and biomechanical constraints. We investigate the empirical performances using real-world multi-person motion datasets from basketball and soccer games.
Learning Dynamics Models with Stable Invariant Sets
Jun 16, 2020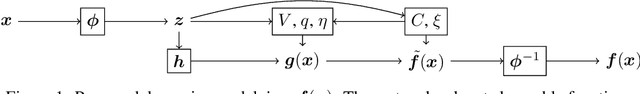
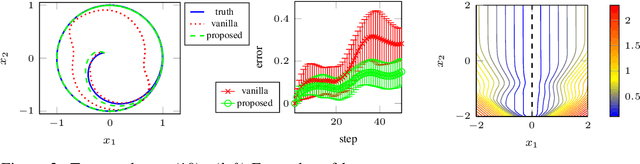
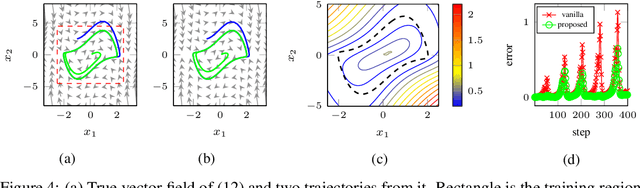
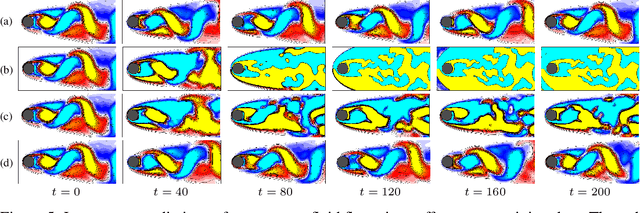
Stable invariant sets are an essential notion in the analysis and application of dynamical systems. It is thus of great interest to learn dynamical systems with provable existence of stable invariant sets. However, existing methods can only deal with the stability of discrete equilibria, which hinders many applications. In this paper, we propose a method to ensure that a learned dynamics model has a stable invariant set of general classes. To this end, we modify a base dynamics model using a learnable Lyapunov-like function so that the modified dynamics attain the invariance and the stability of a specific subset. We model such a subset by transforming primitive shapes (e.g., spheres) via a learnable bijective function. We may specify such a primitive shape following prior knowledge of the dynamics if any, or it can also be learned from data. We introduce an example of the implementation of the proposed dynamics models using neural networks and present experimental results that show the validity of the proposed method.
On Anomaly Interpretation via Shapley Values
Apr 09, 2020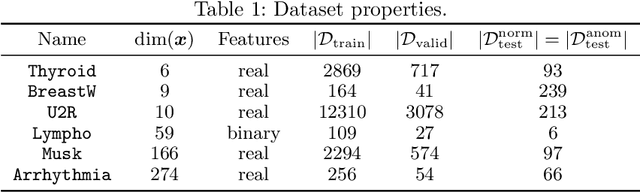
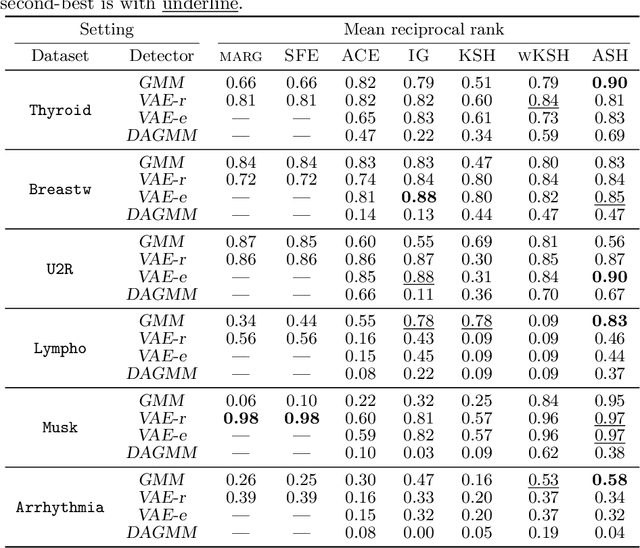
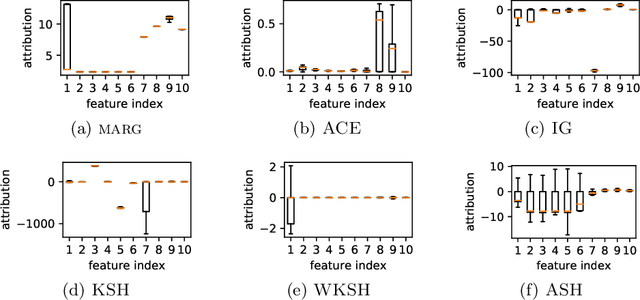
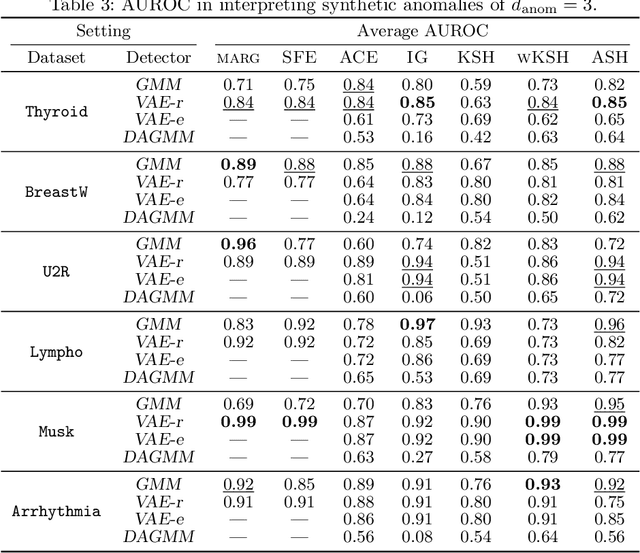
