 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Option Learning in Markov Decision Processes
Mar 30, 2017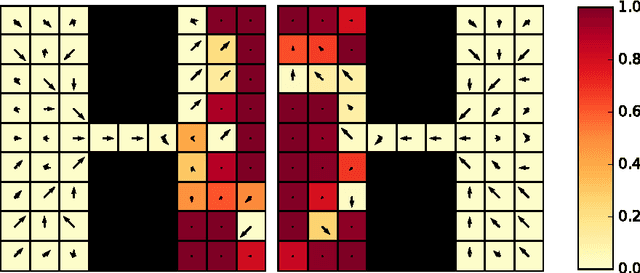
It is well known that options can make planning more efficient, among their many benefits. Thus far, algorithms for autonomously discovering a set of useful options were heuristic. Naturally, a principled way of finding a set of useful options may be more promising and insightful. In this paper we suggest a mathematical characterization of good sets of options using tools from information theory. This characterization enables us to find conditions for a set of options to be optimal and an algorithm that outputs a useful set of options and illustrate the proposed algorithm in simulation.
Taming the Noise in Reinforcement Learning via Soft Updates
Mar 30, 2017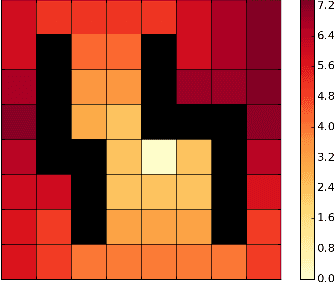
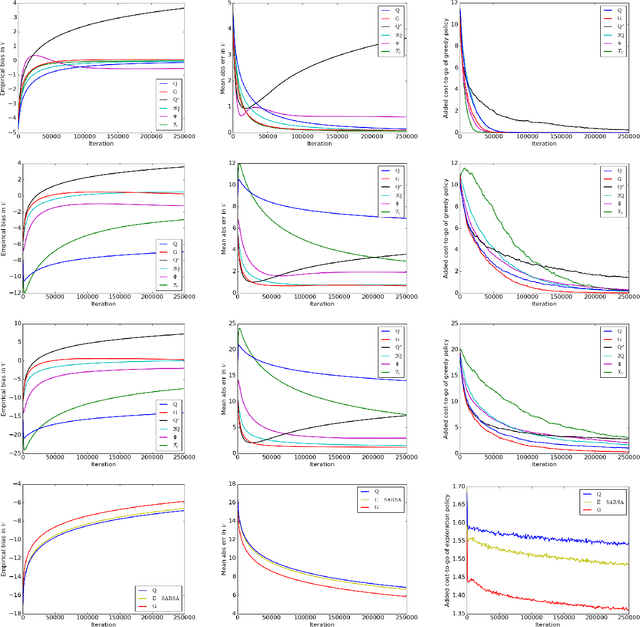
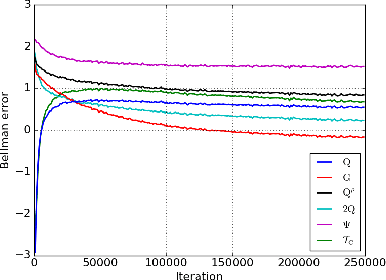
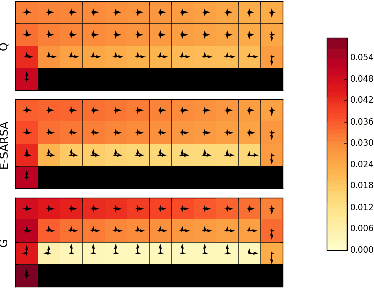
Model-free reinforcement learning algorithms, such as Q-learning, perform poorly in the early stages of learning in noisy environments, because much effort is spent unlearning biased estimates of the state-action value function. The bias results from selecting, among several noisy estimates, the apparent optimum, which may actually be suboptimal. We propose G-learning, a new off-policy learning algorithm that regularizes the value estimates by penalizing deterministic policies in the beginning of the learning process. We show that this method reduces the bias of the value-function estimation, leading to faster convergence to the optimal value and the optimal policy. Moreover, G-learning enables the natural incorporation of prior domain knowledge, when available. The stochastic nature of G-learning also makes it avoid some exploration costs, a property usually attributed only to on-policy algorithms. We illustrate these ideas in several examples, where G-learning results in significant improvements of the convergence rate and the cost of the learning process.
