 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen is the majority-vote classifier beneficial?
Jul 24, 2013


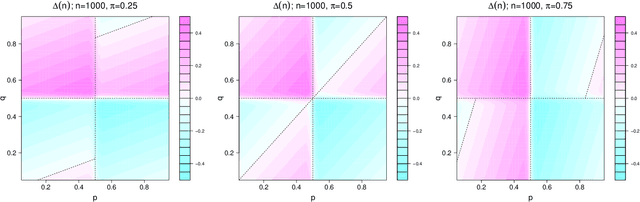
In his seminal work, Schapire (1990) proved that weak classifiers could be improved to achieve arbitrarily high accuracy, but he never implied that a simple majority-vote mechanism could always do the trick. By comparing the asymptotic misclassification error of the majority-vote classifier with the average individual error, we discover an interesting phase-transition phenomenon. For binary classification with equal prior probabilities, our result implies that, for the majority-vote mechanism to work, the collection of weak classifiers must meet the minimum requirement of having an average true positive rate of at least 50% and an average false positive rate of at most 50%.
Content-boosted Matrix Factorization Techniques for Recommender Systems
Jan 04, 2013

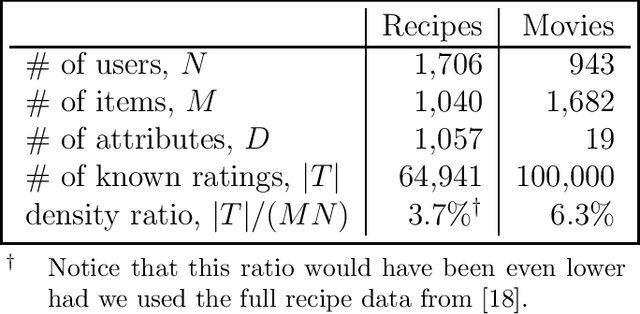
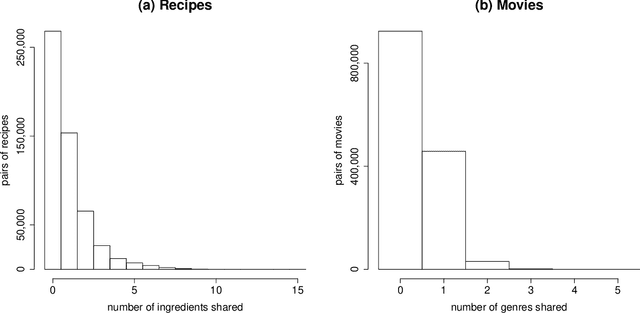
Many businesses are using recommender systems for marketing outreach. Recommendation algorithms can be either based on content or driven by collaborative filtering. We study different ways to incorporate content information directly