Anomaly localization is an essential problem as anomaly detection is. Because a rigorous localization requires a causal model of a target system, practically we often resort to a relaxed problem of anomaly interpretation, for which we are to obtain meaningful attribution of anomaly scores to input features. In this paper, we investigate the use of the Shapley value for anomaly interpretation. We focus on the semi-supervised anomaly detection and newly propose a characteristic function, on which the Shapley value is computed, specifically for anomaly scores. The idea of the proposed method is approximating the absence of some features by minimizing an anomaly score with regard to them. We examine the performance of the proposed method as well as other general approaches to computing the Shapley value in interpreting anomaly scores. We show the results of experiments on multiple datasets and anomaly detection methods, which indicate the usefulness of the Shapley-based anomaly interpretation toward anomaly localization.
Shapley Values of Reconstruction Errors of PCA for Explaining Anomaly Detection
Sep 08, 2019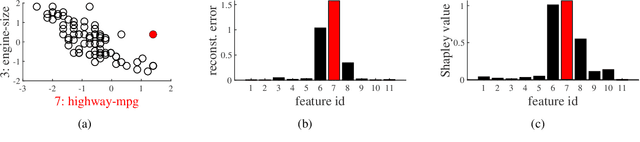
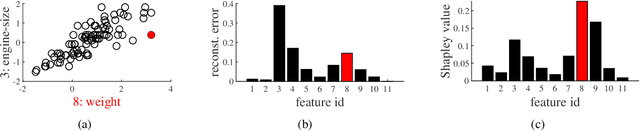
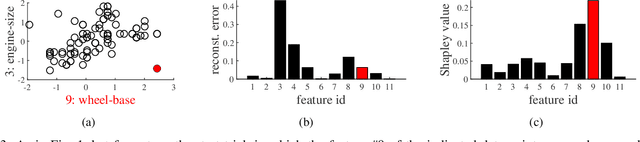
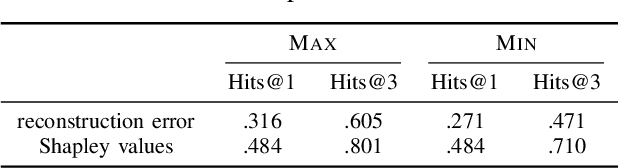
We present a method to compute the Shapley values of reconstruction errors of principal component analysis (PCA), which is particularly useful in explaining the results of anomaly detection based on PCA. Because features are usually correlated when PCA-based anomaly detection is applied, care must be taken in computing a value function for the Shapley values. We utilize the probabilistic view of PCA, particularly its conditional distribution, to exactly compute a value function for the Shapely values. We also present numerical examples, which imply that the Shapley values are advantageous for explaining detected anomalies than raw reconstruction errors of each feature.