Mixing Complexity and its Applications to Neural Networks
Mar 02, 2017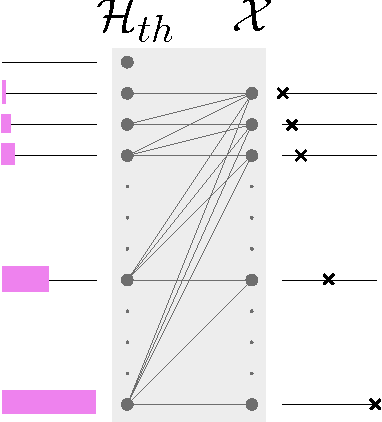
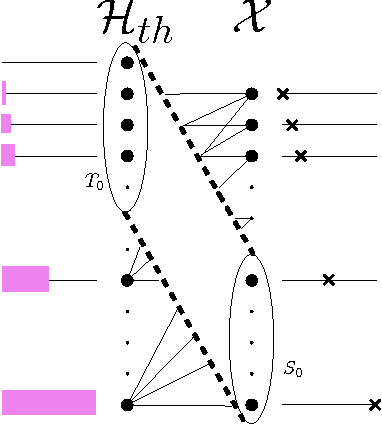
We suggest analyzing neural networks through the prism of space constraints. We observe that most training algorithms applied in practice use bounded memory, which enables us to use a new notion introduced in the study of space-time tradeoffs that we call mixing complexity. This notion was devised in order to measure the (in)ability to learn using a bounded-memory algorithm. In this paper we describe how we use mixing complexity to obtain new results on what can and cannot be learned using neural networks.
Memory shapes time perception and intertemporal choices
May 29, 2016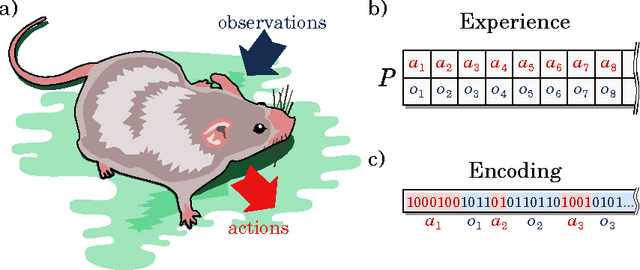
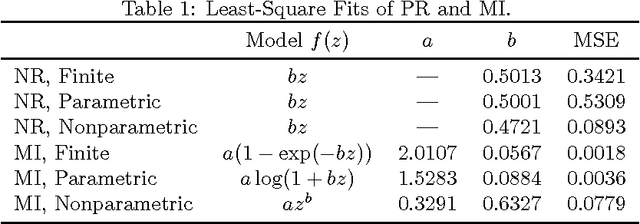

There is a consensus that human and non-human subjects experience temporal distortions in many stages of their perceptual and decision-making systems. Similarly, intertemporal choice research has shown that decision-makers undervalue future outcomes relative to immediate ones. Here we combine techniques from information theory and artificial intelligence to show how both temporal distortions and intertemporal choice preferences can be explained as a consequence of the coding efficiency of sensorimotor representation. In particular, the model implies that interactions that constrain future behavior are perceived as being both longer in duration and more valuable. Furthermore, using simulations of artificial agents, we investigate how memory constraints enforce a renormalization of the perceived timescales. Our results show that qualitatively different discount functions, such as exponential and hyperbolic discounting, arise as a consequence of an agent's probabilistic model of the world.