into the matrix factorization approach of collaborative filtering. These content-boosted matrix factorization algorithms not only improve recommendation accuracy, but also provide useful insights about the contents, as well as make recommendations more easily interpretable.
Stochastic Stepwise Ensembles for Variable Selection
Mar 02, 2011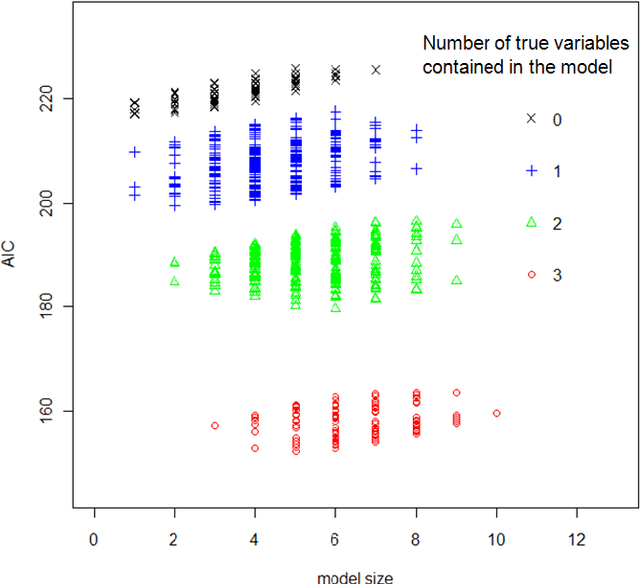
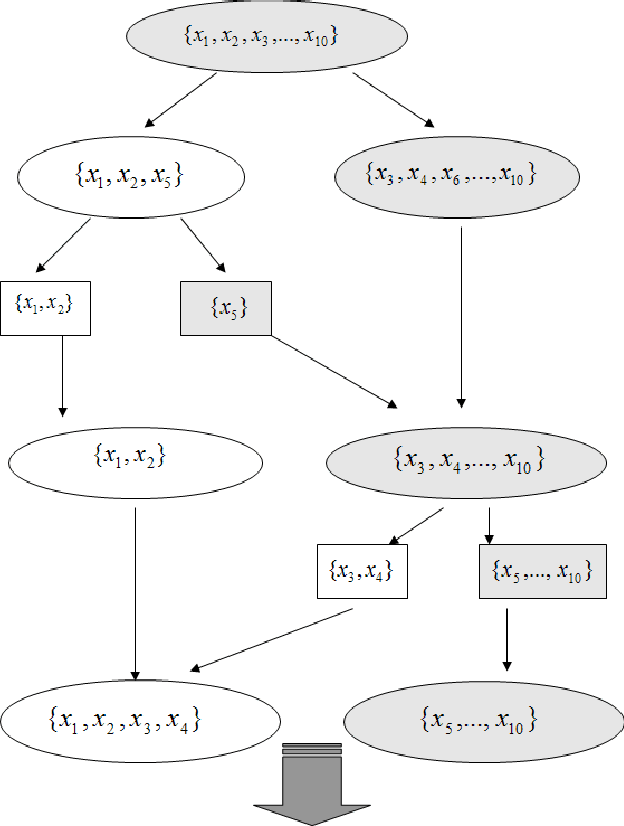
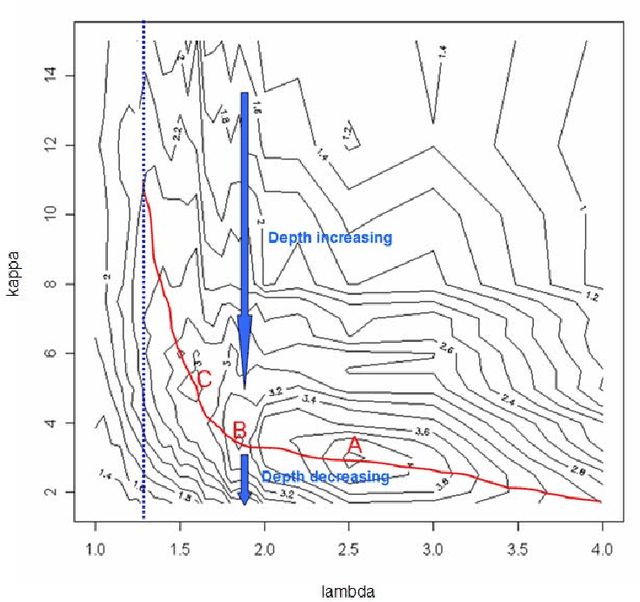

In this article, we advocate the ensemble approach for variable selection. We point out that the stochastic mechanism used to generate the variable-selection ensemble (VSE) must be picked with care. We construct a VSE using a stochastic stepwise algorithm, and compare its performance with numerous state-of-the-art algorithms.
Classifying Network Data with Deep Kernel Machines
Jan 22, 2010
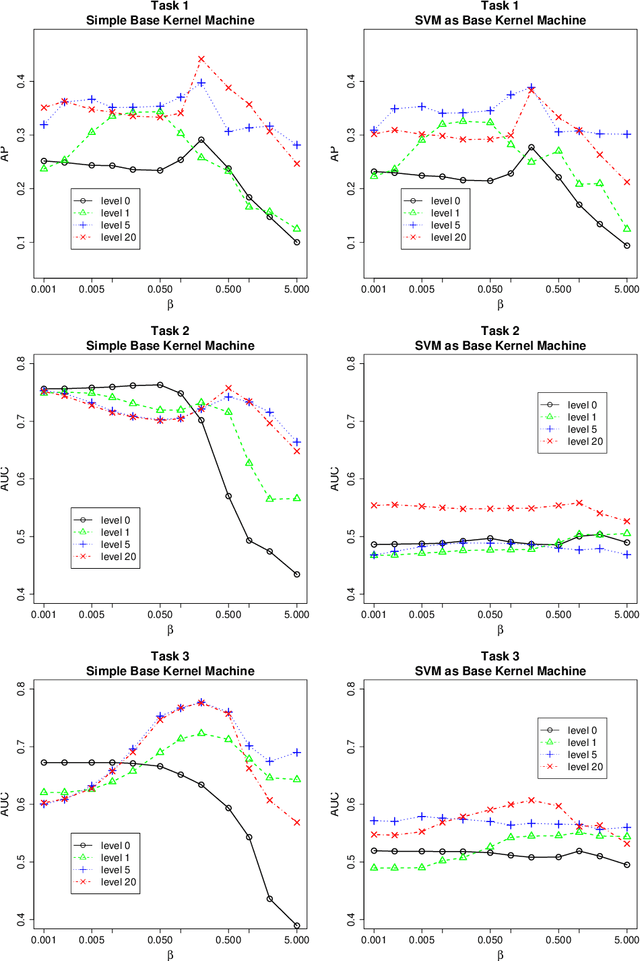
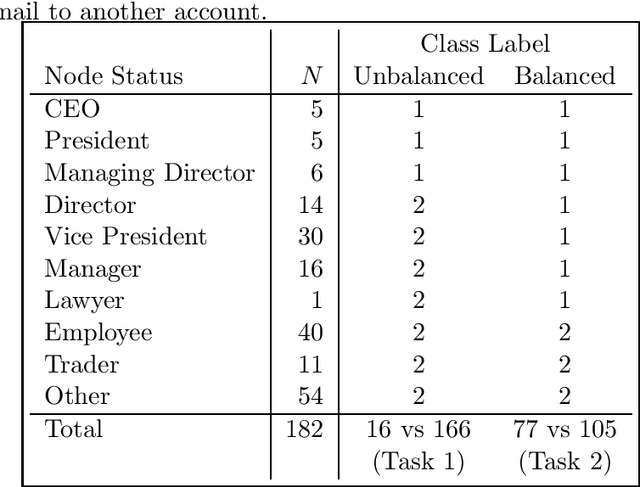
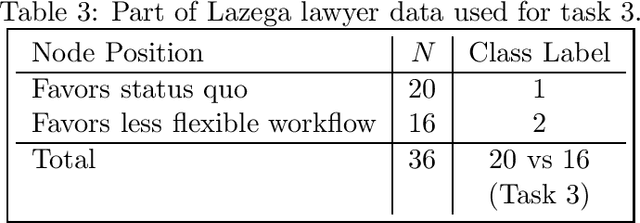
Inspired by a growing interest in analyzing network data, we study the problem of node classification on graphs, focusing on approaches based on kernel machines. Conventionally, kernel machines are linear classifiers in the implicit feature space. We argue that