Physically-interpretable classification of network dynamics for complex collective motions
May 13, 2019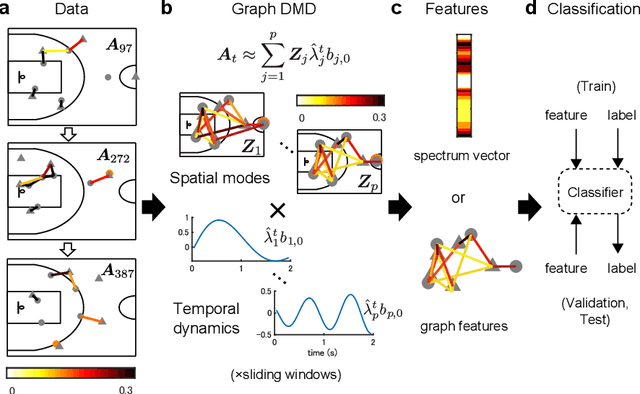
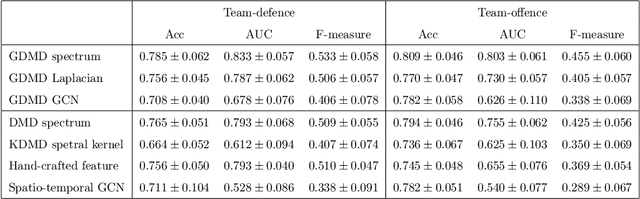
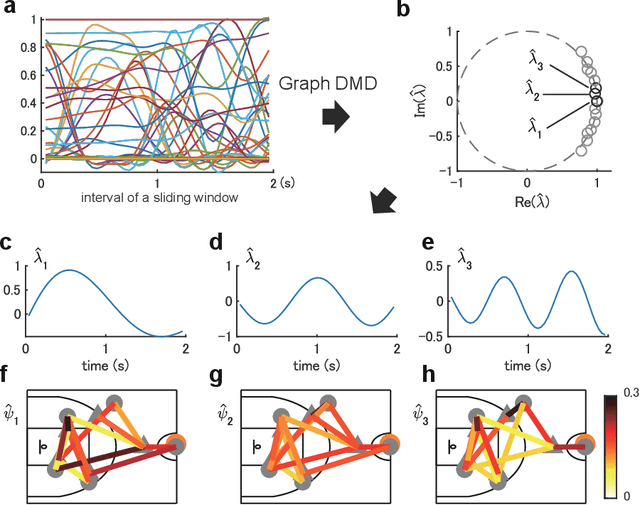
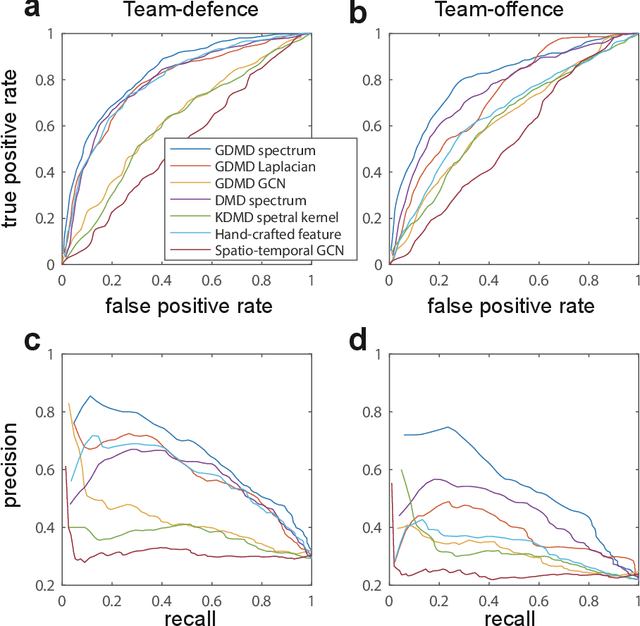
Understanding complex network dynamics is a fundamental issue in various scientific and engineering fields. Network theory is capable of revealing the relationship between elements and their propagation; however, for complex collective motions, the network properties often transiently and complexly change. A fundamental question addressed here pertains to the classification of collective motion network based on physically-interpretable dynamical properties. Here we apply a data-driven spectral analysis called graph dynamic mode decomposition, which obtains the dynamical properties for collective motion classification. Using a ballgame as an example, we classified the strategic collective motions in different global behaviours and discovered that, in addition to the physical properties, the contextual node information was critical for classification. Furthermore, we discovered the label-specific stronger spectra in the relationship among the nearest agents, providing physical and semantic interpretations. Our approach contributes to the understanding of complex networks involving collective motions from the perspective of nonlinear dynamical systems.