Optimal Selective Attention in Reactive Agents
Dec 29, 2015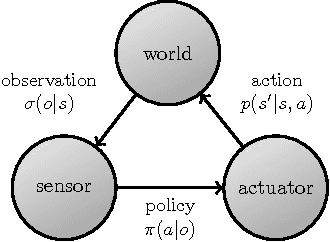
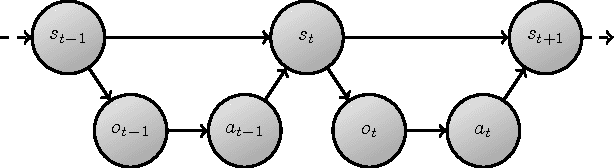
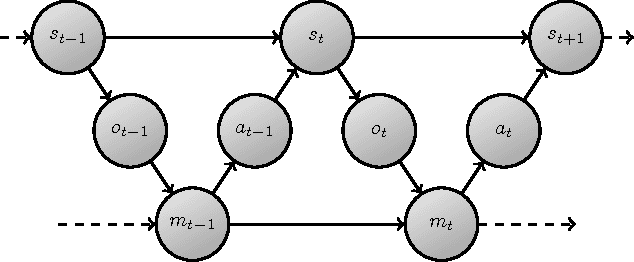
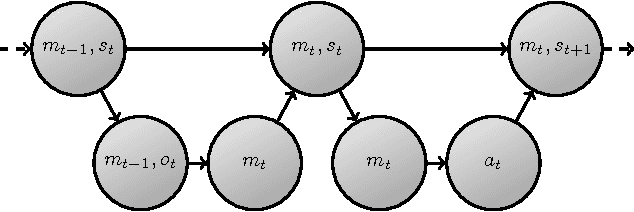
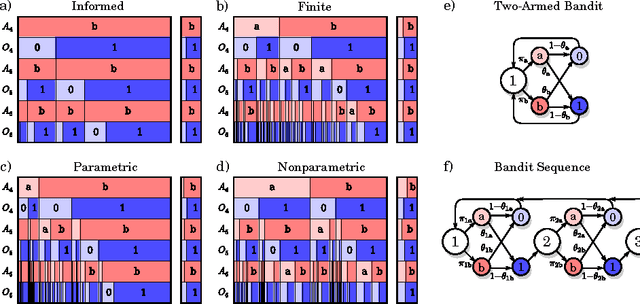
In POMDPs, information about the hidden state, delivered through observations, is both valuable to the agent, allowing it to base its actions on better informed internal states, and a "curse", exploding the size and diversity of the internal state space. One attempt to deal with this is to focus on reactive policies, that only base their actions on the most recent observation. However, even reactive policies can be demanding on resources, and agents need to pay selective attention to only some of the information available to them in observations. In this report we present the minimum-information principle for selective attention in reactive agents. We further motivate this approach by reducing the general problem of optimal control in POMDPs, to reactive control with complex observations. Lastly, we explore a newly discovered phenomenon of this optimization process - period doubling bifurcations. This necessitates periodic policies, and raises many more questions regarding stability, periodicity and chaos in optimal control.
Information-Theoretic Bounded Rationality
Dec 21, 2015Bounded rationality, that is, decision-making and planning under resource limitations, is widely regarded as an important open problem in artificial intelligence, reinforcement learning, computational neuroscience and economics. This paper offers a consolidated presentation of a theory of bounded rationality based on information-theoretic ideas. We provide a conceptual justification for using the free energy functional as the objective function for characterizing bounded-rational decisions. This functional possesses three crucial properties: it controls the size of the solution space; it has Monte Carlo planners that are exact, yet bypass the need for exhaustive search; and it captures model uncertainty arising from lack of evidence or from interacting with other agents having unknown intentions. We discuss the single-step decision-making case, and show how to extend it to sequential decisions using equivalence transformations. This extension yields a very general class of decision problems that encompass classical decision rules (e.g. EXPECTIMAX and MINIMAX) as limit cases, as well as trust- and risk-sensitive planning.
