 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Aug 30, 2024



Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
Insights into performance evaluation of com-pound-protein interaction prediction methods
Jan 28, 2022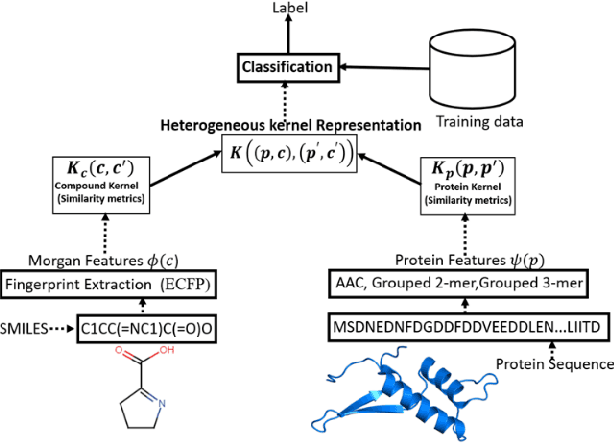
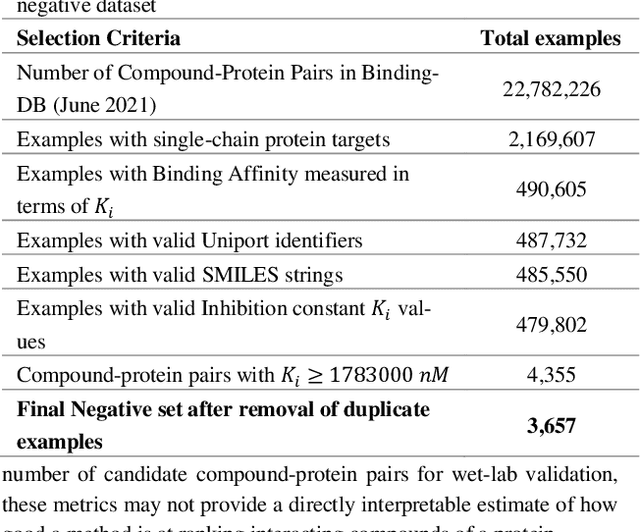
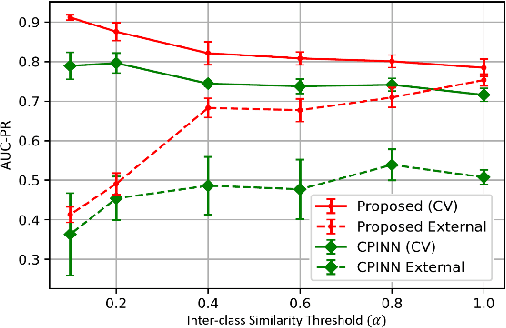
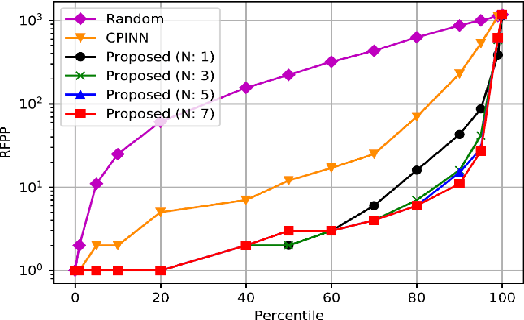
Motivation: Machine learning based prediction of compound-protein interactions (CPIs) is important for drug design, screening and repurposing studies and can improve the efficiency and cost-effectiveness of wet lab assays. Despite the publication of many research papers reporting CPI predictors in the recent years, we have observed a number of fundamental issues in experiment design that lead to over optimistic estimates of model performance. Results: In this paper, we analyze the impact of several important factors affecting generalization perfor-mance of CPI predictors that are overlooked in existing work: 1. Similarity between training and test examples in cross-validation 2. The strategy for generating negative examples, in the absence of experimentally verified negative examples. 3. Choice of evaluation protocols and performance metrics and their alignment with real-world use of CPI predictors in screening large compound libraries. Using both an existing state-of-the-art method (CPI-NN) and a proposed kernel based approach, we have found that assessment of predictive performance of CPI predictors requires careful con-trol over similarity between training and test examples. We also show that random pairing for gen-erating synthetic negative examples for training