Regularizing Generative Models Using Knowledge of Feature Dependence
Feb 06, 2019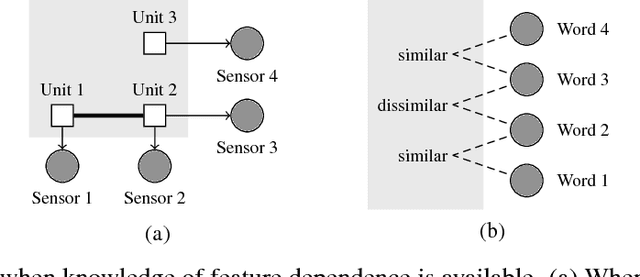


Generative modeling is a fundamental problem in machine learning with many potential applications. Efficient learning of generative models requires available prior knowledge to be exploited as much as possible. In this paper, we propose a method to exploit prior knowledge of relative dependence between features for learning generative models. Such knowledge is available, for example, when side-information on features is present. We incorporate the prior knowledge by forcing marginals of the learned generative model to follow a prescribed relative feature dependence. To this end, we formulate a regularization term using a kernel-based dependence criterion. The proposed method can be incorporated straightforwardly into many optimization-based learning schemes of generative models, including variational autoencoders and generative adversarial networks. We show the effectiveness of the proposed method in experiments with multiple types of datasets and models.
