 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Causal Effects of Text Interventions Leveraging LLMs
Oct 28, 2024Quantifying the effect of textual interventions in social systems, such as reducing anger in social media posts to see its impact on engagement, poses significant challenges. Direct interventions on real-world systems are often infeasible, necessitating reliance on observational data. Traditional causal inference methods, typically designed for binary or discrete treatments, are inadequate for handling the complex, high-dimensional nature of textual data. This paper addresses these challenges by proposing a novel approach, CausalDANN, to estimate causal effects using text transformations facilitated by large language models (LLMs). Unlike existing methods, our approach accommodates arbitrary textual interventions and leverages text-level classifiers with domain adaptation ability to produce robust effect estimates against domain shifts, even when only the control group is observed. This flexibility in handling various text interventions is a key advancement in causal estimation for textual data, offering opportunities to better understand human behaviors and develop effective policies within social systems.
Capturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks
Nov 16, 2023



In most classification models, it has been assumed to have a single ground truth label for each data point. However, subjective tasks like toxicity classification can lead to genuine disagreement among annotators. In these cases aggregating labels will result in biased labeling and, consequently, biased models that can overlook minority opinions. Previous studies have shed light on the pitfalls of label aggregation and have introduced a handful of practical approaches to tackle this issue. Recently proposed multi-annotator models, which predict labels individually per annotator, are vulnerable to under-determination for annotators with small samples. This problem is especially the case in crowd-sourced datasets. In this work, we propose Annotator Aware Representations for Texts (AART) for subjective classification tasks. We will show the improvement of our method on metrics that assess the performance on capturing annotators' perspectives. Additionally, our approach involves learning representations for annotators, allowing for an exploration of the captured annotation behaviors.
Tighter Prediction Intervals for Causal Outcomes Under Hidden Confounding
Jun 15, 2023



