 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative modeling of density regression through tree flows
Jun 07, 2024A common objective in the analysis of tabular data is estimating the conditional distribution (in contrast to only producing predictions) of a set of "outcome" variables given a set of "covariates", which is sometimes referred to as the "density regression" problem. Beyond estimation on the conditional distribution, the generative ability of drawing synthetic samples from the learned conditional distribution is also desired as it further widens the range of applications. We propose a flow-based generative model tailored for the density regression task on tabular data. Our flow applies a sequence of tree-based piecewise-linear transforms on initial uniform noise to eventually generate samples from complex conditional densities of (univariate or multivariate) outcomes given the covariates and allows efficient analytical evaluation of the fitted conditional density on any point in the sample space. We introduce a training algorithm for fitting the tree-based transforms using a divide-and-conquer strategy that transforms maximum likelihood training of the tree-flow into training a collection of binary classifiers--one at each tree split--under cross-entropy loss. We assess the performance of our method under out-of-sample likelihood evaluation and compare it with a variety of state-of-the-art conditional density learners on a range of simulated and real benchmark tabular datasets. Our method consistently achieves comparable or superior performance at a fraction of the training and sampling budget. Finally, we demonstrate the utility of our method's generative ability through an application to generating synthetic longitudinal microbiome compositional data based on training our flow on a publicly available microbiome study.
Tree boosting for learning probability measures
Feb 18, 2021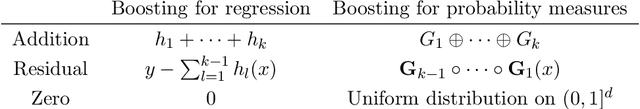

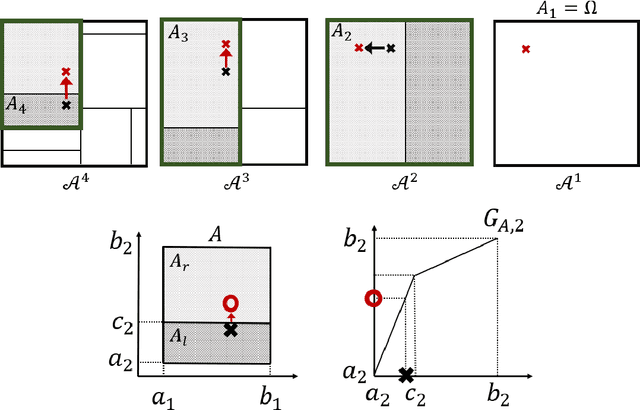

Learning probability measures based on an i.i.d. sample is a fundamental inference task, but is challenging when the sample space is high-dimensional. Inspired by the success of tree boosting in high-dimensional classification and regression, we propose a tree boosting method for learning high-dimensional probability distributions. We formulate concepts of "addition'' and "residuals'' on probability distributions in terms of compositions of a new, more general notion of multivariate cumulative distribution functions (CDFs) than classical CDFs. This then gives rise to a simple boosting algorithm based on forward-stagewise (FS) fitting of an additive ensemble of measures. The output of the FS algorithm allows analytic computation of the probability density function for the fitted distribution. It also provides an exact simulator for drawing independent Monte Carlo samples from the fitted measure. Typical considerations in applying boosting -- namely choosing the number of trees, setting the appropriate level of shrinkage/regularization in the weak learner, and the evaluation of variable importance -- can be accomplished in an analogous fashion to traditional boosting in supervised learning. Numerical experiments confirm that boosting can substantially improve the fit to multivariate distributions compared to the state-of-the-art single-tree learner and is computationally efficient. We illustrate through an application to a data set from mass cytometry how the simulator can be used to investigate various aspects of the underlying distribution.