linear classification in the feature space of kernels commonly used for graphs is often not enough to produce good results. When this is the case, one naturally considers nonlinear classifiers in the feature space. We show that repeating this process produces something we call "deep kernel machines." We provide some examples where deep kernel machines can make a big difference in classification performance, and point out some connections to various recent literature on deep architectures in artificial intelligence and machine learning.
On the underestimation of model uncertainty by Bayesian K-nearest neighbors
Apr 08, 2008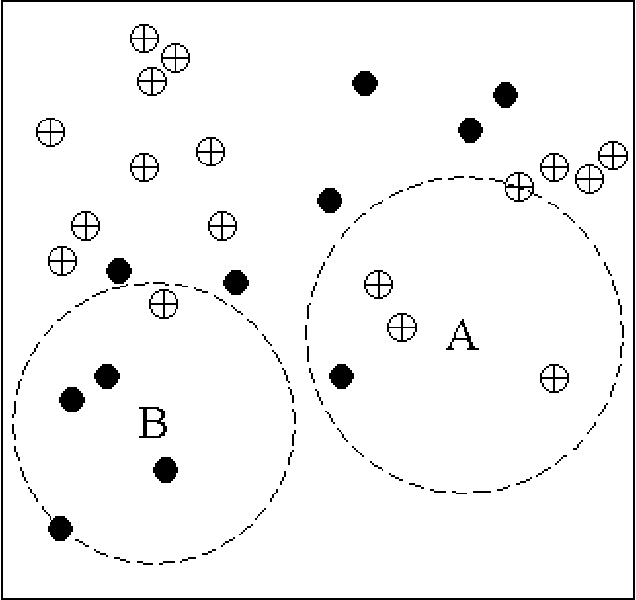
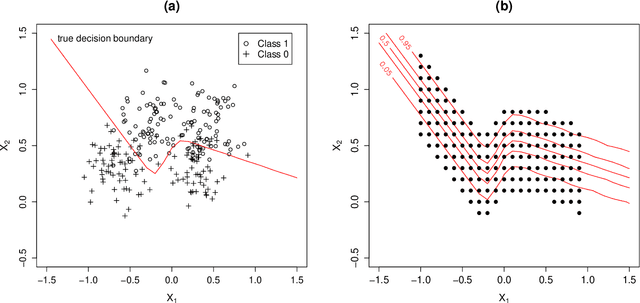
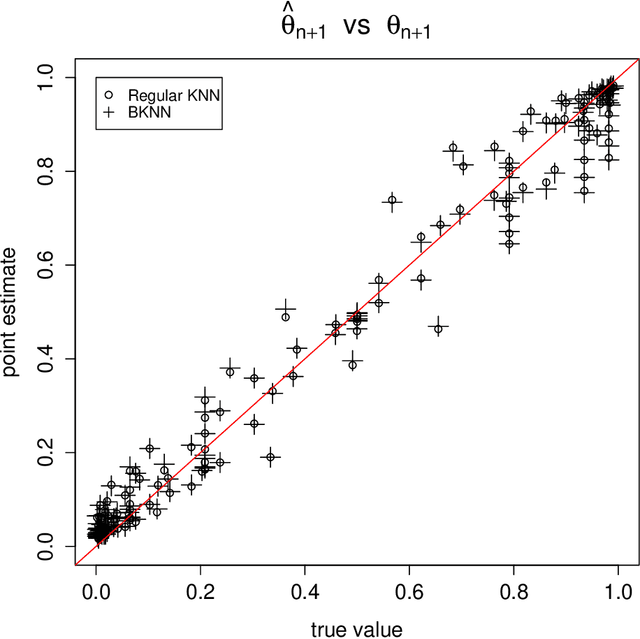
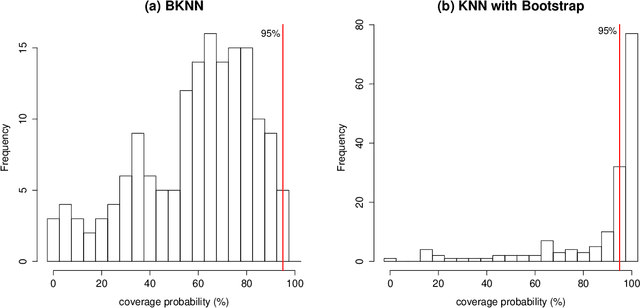
When using the K-nearest neighbors method, one often ignores uncertainty in the choice of K. To account for such uncertainty, Holmes and Adams (2002) proposed a Bayesian framework for K-nearest neighbors (KNN). Their Bayesian KNN (BKNN) approach uses a pseudo-likelihood function, and standard Markov chain Monte Carlo (MCMC) techniques to draw posterior samples. Holmes and Adams (2002) focused on the performance of BKNN in terms of misclassification error but did not assess its ability to quantify uncertainty. We present some evidence to show that BKNN still significantly underestimates model uncertainty.