and performance evaluation results in models with better generalization performance in comparison to more sophisticated strategies used in existing studies. Furthermore, we have found that our kernel based approach, despite its simple design, exceeds the prediction performance of CPI-NN. We have used the proposed model for compound screening of several proteins including SARS-CoV-2 Spike and Human ACE2 proteins and found strong evidence in support of its top hits. Availability: Code and raw experimental results available at https://github.com/adibayaseen/HKRCPI Contact: Fayyaz.minhas@warwick.ac.uk
D-OccNet: Detailed 3D Reconstruction Using Cross-Domain Learning
Apr 28, 2021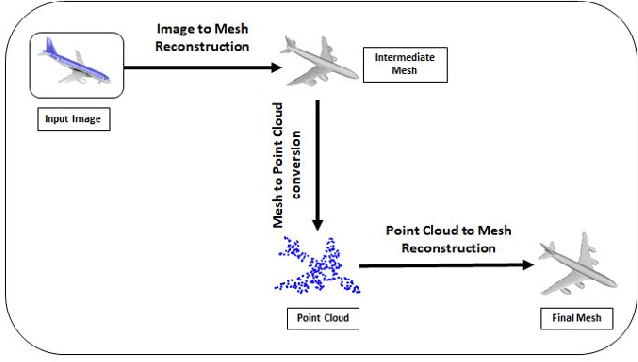
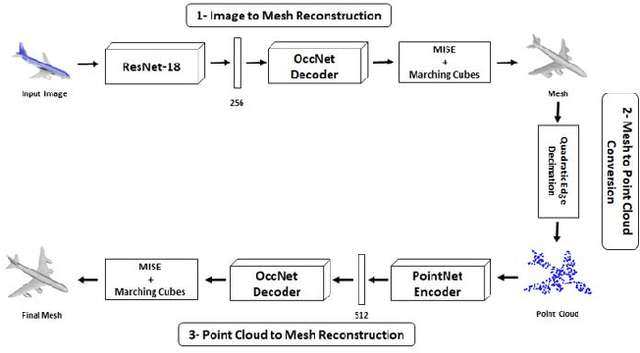
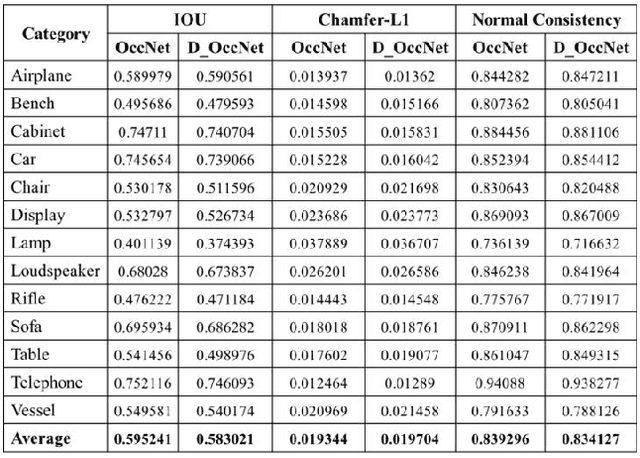

Deep learning based 3D reconstruction of single view 2D image is becoming increasingly popular due to their wide range of real-world applications, but this task is inherently challenging because of the partial observability of an object from a single perspective. Recently, state of the art probability based Occupancy Networks reconstructed 3D surfaces from three different types of input domains: single view 2D image, point cloud and voxel. In this study, we extend the work on Occupancy Networks by exploiting cross-domain learning of image and point cloud domains. Specifically, we first convert the single view 2D image into a simpler point cloud representation, and then reconstruct a 3D surface from it. Our network, the Double Occupancy Network (D-OccNet) outperforms Occupancy Networks in terms of visual quality and details captured in the 3D reconstruction.