Deep Learning and the Information Bottleneck Principle
Mar 09, 2015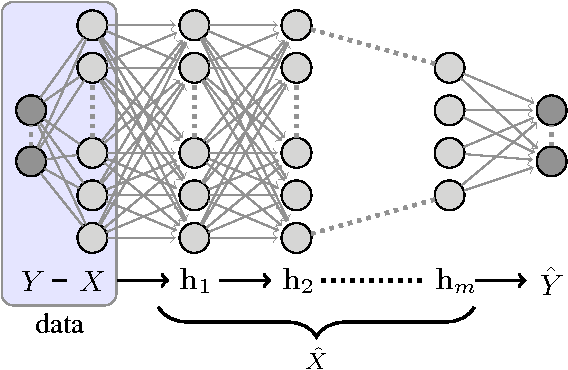
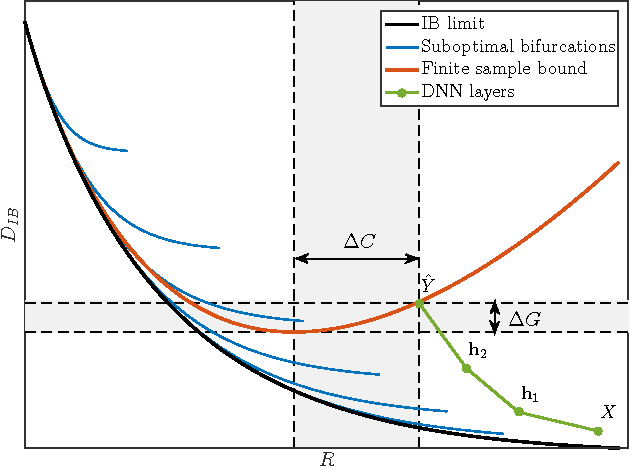
Deep Neural Networks (DNNs) are analyzed via the theoretical framework of the information bottleneck (IB) principle. We first show that any DNN can be quantified by the mutual information between the layers and the input and output variables. Using this representation we can calculate the optimal information theoretic limits of the DNN and obtain finite sample generalization bounds. The advantage of getting closer to the theoretical limit is quantifiable both by the generalization bound and by the network's simplicity. We argue that both the optimal architecture, number of layers and features/connections at each layer, are related to the bifurcation points of the information bottleneck tradeoff, namely, relevant compression of the input layer with respect to the output layer. The hierarchical representations at the layered network naturally correspond to the structural phase transitions along the information curve. We believe that this new insight can lead to new optimality bounds and deep learning algorithms.
Distribution-Dependent Sample Complexity of Large Margin Learning
Sep 18, 2013
We obtain a tight distribution-specific characterization of the sample complexity of large-margin classification with L2 regularization: We introduce the margin-adapted dimension, which is a simple function of the second order statistics of the data distribution, and show distribution-specific upper and lower bounds on the sample complexity, both governed by the margin-adapted dimension of the data distribution. The upper bounds are universal, and the lower bounds hold for the rich family of sub-Gaussian distributions with independent features. We conclude that this new quantity tightly characterizes the true sample complexity of large-margin classification. To prove the lower bound, we develop several new tools of independent interest. These include new connections between shattering and hardness of learning, new properties of shattering with linear classifiers, and a new lower bound on the smallest eigenvalue of a random Gram matrix generated by sub-Gaussian variables. Our results can be used to quantitatively compare large margin learning to other learning rules, and to improve the effectiveness of methods that use sample complexity bounds, such as active learning.
* arXiv admin note: text overlap with arXiv:1011.5053
Multivariate Information Bottleneck
Jan 10, 2013The Information bottleneck method is an unsupervised non-parametric data organization technique. Given a joint distribution P(A,B), this method constructs a new variable T that extracts partitions, or clusters, over the values of A that are informative about B. The information bottleneck has already been applied to document classification, gene expression, neural code, and spectral analysis. In this paper, we introduce a general principled framework for multivariate extensions of the information bottleneck method. This allows us to consider multiple systems of data partitions that are inter-related. Our approach utilizes Bayesian networks for specifying the systems of clusters and what information each captures. We show that this construction provides insight about bottleneck variations and enables us to characterize solutions of these variations. We also present a general framework for iterative algorithms for constructing solutions, and apply it to several examples.