Kernels and Ensembles: Perspectives on Statistical Learning
Dec 06, 2007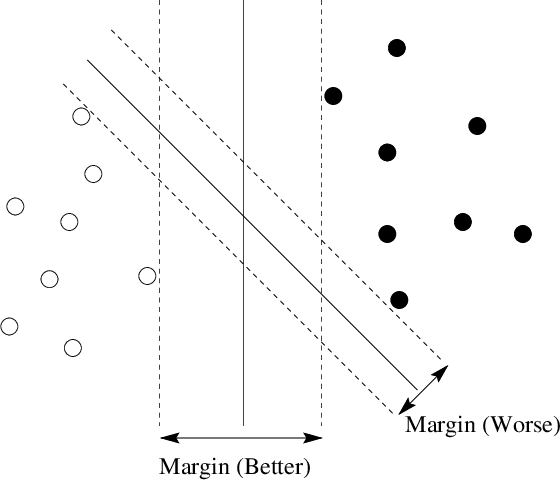


Since their emergence in the 1990's, the support vector machine and the AdaBoost algorithm have spawned a wave of research in statistical machine learning. Much of this new research falls into one of two broad categories: kernel methods and ensemble methods. In this expository article, I discuss the main ideas behind these two types of methods, namely how to transform linear algorithms into nonlinear ones by using kernel functions, and how to make predictions with an ensemble or a collection of models rather than a single model. I also share my personal perspectives on how these ideas have influenced and shaped my own research. In particular, I present two recent algorithms that I have invented with my collaborators: LAGO, a fast kernel algorithm for unbalanced classification and rare target detection; and Darwinian evolution in parallel universes, an ensemble method for variable selection.
* 22 pages; 6 figures; sumitted to The American Statistician