Knowledge-Based Distant Regularization in Learning Probabilistic Models
Jun 29, 2018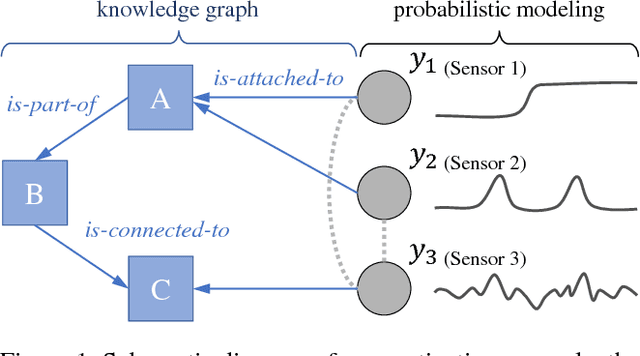
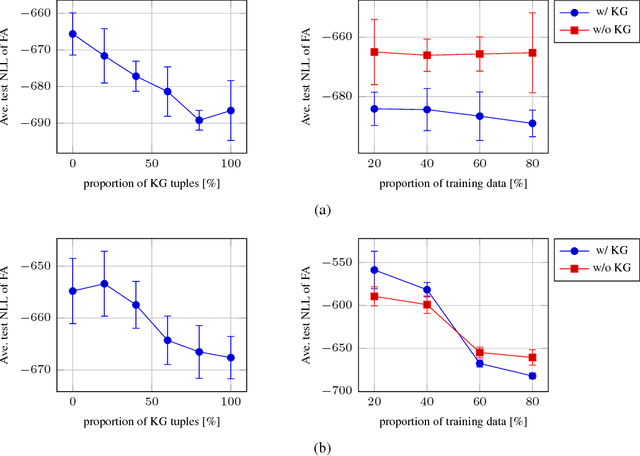
Exploiting the appropriate inductive bias based on the knowledge of data is essential for achieving good performance in statistical machine learning. In practice, however, the domain knowledge of interest often provides information on the relationship of data attributes only distantly, which hinders direct utilization of such domain knowledge in popular regularization methods. In this paper, we propose the knowledge-based distant regularization framework, in which we utilize the distant information encoded in a knowledge graph for regularization of probabilistic model estimation. In particular, we propose to impose prior distributions on model parameters specified by knowledge graph embeddings. As an instance of the proposed framework, we present the factor analysis model with the knowledge-based distant regularization. We show the results of preliminary experiments on the improvement of the generalization capability of such model.
Dynamic and Static Topic Model for Analyzing Time-Series Document Collections
May 06, 2018
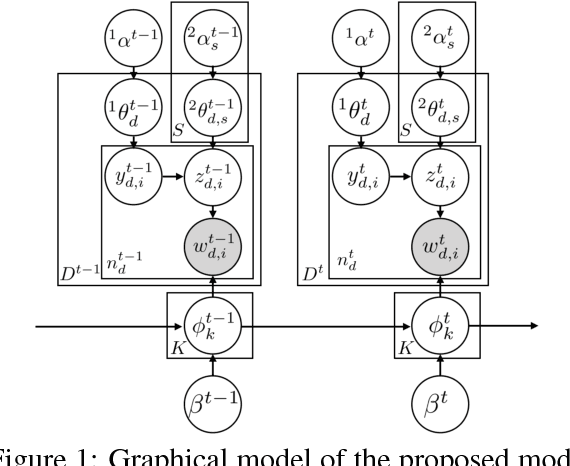
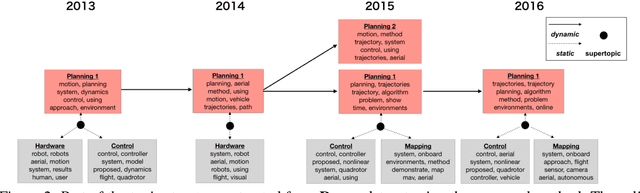
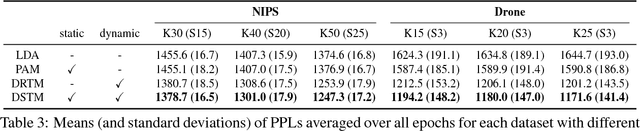
For extracting meaningful topics from texts, their structures should be considered properly. In this paper, we aim to analyze structured time-series documents such as a collection of news articles and a series of scientific papers, wherein topics evolve along time depending on multiple topics in the past and are also related to each other at each time. To this end, we propose a dynamic and static topic model, which simultaneously considers the dynamic structures of the temporal topic evolution and the static structures of the topic hierarchy at each time. We show the results of experiments on collections of scientific papers, in which the proposed method outperformed conventional models. Moreover, we show an example of extracted topic structures, which we found helpful for analyzing research activities.