Sufficient Dimensionality Reduction with Irrelevant Statistics
Oct 19, 2012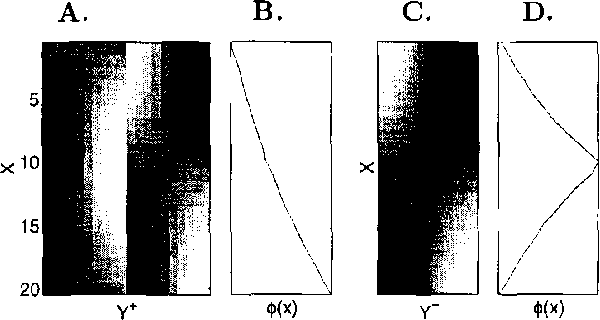
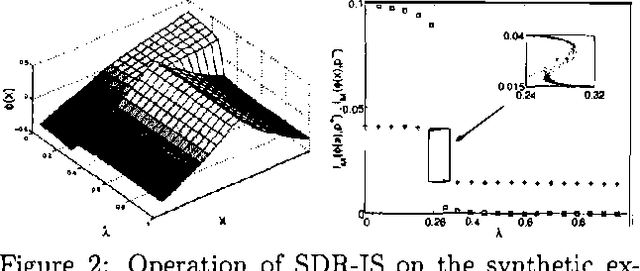

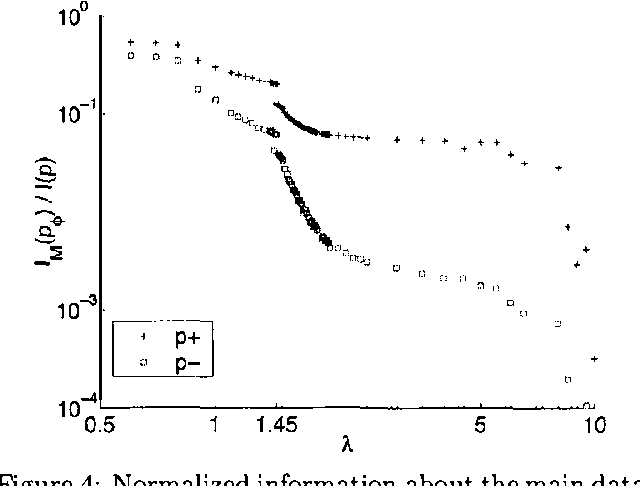
The problem of finding a reduced dimensionality representation of categorical variables while preserving their most relevant characteristics is fundamental for the analysis of complex data. Specifically, given a co-occurrence matrix of two variables, one often seeks a compact representation of one variable which preserves information about the other variable. We have recently introduced ``Sufficient Dimensionality Reduction' [GT-2003], a method that extracts continuous reduced dimensional features whose measurements (i.e., expectation values) capture maximal mutual information among the variables. However, such measurements often capture information that is irrelevant for a given task. Widely known examples are illumination conditions, which are irrelevant as features for face recognition, writing style which is irrelevant as a feature for content classification, and intonation which is irrelevant as a feature for speech recognition. Such irrelevance cannot be deduced apriori, since it depends on the details of the task, and is thus inherently ill defined in the purely unsupervised case. Separating relevant from irrelevant features can be achieved using additional side data that contains such irrelevant structures. This approach was taken in [CT-2002], extending the information bottleneck method, which uses clustering to compress the data. Here we use this side-information framework to identify features whose measurements are maximally informative for the original data set, but carry as little information as possible on a side data set. In statistical terms this can be understood as extracting statistics which are maximally sufficient for the original dataset, while simultaneously maximally ancillary for the side dataset. We formulate this tradeoff as a constrained optimization problem and characterize its solutions. We then derive a gradient descent algorithm for this problem, which is based on the Generalized Iterative Scaling method for finding maximum entropy distributions. The method is demonstrated on synthetic data, as well as on real face recognition datasets, and is shown to outperform standard methods such as oriented PCA.