Causal inference of exact individual treatment outcomes in the presence of hidden confounders is rarely possible. Instead, recent work has adapted conformal prediction to produce outcome intervals. Unfortunately this family of methods tends to be overly conservative, sometimes giving uninformative intervals. We introduce an alternative approach termed Caus-Modens, for characterizing causal outcome intervals by modulated ensembles. Motivated from Bayesian statistics and ensembled uncertainty quantification, Caus-Modens gives tighter outcome intervals in practice, measured by the necessary interval size to achieve sufficient coverage on three separate benchmarks. The last benchmark is a novel usage of GPT-4 for observational experiments with unknown but probeable ground truth.
Bounding the Effects of Continuous Treatments for Hidden Confounders
Apr 24, 2022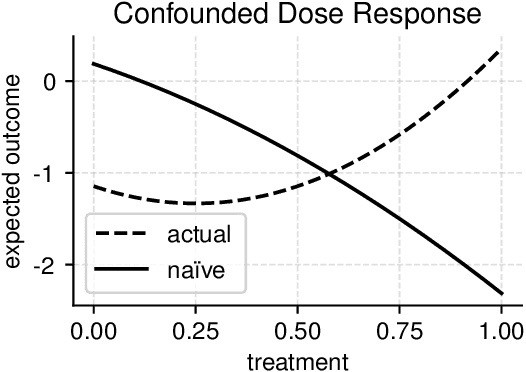
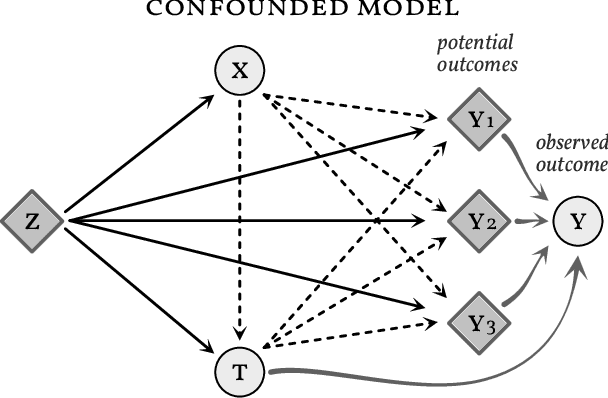
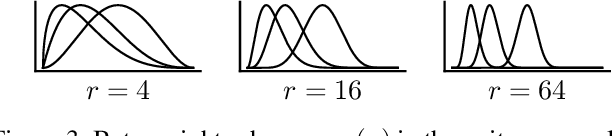
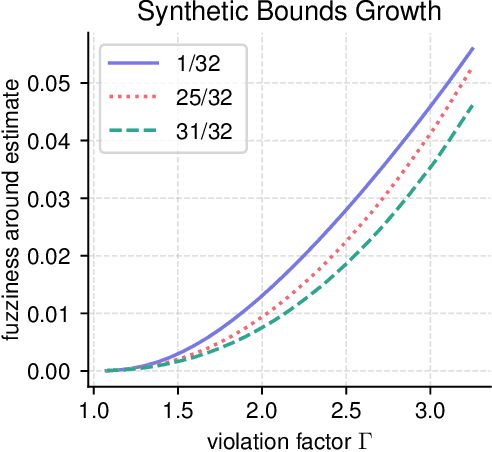
Causal inference involves the disentanglement of effects due to a treatment variable from those of confounders, observed as covariates or not. Since one outcome is ever observed at a time, the problem turns into one of predicting counterfactuals on every individual in the dataset. Observational studies complicate this endeavor by permitting dependencies between the treatment and other variables in the sample. If the covariates influence the propensity of treatment, then one suffers from covariate shift. Should the outcome and the treatment be affected by another variable even after accounting for the covariates, there is also hidden confounding. That is immeasurable by definition. Rather, one must study the worst possible consequences of bounded levels of hidden confounding on downstream decision-making. We explore this problem in the case of continuous treatments. We develop a framework to compute ignorance intervals on the partially identified dose-response curves, which enable us to quantify the susceptibility of our inference to hidden confounders. Our method is supported by simulations as well as empirical tests based on two observational studies.
Latent Embeddings of Point Process Excitations
Jun 02, 2020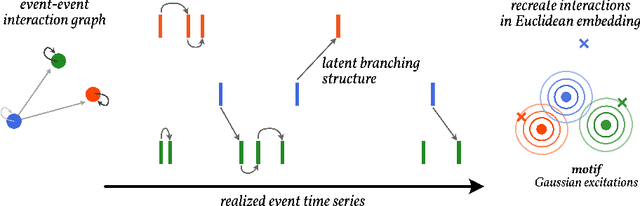
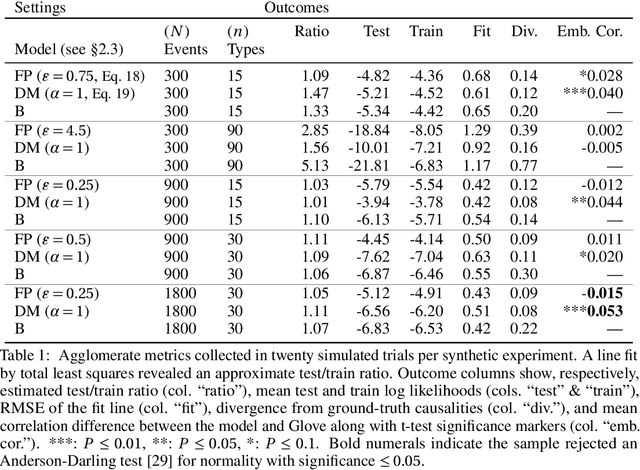

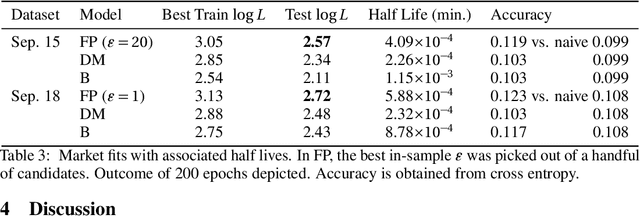
When specific events seem to spur others in their wake, marked Hawkes processes enable us to reckon with their statistics. The underdetermined empirical nature of these event-triggering mechanisms hinders estimation in the multivariate setting. Spatiotemporal applications alleviate this obstacle by allowing relationships to depend only on relative distances in real Euclidean space; we employ the framework as a vessel for embedding arbitrary event types in a new latent space. By performing synthetic experiments on short records as well as an investigation into options markets and pathogens, we demonstrate that learning the embedding alongside a point process model uncovers the coherent, rather than spurious, interactions.